2014-03-22 18:50:50 +01:00
// Copyright 2014 The Gogs Authors. All rights reserved.
2018-11-28 12:26:14 +01:00
// Copyright 2018 The Gitea Authors. All rights reserved.
2022-11-27 19:20:29 +01:00
// SPDX-License-Identifier: MIT
2014-03-22 18:50:50 +01:00
package repo
2014-07-26 08:28:04 +02:00
import (
2017-01-25 03:43:02 +01:00
"bytes"
2022-04-28 13:48:48 +02:00
stdCtx "context"
2014-07-26 08:28:04 +02:00
"errors"
"fmt"
2024-03-02 16:05:07 +01:00
"html/template"
2022-01-21 18:59:26 +01:00
"math/big"
2018-07-17 23:23:58 +02:00
"net/http"
2021-11-16 19:18:25 +01:00
"net/url"
2023-09-07 11:37:47 +02:00
"slices"
2022-09-02 09:58:49 +02:00
"sort"
2017-03-15 02:10:35 +01:00
"strconv"
2014-07-26 08:28:04 +02:00
"strings"
2022-04-07 20:59:56 +02:00
"time"
2014-07-26 08:28:04 +02:00
2022-08-25 04:31:57 +02:00
activities_model "code.gitea.io/gitea/models/activities"
2021-09-24 13:32:56 +02:00
"code.gitea.io/gitea/models/db"
2022-06-12 17:51:54 +02:00
git_model "code.gitea.io/gitea/models/git"
2022-03-31 11:20:39 +02:00
issues_model "code.gitea.io/gitea/models/issues"
2022-03-29 08:29:02 +02:00
"code.gitea.io/gitea/models/organization"
2022-05-11 12:09:36 +02:00
access_model "code.gitea.io/gitea/models/perm/access"
2022-03-29 16:16:31 +02:00
project_model "code.gitea.io/gitea/models/project"
2022-05-07 19:05:52 +02:00
pull_model "code.gitea.io/gitea/models/pull"
2021-11-19 14:39:57 +01:00
repo_model "code.gitea.io/gitea/models/repo"
2021-11-09 20:57:58 +01:00
"code.gitea.io/gitea/models/unit"
2021-11-24 10:49:20 +01:00
user_model "code.gitea.io/gitea/models/user"
2016-11-10 17:24:48 +01:00
"code.gitea.io/gitea/modules/base"
2022-10-12 07:18:26 +02:00
"code.gitea.io/gitea/modules/container"
2024-02-24 23:34:51 +01:00
"code.gitea.io/gitea/modules/emoji"
2019-03-27 10:33:00 +01:00
"code.gitea.io/gitea/modules/git"
2019-02-21 01:54:05 +01:00
issue_indexer "code.gitea.io/gitea/modules/indexer/issues"
2022-09-02 09:58:49 +02:00
issue_template "code.gitea.io/gitea/modules/issue/template"
2016-11-10 17:24:48 +01:00
"code.gitea.io/gitea/modules/log"
2019-12-07 05:21:18 +01:00
"code.gitea.io/gitea/modules/markup"
2017-09-21 07:20:14 +02:00
"code.gitea.io/gitea/modules/markup/markdown"
2024-02-29 19:52:49 +01:00
"code.gitea.io/gitea/modules/optional"
2023-05-08 08:39:32 +02:00
repo_module "code.gitea.io/gitea/modules/repository"
2016-11-10 17:24:48 +01:00
"code.gitea.io/gitea/modules/setting"
2019-06-06 02:37:45 +02:00
api "code.gitea.io/gitea/modules/structs"
2024-03-01 08:11:51 +01:00
"code.gitea.io/gitea/modules/templates"
2022-04-01 10:47:50 +02:00
"code.gitea.io/gitea/modules/templates/vars"
2022-04-07 20:59:56 +02:00
"code.gitea.io/gitea/modules/timeutil"
2017-01-25 03:43:02 +01:00
"code.gitea.io/gitea/modules/util"
2021-01-26 16:36:53 +01:00
"code.gitea.io/gitea/modules/web"
2022-09-02 09:58:49 +02:00
"code.gitea.io/gitea/routers/utils"
2024-09-12 05:53:40 +02:00
shared_user "code.gitea.io/gitea/routers/web/shared/user"
2021-12-10 09:14:24 +01:00
asymkey_service "code.gitea.io/gitea/services/asymkey"
2024-02-27 08:12:22 +01:00
"code.gitea.io/gitea/services/context"
"code.gitea.io/gitea/services/context/upload"
2022-12-29 03:57:15 +01:00
"code.gitea.io/gitea/services/convert"
2021-04-06 21:44:05 +02:00
"code.gitea.io/gitea/services/forms"
2019-09-30 15:50:44 +02:00
issue_service "code.gitea.io/gitea/services/issue"
2019-12-07 03:44:10 +01:00
pull_service "code.gitea.io/gitea/services/pull"
2022-06-06 10:01:49 +02:00
repo_service "code.gitea.io/gitea/services/repository"
2024-03-04 09:16:03 +01:00
user_service "code.gitea.io/gitea/services/user"
2014-07-26 08:28:04 +02:00
)
const (
2019-10-15 14:19:32 +02:00
tplAttachment base . TplName = "repo/issue/view_content/attachments"
2020-09-11 16:48:39 +02:00
tplIssues base . TplName = "repo/issue/list"
tplIssueNew base . TplName = "repo/issue/new"
tplIssueChoose base . TplName = "repo/issue/choose"
tplIssueView base . TplName = "repo/issue/view"
2014-07-26 08:28:04 +02:00
2017-12-04 00:14:26 +01:00
tplReactions base . TplName = "repo/issue/view_content/reactions"
2020-09-11 16:48:39 +02:00
issueTemplateKey = "IssueTemplate"
issueTemplateTitleKey = "IssueTemplateTitle"
2014-07-26 08:28:04 +02:00
)
2022-01-20 18:46:10 +01:00
// IssueTemplateCandidates issue templates
var IssueTemplateCandidates = [ ] string {
"ISSUE_TEMPLATE.md" ,
2022-09-02 09:58:49 +02:00
"ISSUE_TEMPLATE.yaml" ,
"ISSUE_TEMPLATE.yml" ,
2022-01-20 18:46:10 +01:00
"issue_template.md" ,
2022-09-02 09:58:49 +02:00
"issue_template.yaml" ,
"issue_template.yml" ,
2022-01-20 18:46:10 +01:00
".gitea/ISSUE_TEMPLATE.md" ,
2022-09-02 09:58:49 +02:00
".gitea/ISSUE_TEMPLATE.yaml" ,
".gitea/ISSUE_TEMPLATE.yml" ,
".gitea/issue_template.md" ,
".gitea/issue_template.yaml" ,
2022-09-09 05:22:33 +02:00
".gitea/issue_template.yml" ,
2022-01-20 18:46:10 +01:00
".github/ISSUE_TEMPLATE.md" ,
2022-09-02 09:58:49 +02:00
".github/ISSUE_TEMPLATE.yaml" ,
".github/ISSUE_TEMPLATE.yml" ,
2022-01-20 18:46:10 +01:00
".github/issue_template.md" ,
2022-09-02 09:58:49 +02:00
".github/issue_template.yaml" ,
".github/issue_template.yml" ,
2022-01-20 18:46:10 +01:00
}
2014-07-26 08:28:04 +02:00
2019-02-18 21:55:04 +01:00
// MustAllowUserComment checks to make sure if an issue is locked.
// If locked and user has permissions to write to the repository,
// then the comment is allowed, else it is blocked
func MustAllowUserComment ( ctx * context . Context ) {
issue := GetActionIssue ( ctx )
if ctx . Written ( ) {
return
}
2022-03-22 08:03:22 +01:00
if issue . IsLocked && ! ctx . Repo . CanWriteIssuesOrPulls ( issue . IsPull ) && ! ctx . Doer . IsAdmin {
2019-02-18 21:55:04 +01:00
ctx . Flash . Error ( ctx . Tr ( "repo.issues.comment_on_locked" ) )
2023-02-11 07:34:11 +01:00
ctx . Redirect ( issue . Link ( ) )
2019-02-18 21:55:04 +01:00
return
}
}
2016-11-24 08:04:31 +01:00
// MustEnableIssues check if repository enable internal issues
2016-03-11 17:56:52 +01:00
func MustEnableIssues ( ctx * context . Context ) {
2021-11-09 20:57:58 +01:00
if ! ctx . Repo . CanRead ( unit . TypeIssues ) &&
! ctx . Repo . CanRead ( unit . TypeExternalTracker ) {
2018-01-10 22:34:17 +01:00
ctx . NotFound ( "MustEnableIssues" , nil )
2016-03-07 05:57:46 +01:00
return
2015-12-05 03:30:33 +01:00
}
2016-11-04 09:06:54 +01:00
2022-12-10 03:46:31 +01:00
unit , err := ctx . Repo . Repository . GetUnit ( ctx , unit . TypeExternalTracker )
2017-02-04 16:53:46 +01:00
if err == nil {
ctx . Redirect ( unit . ExternalTrackerConfig ( ) . ExternalTrackerURL )
2016-11-04 09:06:54 +01:00
return
}
2015-12-05 03:30:33 +01:00
}
2018-11-28 12:26:14 +01:00
// MustAllowPulls check if repository enable pull requests and user have right to do that
2016-03-11 17:56:52 +01:00
func MustAllowPulls ( ctx * context . Context ) {
2021-11-09 20:57:58 +01:00
if ! ctx . Repo . Repository . CanEnablePulls ( ) || ! ctx . Repo . CanRead ( unit . TypePullRequests ) {
2018-01-10 22:34:17 +01:00
ctx . NotFound ( "MustAllowPulls" , nil )
2016-03-07 05:57:46 +01:00
return
2015-12-05 03:30:33 +01:00
}
2015-12-20 04:07:06 +01:00
2016-03-07 05:57:46 +01:00
// User can send pull request if owns a forked repository.
2023-09-14 19:09:32 +02:00
if ctx . IsSigned && repo_model . HasForkedRepo ( ctx , ctx . Doer . ID , ctx . Repo . Repository . ID ) {
2016-03-07 05:57:46 +01:00
ctx . Repo . PullRequest . Allowed = true
2022-03-22 08:03:22 +01:00
ctx . Repo . PullRequest . HeadInfoSubURL = url . PathEscape ( ctx . Doer . Name ) + ":" + util . PathEscapeSegments ( ctx . Repo . BranchName )
2016-03-07 05:57:46 +01:00
}
2015-12-05 03:30:33 +01:00
}
2024-03-02 16:42:31 +01:00
func issues ( ctx * context . Context , milestoneID , projectID int64 , isPullOption optional . Option [ bool ] ) {
2018-11-29 02:46:30 +01:00
var err error
2021-08-11 02:31:13 +02:00
viewType := ctx . FormString ( "type" )
sortType := ctx . FormString ( "sort" )
2023-02-25 03:55:50 +01:00
types := [ ] string { "all" , "your_repositories" , "assigned" , "created_by" , "mentioned" , "review_requested" , "reviewed_by" }
Improve utils of slices (#22379)
- Move the file `compare.go` and `slice.go` to `slice.go`.
- Fix `ExistsInSlice`, it's buggy
- It uses `sort.Search`, so it assumes that the input slice is sorted.
- It passes `func(i int) bool { return slice[i] == target })` to
`sort.Search`, that's incorrect, check the doc of `sort.Search`.
- Conbine `IsInt64InSlice(int64, []int64)` and `ExistsInSlice(string,
[]string)` to `SliceContains[T]([]T, T)`.
- Conbine `IsSliceInt64Eq([]int64, []int64)` and `IsEqualSlice([]string,
[]string)` to `SliceSortedEqual[T]([]T, T)`.
- Add `SliceEqual[T]([]T, T)` as a distinction from
`SliceSortedEqual[T]([]T, T)`.
- Redesign `RemoveIDFromList([]int64, int64) ([]int64, bool)` to
`SliceRemoveAll[T]([]T, T) []T`.
- Add `SliceContainsFunc[T]([]T, func(T) bool)` and
`SliceRemoveAllFunc[T]([]T, func(T) bool)` for general use.
- Add comments to explain why not `golang.org/x/exp/slices`.
- Add unit tests.
2023-01-11 06:31:16 +01:00
if ! util . SliceContainsString ( types , viewType , true ) {
2014-07-26 08:28:04 +02:00
viewType = "all"
}
2015-08-15 06:07:08 +02:00
var (
2021-07-29 03:42:15 +02:00
assigneeID = ctx . FormInt64 ( "assignee" )
2022-08-08 22:03:58 +02:00
posterID = ctx . FormInt64 ( "poster" )
2021-01-17 17:34:19 +01:00
mentionedID int64
reviewRequestedID int64
2023-02-25 03:55:50 +01:00
reviewedID int64
2015-08-15 06:07:08 +02:00
)
2014-07-26 08:28:04 +02:00
2017-06-15 05:09:03 +02:00
if ctx . IsSigned {
switch viewType {
case "created_by" :
2022-03-22 08:03:22 +01:00
posterID = ctx . Doer . ID
2017-06-15 05:09:03 +02:00
case "mentioned" :
2022-03-22 08:03:22 +01:00
mentionedID = ctx . Doer . ID
2020-11-19 22:39:55 +01:00
case "assigned" :
2022-03-22 08:03:22 +01:00
assigneeID = ctx . Doer . ID
2021-01-17 17:34:19 +01:00
case "review_requested" :
2022-03-22 08:03:22 +01:00
reviewRequestedID = ctx . Doer . ID
2023-02-25 03:55:50 +01:00
case "reviewed_by" :
reviewedID = ctx . Doer . ID
2017-06-15 05:09:03 +02:00
}
}
2015-07-24 20:52:25 +02:00
repo := ctx . Repo . Repository
2019-01-23 05:10:38 +01:00
var labelIDs [ ] int64
2023-05-17 11:21:35 +02:00
// 1,-2 means including label 1 and excluding label 2
// 0 means issues with no label
// blank means labels will not be filtered for issues
2021-08-11 02:31:13 +02:00
selectLabels := ctx . FormString ( "labels" )
2023-07-26 15:00:50 +02:00
if selectLabels == "" {
ctx . Data [ "AllLabels" ] = true
} else if selectLabels == "0" {
ctx . Data [ "NoLabel" ] = true
2023-08-17 15:19:24 +02:00
}
if len ( selectLabels ) > 0 {
2019-01-23 05:10:38 +01:00
labelIDs , err = base . StringsToInt64s ( strings . Split ( selectLabels , "," ) )
if err != nil {
2024-03-21 16:07:35 +01:00
ctx . Flash . Error ( ctx . Tr ( "invalid_data" , selectLabels ) , true )
2019-01-23 05:10:38 +01:00
}
}
2016-12-24 11:33:21 +01:00
2021-08-11 02:31:13 +02:00
keyword := strings . Trim ( ctx . FormString ( "q" ) , " " )
2017-01-25 03:43:02 +01:00
if bytes . Contains ( [ ] byte ( keyword ) , [ ] byte { 0x00 } ) {
keyword = ""
}
2023-06-08 10:08:35 +02:00
var mileIDs [ ] int64
if milestoneID > 0 || milestoneID == db . NoConditionID { // -1 to get those issues which have no any milestone assigned
mileIDs = [ ] int64 { milestoneID }
}
2022-06-13 11:37:59 +02:00
var issueStats * issues_model . IssueStats
2023-10-19 16:08:31 +02:00
statsOpts := & issues_model . IssuesOptions {
RepoIDs : [ ] int64 { repo . ID } ,
LabelIDs : labelIDs ,
MilestoneIDs : mileIDs ,
ProjectID : projectID ,
AssigneeID : assigneeID ,
MentionedID : mentionedID ,
PosterID : posterID ,
ReviewRequestedID : reviewRequestedID ,
ReviewedID : reviewedID ,
IsPull : isPullOption ,
IssueIDs : nil ,
}
if keyword != "" {
allIssueIDs , err := issueIDsFromSearch ( ctx , keyword , statsOpts )
if err != nil {
if issue_indexer . IsAvailable ( ctx ) {
ctx . ServerError ( "issueIDsFromSearch" , err )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
return
}
2023-10-19 16:08:31 +02:00
ctx . Data [ "IssueIndexerUnavailable" ] = true
return
2017-01-25 03:43:02 +01:00
}
2023-10-19 16:08:31 +02:00
statsOpts . IssueIDs = allIssueIDs
}
if keyword != "" && len ( statsOpts . IssueIDs ) == 0 {
// So it did search with the keyword, but no issue found.
// Just set issueStats to empty.
issueStats = & issues_model . IssueStats { }
} else {
// So it did search with the keyword, and found some issues. It needs to get issueStats of these issues.
// Or the keyword is empty, so it doesn't need issueIDs as filter, just get issueStats with statsOpts.
issueStats , err = issues_model . GetIssueStats ( ctx , statsOpts )
if err != nil {
ctx . ServerError ( "GetIssueStats" , err )
return
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
2016-12-24 11:33:21 +01:00
}
2020-07-09 23:13:06 +02:00
2024-03-02 16:42:31 +01:00
var isShowClosed optional . Option [ bool ]
2024-01-15 16:07:22 +01:00
switch ctx . FormString ( "state" ) {
case "closed" :
2024-03-02 16:42:31 +01:00
isShowClosed = optional . Some ( true )
2024-01-15 16:07:22 +01:00
case "all" :
2024-03-02 16:42:31 +01:00
isShowClosed = optional . None [ bool ] ( )
2024-01-15 16:07:22 +01:00
default :
2024-03-02 16:42:31 +01:00
isShowClosed = optional . Some ( false )
2024-01-15 16:07:22 +01:00
}
// if there are closed issues and no open issues, default to showing all issues
2021-08-11 02:31:13 +02:00
if len ( ctx . FormString ( "state" ) ) == 0 && issueStats . OpenCount == 0 && issueStats . ClosedCount != 0 {
2024-03-02 16:42:31 +01:00
isShowClosed = optional . None [ bool ] ( )
2020-07-09 23:13:06 +02:00
}
2023-10-19 16:08:31 +02:00
if repo . IsTimetrackerEnabled ( ctx ) {
totalTrackedTime , err := issues_model . GetIssueTotalTrackedTime ( ctx , statsOpts , isShowClosed )
if err != nil {
ctx . ServerError ( "GetIssueTotalTrackedTime" , err )
return
}
ctx . Data [ "TotalTrackedTime" ] = totalTrackedTime
}
2023-10-18 02:03:42 +02:00
archived := ctx . FormBool ( "archived" )
2021-07-29 03:42:15 +02:00
page := ctx . FormInt ( "page" )
2015-07-24 10:42:47 +02:00
if page <= 1 {
page = 1
}
2015-07-27 21:14:37 +02:00
var total int
2024-03-02 16:42:31 +01:00
switch {
case isShowClosed . Value ( ) :
2015-07-27 21:14:37 +02:00
total = int ( issueStats . ClosedCount )
2024-03-02 16:42:31 +01:00
case ! isShowClosed . Has ( ) :
2024-01-15 16:07:22 +01:00
total = int ( issueStats . OpenCount + issueStats . ClosedCount )
default :
total = int ( issueStats . OpenCount )
2015-07-24 10:42:47 +02:00
}
2019-04-20 06:15:19 +02:00
pager := context . NewPagination ( total , setting . UI . IssuePagingNum , page , 5 )
2014-07-26 08:28:04 +02:00
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
var issues issues_model . IssueList
{
ids , err := issueIDsFromSearch ( ctx , keyword , & issues_model . IssuesOptions {
Paginator : & db . ListOptions {
2020-01-24 20:00:29 +01:00
Page : pager . Paginater . Current ( ) ,
PageSize : setting . UI . IssuePagingNum ,
} ,
2023-05-19 16:17:48 +02:00
RepoIDs : [ ] int64 { repo . ID } ,
2021-01-17 17:34:19 +01:00
AssigneeID : assigneeID ,
PosterID : posterID ,
MentionedID : mentionedID ,
ReviewRequestedID : reviewRequestedID ,
2023-02-25 03:55:50 +01:00
ReviewedID : reviewedID ,
2021-01-17 17:34:19 +01:00
MilestoneIDs : mileIDs ,
ProjectID : projectID ,
2024-01-15 16:07:22 +01:00
IsClosed : isShowClosed ,
2021-01-17 17:34:19 +01:00
IsPull : isPullOption ,
LabelIDs : labelIDs ,
SortType : sortType ,
2016-12-24 11:33:21 +01:00
} )
if err != nil {
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
if issue_indexer . IsAvailable ( ctx ) {
ctx . ServerError ( "issueIDsFromSearch" , err )
return
}
ctx . Data [ "IssueIndexerUnavailable" ] = true
return
}
issues , err = issues_model . GetIssuesByIDs ( ctx , ids , true )
if err != nil {
ctx . ServerError ( "GetIssuesByIDs" , err )
2016-12-24 11:33:21 +01:00
return
}
2014-07-26 08:28:04 +02:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
approvalCounts , err := issues . GetApprovalCounts ( ctx )
2020-03-06 04:44:06 +01:00
if err != nil {
ctx . ServerError ( "ApprovalCounts" , err )
return
}
2024-03-12 08:23:44 +01:00
if ctx . IsSigned {
if err := issues . LoadIsRead ( ctx , ctx . Doer . ID ) ; err != nil {
ctx . ServerError ( "LoadIsRead" , err )
2017-02-03 08:22:39 +01:00
return
2014-07-26 08:28:04 +02:00
}
2024-03-12 08:23:44 +01:00
} else {
for i := range issues {
issues [ i ] . IsRead = true
}
2021-04-15 19:34:43 +02:00
}
2019-04-02 21:54:29 +02:00
2022-04-27 00:40:01 +02:00
commitStatuses , lastStatus , err := pull_service . GetIssuesAllCommitStatus ( ctx , issues )
2021-04-15 19:34:43 +02:00
if err != nil {
2022-04-27 00:40:01 +02:00
ctx . ServerError ( "GetIssuesAllCommitStatus" , err )
2021-04-15 19:34:43 +02:00
return
2014-07-26 08:28:04 +02:00
}
2024-07-28 17:11:40 +02:00
if ! ctx . Repo . CanRead ( unit . TypeActions ) {
for key := range commitStatuses {
git_model . CommitStatusesHideActionsURL ( ctx , commitStatuses [ key ] )
}
}
2019-04-02 21:54:29 +02:00
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
if err := issues . LoadAttributes ( ctx ) ; err != nil {
ctx . ServerError ( "issues.LoadAttributes" , err )
return
}
2015-08-05 14:23:08 +02:00
ctx . Data [ "Issues" ] = issues
2022-04-27 00:40:01 +02:00
ctx . Data [ "CommitLastStatus" ] = lastStatus
ctx . Data [ "CommitStatuses" ] = commitStatuses
2015-08-05 14:23:08 +02:00
2018-11-29 02:46:30 +01:00
// Get assignees.
2023-04-07 02:11:02 +02:00
assigneeUsers , err := repo_model . GetRepoAssignees ( ctx , repo )
2015-08-05 14:23:08 +02:00
if err != nil {
2023-04-07 02:11:02 +02:00
ctx . ServerError ( "GetRepoAssignees" , err )
2022-08-08 22:03:58 +02:00
return
}
2024-09-12 05:53:40 +02:00
ctx . Data [ "Assignees" ] = shared_user . MakeSelfOnTop ( ctx . Doer , assigneeUsers )
2022-08-08 22:03:58 +02:00
2020-12-21 16:39:28 +01:00
handleTeamMentions ( ctx )
if ctx . Written ( ) {
return
}
2022-06-13 11:37:59 +02:00
labels , err := issues_model . GetLabelsByRepoID ( ctx , repo . ID , "" , db . ListOptions { } )
2015-08-15 05:24:41 +02:00
if err != nil {
2018-11-29 02:46:30 +01:00
ctx . ServerError ( "GetLabelsByRepoID" , err )
2015-08-15 05:24:41 +02:00
return
}
Add Organization Wide Labels (#10814)
* Add organization wide labels
Implement organization wide labels similar to organization wide
webhooks. This lets you create individual labels for organizations that can be used
for all repos under that organization (so being able to reuse the same
label across multiple repos).
This makes it possible for small organizations with many repos to use
labels effectively.
Fixes #7406
* Add migration
* remove comments
* fix tests
* Update options/locale/locale_en-US.ini
Removed unused translation string
* show org labels in issue search label filter
* Use more clear var name
* rename migration after merge from master
* comment typo
* update migration again after rebase with master
* check for orgID <=0 per guillep2k review
* fmt
* Apply suggestions from code review
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* remove unused code
* Make sure RepoID is 0 when searching orgID per code review
* more changes/code review requests
* More descriptive translation var per code review
* func description/delete comment when issue label deleted instead of hiding it
* remove comment
* only use issues in that repo when calculating number of open issues for org label on repo label page
* Add integration test for IssuesSearch API with labels
* remove unused function
* Update models/issue_label.go
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* Use subquery in GetLabelIDsInReposByNames
* Fix tests to use correct orgID
* fix more tests
* IssuesSearch api now uses new BuildLabelNamesIssueIDsCondition. Add a few more tests as well
* update comment for clarity
* Revert previous code change now that we can use the new BuildLabelNamesIssueIDsCondition
* Don't sort repos by date in IssuesSearch API
After much debugging I've found a strange issue where in some cases MySQL will return a different result than other enigines if a query is sorted by a null collumn. For example with our integration test data where we don't set updated_unix in repository fixtures:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 45
Returns different results for MySQL than other engines. However, the similar query:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 30
Returns the same results.
This causes integration tests to fail on MySQL in certain cases but would never show up in a real installation. Since this API call always returns issues based on the optionally provided repo_priority_id or the issueID itself, there is no change to results by changing the repo sorting method used to get ids earlier in the function.
* linter is back!
* code review
* remove now unused option
* Fix newline at end of files
* more unused code
* update to master
* check for matching ids before query
* Update models/issue_label.go
Co-Authored-By: 6543 <6543@obermui.de>
* Update models/issue_label.go
* update comments
* Update routers/org/setting.go
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: guillep2k <18600385+guillep2k@users.noreply.github.com>
Co-authored-by: 6543 <6543@obermui.de>
2020-04-01 06:14:46 +02:00
if repo . Owner . IsOrganization ( ) {
2022-06-13 11:37:59 +02:00
orgLabels , err := issues_model . GetLabelsByOrgID ( ctx , repo . Owner . ID , ctx . FormString ( "sort" ) , db . ListOptions { } )
Add Organization Wide Labels (#10814)
* Add organization wide labels
Implement organization wide labels similar to organization wide
webhooks. This lets you create individual labels for organizations that can be used
for all repos under that organization (so being able to reuse the same
label across multiple repos).
This makes it possible for small organizations with many repos to use
labels effectively.
Fixes #7406
* Add migration
* remove comments
* fix tests
* Update options/locale/locale_en-US.ini
Removed unused translation string
* show org labels in issue search label filter
* Use more clear var name
* rename migration after merge from master
* comment typo
* update migration again after rebase with master
* check for orgID <=0 per guillep2k review
* fmt
* Apply suggestions from code review
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* remove unused code
* Make sure RepoID is 0 when searching orgID per code review
* more changes/code review requests
* More descriptive translation var per code review
* func description/delete comment when issue label deleted instead of hiding it
* remove comment
* only use issues in that repo when calculating number of open issues for org label on repo label page
* Add integration test for IssuesSearch API with labels
* remove unused function
* Update models/issue_label.go
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* Use subquery in GetLabelIDsInReposByNames
* Fix tests to use correct orgID
* fix more tests
* IssuesSearch api now uses new BuildLabelNamesIssueIDsCondition. Add a few more tests as well
* update comment for clarity
* Revert previous code change now that we can use the new BuildLabelNamesIssueIDsCondition
* Don't sort repos by date in IssuesSearch API
After much debugging I've found a strange issue where in some cases MySQL will return a different result than other enigines if a query is sorted by a null collumn. For example with our integration test data where we don't set updated_unix in repository fixtures:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 45
Returns different results for MySQL than other engines. However, the similar query:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 30
Returns the same results.
This causes integration tests to fail on MySQL in certain cases but would never show up in a real installation. Since this API call always returns issues based on the optionally provided repo_priority_id or the issueID itself, there is no change to results by changing the repo sorting method used to get ids earlier in the function.
* linter is back!
* code review
* remove now unused option
* Fix newline at end of files
* more unused code
* update to master
* check for matching ids before query
* Update models/issue_label.go
Co-Authored-By: 6543 <6543@obermui.de>
* Update models/issue_label.go
* update comments
* Update routers/org/setting.go
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: guillep2k <18600385+guillep2k@users.noreply.github.com>
Co-authored-by: 6543 <6543@obermui.de>
2020-04-01 06:14:46 +02:00
if err != nil {
ctx . ServerError ( "GetLabelsByOrgID" , err )
return
}
ctx . Data [ "OrgLabels" ] = orgLabels
labels = append ( labels , orgLabels ... )
}
Scoped labels (#22585)
Add a new "exclusive" option per label. This makes it so that when the
label is named `scope/name`, no other label with the same `scope/`
prefix can be set on an issue.
The scope is determined by the last occurence of `/`, so for example
`scope/alpha/name` and `scope/beta/name` are considered to be in
different scopes and can coexist.
Exclusive scopes are not enforced by any database rules, however they
are enforced when editing labels at the models level, automatically
removing any existing labels in the same scope when either attaching a
new label or replacing all labels.
In menus use a circle instead of checkbox to indicate they function as
radio buttons per scope. Issue filtering by label ensures that only a
single scoped label is selected at a time. Clicking with alt key can be
used to remove a scoped label, both when editing individual issues and
batch editing.
Label rendering refactor for consistency and code simplification:
* Labels now consistently have the same shape, emojis and tooltips
everywhere. This includes the label list and label assignment menus.
* In label list, show description below label same as label menus.
* Don't use exactly black/white text colors to look a bit nicer.
* Simplify text color computation. There is no point computing luminance
in linear color space, as this is a perceptual problem and sRGB is
closer to perceptually linear.
* Increase height of label assignment menus to show more labels. Showing
only 3-4 labels at a time leads to a lot of scrolling.
* Render all labels with a new RenderLabel template helper function.
Label creation and editing in multiline modal menu:
* Change label creation to open a modal menu like label editing.
* Change menu layout to place name, description and colors on separate
lines.
* Don't color cancel button red in label editing modal menu.
* Align text to the left in model menu for better readability and
consistent with settings layout elsewhere.
Custom exclusive scoped label rendering:
* Display scoped label prefix and suffix with slightly darker and
lighter background color respectively, and a slanted edge between them
similar to the `/` symbol.
* In menus exclusive labels are grouped with a divider line.
---------
Co-authored-by: Yarden Shoham <hrsi88@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
2023-02-18 20:17:39 +01:00
// Get the exclusive scope for every label ID
labelExclusiveScopes := make ( [ ] string , 0 , len ( labelIDs ) )
for _ , labelID := range labelIDs {
foundExclusiveScope := false
for _ , label := range labels {
if label . ID == labelID || label . ID == - labelID {
labelExclusiveScopes = append ( labelExclusiveScopes , label . ExclusiveScope ( ) )
foundExclusiveScope = true
break
}
}
if ! foundExclusiveScope {
labelExclusiveScopes = append ( labelExclusiveScopes , "" )
}
}
2019-01-23 05:10:38 +01:00
for _ , l := range labels {
Scoped labels (#22585)
Add a new "exclusive" option per label. This makes it so that when the
label is named `scope/name`, no other label with the same `scope/`
prefix can be set on an issue.
The scope is determined by the last occurence of `/`, so for example
`scope/alpha/name` and `scope/beta/name` are considered to be in
different scopes and can coexist.
Exclusive scopes are not enforced by any database rules, however they
are enforced when editing labels at the models level, automatically
removing any existing labels in the same scope when either attaching a
new label or replacing all labels.
In menus use a circle instead of checkbox to indicate they function as
radio buttons per scope. Issue filtering by label ensures that only a
single scoped label is selected at a time. Clicking with alt key can be
used to remove a scoped label, both when editing individual issues and
batch editing.
Label rendering refactor for consistency and code simplification:
* Labels now consistently have the same shape, emojis and tooltips
everywhere. This includes the label list and label assignment menus.
* In label list, show description below label same as label menus.
* Don't use exactly black/white text colors to look a bit nicer.
* Simplify text color computation. There is no point computing luminance
in linear color space, as this is a perceptual problem and sRGB is
closer to perceptually linear.
* Increase height of label assignment menus to show more labels. Showing
only 3-4 labels at a time leads to a lot of scrolling.
* Render all labels with a new RenderLabel template helper function.
Label creation and editing in multiline modal menu:
* Change label creation to open a modal menu like label editing.
* Change menu layout to place name, description and colors on separate
lines.
* Don't color cancel button red in label editing modal menu.
* Align text to the left in model menu for better readability and
consistent with settings layout elsewhere.
Custom exclusive scoped label rendering:
* Display scoped label prefix and suffix with slightly darker and
lighter background color respectively, and a slanted edge between them
similar to the `/` symbol.
* In menus exclusive labels are grouped with a divider line.
---------
Co-authored-by: Yarden Shoham <hrsi88@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
2023-02-18 20:17:39 +01:00
l . LoadSelectedLabelsAfterClick ( labelIDs , labelExclusiveScopes )
2019-01-23 05:10:38 +01:00
}
2018-11-29 02:46:30 +01:00
ctx . Data [ "Labels" ] = labels
2019-01-23 05:10:38 +01:00
ctx . Data [ "NumLabels" ] = len ( labels )
2014-07-26 08:28:04 +02:00
2021-07-29 03:42:15 +02:00
if ctx . FormInt64 ( "assignee" ) == 0 {
2016-07-17 03:25:30 +02:00
assigneeID = 0 // Reset ID to prevent unexpected selection of assignee.
}
2022-01-20 18:46:10 +01:00
ctx . Data [ "IssueRefEndNames" ] , ctx . Data [ "IssueRefURLs" ] = issue_service . GetRefEndNamesAndURLs ( issues , ctx . Repo . RepoLink )
2020-05-15 00:55:43 +02:00
2020-03-06 04:44:06 +01:00
ctx . Data [ "ApprovalCounts" ] = func ( issueID int64 , typ string ) int64 {
counts , ok := approvalCounts [ issueID ]
if ! ok || len ( counts ) == 0 {
return 0
}
2022-06-13 11:37:59 +02:00
reviewTyp := issues_model . ReviewTypeApprove
2020-03-06 04:44:06 +01:00
if typ == "reject" {
2022-06-13 11:37:59 +02:00
reviewTyp = issues_model . ReviewTypeReject
2020-04-06 18:33:34 +02:00
} else if typ == "waiting" {
2022-06-13 11:37:59 +02:00
reviewTyp = issues_model . ReviewTypeRequest
2020-03-06 04:44:06 +01:00
}
for _ , count := range counts {
if count . Type == reviewTyp {
return count . Count
}
}
return 0
}
2021-10-08 00:00:02 +02:00
2023-02-04 15:35:08 +01:00
retrieveProjects ( ctx , repo )
if ctx . Written ( ) {
2023-01-29 04:45:29 +01:00
return
2021-10-08 00:00:02 +02:00
}
2024-03-02 16:42:31 +01:00
pinned , err := issues_model . GetPinnedIssues ( ctx , repo . ID , isPullOption . Value ( ) )
2023-05-25 15:17:19 +02:00
if err != nil {
ctx . ServerError ( "GetPinnedIssues" , err )
return
}
ctx . Data [ "PinnedIssues" ] = pinned
ctx . Data [ "IsRepoAdmin" ] = ctx . IsSigned && ( ctx . Repo . IsAdmin ( ) || ctx . Doer . IsAdmin )
2014-07-26 08:28:04 +02:00
ctx . Data [ "IssueStats" ] = issueStats
2023-10-18 02:03:42 +02:00
ctx . Data [ "OpenCount" ] = issueStats . OpenCount
ctx . Data [ "ClosedCount" ] = issueStats . ClosedCount
linkStr := "%s?q=%s&type=%s&sort=%s&state=%s&labels=%s&milestone=%d&project=%d&assignee=%d&poster=%d&archived=%t"
2024-01-15 16:07:22 +01:00
ctx . Data [ "AllStatesLink" ] = fmt . Sprintf ( linkStr , ctx . Link ,
url . QueryEscape ( keyword ) , url . QueryEscape ( viewType ) , url . QueryEscape ( sortType ) , "all" , url . QueryEscape ( selectLabels ) ,
2024-03-19 05:46:40 +01:00
milestoneID , projectID , assigneeID , posterID , archived )
2023-10-18 02:03:42 +02:00
ctx . Data [ "OpenLink" ] = fmt . Sprintf ( linkStr , ctx . Link ,
url . QueryEscape ( keyword ) , url . QueryEscape ( viewType ) , url . QueryEscape ( sortType ) , "open" , url . QueryEscape ( selectLabels ) ,
2024-03-19 05:46:40 +01:00
milestoneID , projectID , assigneeID , posterID , archived )
2023-10-18 02:03:42 +02:00
ctx . Data [ "ClosedLink" ] = fmt . Sprintf ( linkStr , ctx . Link ,
url . QueryEscape ( keyword ) , url . QueryEscape ( viewType ) , url . QueryEscape ( sortType ) , "closed" , url . QueryEscape ( selectLabels ) ,
2024-03-19 05:46:40 +01:00
milestoneID , projectID , assigneeID , posterID , archived )
2019-12-28 15:43:46 +01:00
ctx . Data [ "SelLabelIDs" ] = labelIDs
ctx . Data [ "SelectLabels" ] = selectLabels
2014-07-26 08:28:04 +02:00
ctx . Data [ "ViewType" ] = viewType
2015-08-15 06:07:08 +02:00
ctx . Data [ "SortType" ] = sortType
2015-08-05 14:23:08 +02:00
ctx . Data [ "MilestoneID" ] = milestoneID
2023-01-29 04:45:29 +01:00
ctx . Data [ "ProjectID" ] = projectID
2015-08-15 05:24:41 +02:00
ctx . Data [ "AssigneeID" ] = assigneeID
2022-08-08 22:03:58 +02:00
ctx . Data [ "PosterID" ] = posterID
2017-01-25 03:43:02 +01:00
ctx . Data [ "Keyword" ] = keyword
2024-09-23 19:09:57 +02:00
ctx . Data [ "IsShowClosed" ] = isShowClosed
2024-03-02 16:42:31 +01:00
switch {
case isShowClosed . Value ( ) :
2014-07-26 08:28:04 +02:00
ctx . Data [ "State" ] = "closed"
2024-03-02 16:42:31 +01:00
case ! isShowClosed . Has ( ) :
2024-01-15 16:07:22 +01:00
ctx . Data [ "State" ] = "all"
default :
2015-07-24 20:52:25 +02:00
ctx . Data [ "State" ] = "open"
2014-07-26 08:28:04 +02:00
}
2023-10-18 02:03:42 +02:00
ctx . Data [ "ShowArchivedLabels" ] = archived
2019-04-20 06:15:19 +02:00
2024-03-16 13:07:56 +01:00
pager . AddParamString ( "q" , keyword )
pager . AddParamString ( "type" , viewType )
pager . AddParamString ( "sort" , sortType )
pager . AddParamString ( "state" , fmt . Sprint ( ctx . Data [ "State" ] ) )
pager . AddParamString ( "labels" , fmt . Sprint ( selectLabels ) )
pager . AddParamString ( "milestone" , fmt . Sprint ( milestoneID ) )
pager . AddParamString ( "project" , fmt . Sprint ( projectID ) )
pager . AddParamString ( "assignee" , fmt . Sprint ( assigneeID ) )
pager . AddParamString ( "poster" , fmt . Sprint ( posterID ) )
pager . AddParamString ( "archived" , fmt . Sprint ( archived ) )
2023-10-01 15:04:39 +02:00
2019-04-20 06:15:19 +02:00
ctx . Data [ "Page" ] = pager
2018-11-29 02:46:30 +01:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
func issueIDsFromSearch ( ctx * context . Context , keyword string , opts * issues_model . IssuesOptions ) ( [ ] int64 , error ) {
ids , _ , err := issue_indexer . SearchIssues ( ctx , issue_indexer . ToSearchOptions ( keyword , opts ) )
if err != nil {
return nil , fmt . Errorf ( "SearchIssues: %w" , err )
}
return ids , nil
}
2018-11-29 02:46:30 +01:00
// Issues render issues page
func Issues ( ctx * context . Context ) {
2024-06-19 00:32:45 +02:00
isPullList := ctx . PathParam ( ":type" ) == "pulls"
2018-11-29 02:46:30 +01:00
if isPullList {
MustAllowPulls ( ctx )
if ctx . Written ( ) {
return
}
ctx . Data [ "Title" ] = ctx . Tr ( "repo.pulls" )
ctx . Data [ "PageIsPullList" ] = true
} else {
MustEnableIssues ( ctx )
if ctx . Written ( ) {
return
}
ctx . Data [ "Title" ] = ctx . Tr ( "repo.issues" )
ctx . Data [ "PageIsIssueList" ] = true
2023-05-09 01:30:14 +02:00
ctx . Data [ "NewIssueChooseTemplate" ] = issue_service . HasTemplatesOrContactLinks ( ctx . Repo . Repository , ctx . Repo . GitRepo )
2018-11-29 02:46:30 +01:00
}
2024-03-02 16:42:31 +01:00
issues ( ctx , ctx . FormInt64 ( "milestone" ) , ctx . FormInt64 ( "project" ) , optional . Some ( isPullList ) )
2021-05-09 04:33:49 +02:00
if ctx . Written ( ) {
return
}
2018-11-29 02:46:30 +01:00
2023-04-30 15:12:49 +02:00
renderMilestones ( ctx )
if ctx . Written ( ) {
return
}
ctx . Data [ "CanWriteIssuesOrPulls" ] = ctx . Repo . CanWriteIssuesOrPulls ( isPullList )
ctx . HTML ( http . StatusOK , tplIssues )
}
func renderMilestones ( ctx * context . Context ) {
2020-07-28 13:30:40 +02:00
// Get milestones
2023-12-11 09:56:48 +01:00
milestones , err := db . Find [ issues_model . Milestone ] ( ctx , issues_model . FindMilestoneOptions {
2020-07-28 13:30:40 +02:00
RepoID : ctx . Repo . Repository . ID ,
} )
2018-11-29 02:46:30 +01:00
if err != nil {
ctx . ServerError ( "GetAllRepoMilestones" , err )
return
}
2015-07-24 20:52:25 +02:00
2023-04-30 15:12:49 +02:00
openMilestones , closedMilestones := issues_model . MilestoneList { } , issues_model . MilestoneList { }
for _ , milestone := range milestones {
if milestone . IsClosed {
closedMilestones = append ( closedMilestones , milestone )
} else {
openMilestones = append ( openMilestones , milestone )
}
}
ctx . Data [ "OpenMilestones" ] = openMilestones
ctx . Data [ "ClosedMilestones" ] = closedMilestones
2014-07-26 08:28:04 +02:00
}
2016-11-24 08:04:31 +01:00
// RetrieveRepoMilestonesAndAssignees find all the milestones and assignees of a repository
2021-12-10 02:27:50 +01:00
func RetrieveRepoMilestonesAndAssignees ( ctx * context . Context , repo * repo_model . Repository ) {
2015-09-02 01:07:02 +02:00
var err error
2023-12-11 09:56:48 +01:00
ctx . Data [ "OpenMilestones" ] , err = db . Find [ issues_model . Milestone ] ( ctx , issues_model . FindMilestoneOptions {
RepoID : repo . ID ,
2024-03-02 16:42:31 +01:00
IsClosed : optional . Some ( false ) ,
2020-07-28 13:30:40 +02:00
} )
2015-09-02 01:07:02 +02:00
if err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "GetMilestones" , err )
2015-09-02 01:07:02 +02:00
return
}
2023-12-11 09:56:48 +01:00
ctx . Data [ "ClosedMilestones" ] , err = db . Find [ issues_model . Milestone ] ( ctx , issues_model . FindMilestoneOptions {
RepoID : repo . ID ,
2024-03-02 16:42:31 +01:00
IsClosed : optional . Some ( true ) ,
2020-07-28 13:30:40 +02:00
} )
2015-09-02 01:07:02 +02:00
if err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "GetMilestones" , err )
2015-09-02 01:07:02 +02:00
return
}
2023-04-07 02:11:02 +02:00
assigneeUsers , err := repo_model . GetRepoAssignees ( ctx , repo )
2015-09-02 01:07:02 +02:00
if err != nil {
2023-04-07 02:11:02 +02:00
ctx . ServerError ( "GetRepoAssignees" , err )
2015-09-02 01:07:02 +02:00
return
}
2024-09-12 05:53:40 +02:00
ctx . Data [ "Assignees" ] = shared_user . MakeSelfOnTop ( ctx . Doer , assigneeUsers )
2020-12-21 16:39:28 +01:00
handleTeamMentions ( ctx )
2015-09-02 01:07:02 +02:00
}
2021-12-10 02:27:50 +01:00
func retrieveProjects ( ctx * context . Context , repo * repo_model . Repository ) {
2023-07-29 17:35:53 +02:00
// Distinguish whether the owner of the repository
// is an individual or an organization
repoOwnerType := project_model . TypeIndividual
if repo . Owner . IsOrganization ( ) {
repoOwnerType = project_model . TypeOrganization
}
2023-01-20 12:42:33 +01:00
2024-03-04 03:56:52 +01:00
projectsUnit := repo . MustGetUnit ( ctx , unit . TypeProjects )
2020-08-17 05:07:38 +02:00
2024-03-04 03:56:52 +01:00
var openProjects [ ] * project_model . Project
var closedProjects [ ] * project_model . Project
var err error
if projectsUnit . ProjectsConfig ( ) . IsProjectsAllowed ( repo_model . ProjectsModeRepo ) {
openProjects , err = db . Find [ project_model . Project ] ( ctx , project_model . SearchOptions {
ListOptions : db . ListOptionsAll ,
RepoID : repo . ID ,
IsClosed : optional . Some ( false ) ,
Type : project_model . TypeRepository ,
} )
if err != nil {
ctx . ServerError ( "GetProjects" , err )
return
}
closedProjects , err = db . Find [ project_model . Project ] ( ctx , project_model . SearchOptions {
ListOptions : db . ListOptionsAll ,
RepoID : repo . ID ,
IsClosed : optional . Some ( true ) ,
Type : project_model . TypeRepository ,
} )
if err != nil {
ctx . ServerError ( "GetProjects" , err )
return
}
2020-08-17 05:07:38 +02:00
}
2024-03-04 03:56:52 +01:00
if projectsUnit . ProjectsConfig ( ) . IsProjectsAllowed ( repo_model . ProjectsModeOwner ) {
openProjects2 , err := db . Find [ project_model . Project ] ( ctx , project_model . SearchOptions {
ListOptions : db . ListOptionsAll ,
OwnerID : repo . OwnerID ,
IsClosed : optional . Some ( false ) ,
Type : repoOwnerType ,
} )
if err != nil {
ctx . ServerError ( "GetProjects" , err )
return
}
openProjects = append ( openProjects , openProjects2 ... )
closedProjects2 , err := db . Find [ project_model . Project ] ( ctx , project_model . SearchOptions {
ListOptions : db . ListOptionsAll ,
OwnerID : repo . OwnerID ,
IsClosed : optional . Some ( true ) ,
Type : repoOwnerType ,
} )
if err != nil {
ctx . ServerError ( "GetProjects" , err )
return
}
closedProjects = append ( closedProjects , closedProjects2 ... )
2023-01-20 12:42:33 +01:00
}
2024-03-04 03:56:52 +01:00
ctx . Data [ "OpenProjects" ] = openProjects
ctx . Data [ "ClosedProjects" ] = closedProjects
2020-08-17 05:07:38 +02:00
}
2020-10-12 21:55:13 +02:00
// repoReviewerSelection items to bee shown
type repoReviewerSelection struct {
IsTeam bool
2022-03-29 08:29:02 +02:00
Team * organization . Team
2021-11-24 10:49:20 +01:00
User * user_model . User
2022-06-13 11:37:59 +02:00
Review * issues_model . Review
2020-10-12 21:55:13 +02:00
CanChange bool
Checked bool
ItemID int64
}
2020-04-06 18:33:34 +02:00
// RetrieveRepoReviewers find all reviewers of a repository
2022-06-13 11:37:59 +02:00
func RetrieveRepoReviewers ( ctx * context . Context , repo * repo_model . Repository , issue * issues_model . Issue , canChooseReviewer bool ) {
2020-10-12 21:55:13 +02:00
ctx . Data [ "CanChooseReviewer" ] = canChooseReviewer
2023-09-25 15:17:37 +02:00
originalAuthorReviews , err := issues_model . GetReviewersFromOriginalAuthorsByIssueID ( ctx , issue . ID )
2020-10-14 14:11:11 +02:00
if err != nil {
ctx . ServerError ( "GetReviewersFromOriginalAuthorsByIssueID" , err )
return
}
ctx . Data [ "OriginalReviews" ] = originalAuthorReviews
2023-09-25 15:17:37 +02:00
reviews , err := issues_model . GetReviewsByIssueID ( ctx , issue . ID )
2020-04-06 18:33:34 +02:00
if err != nil {
2020-10-12 21:55:13 +02:00
ctx . ServerError ( "GetReviewersByIssueID" , err )
return
}
if len ( reviews ) == 0 && ! canChooseReviewer {
2020-04-06 18:33:34 +02:00
return
}
2020-10-12 21:55:13 +02:00
var (
pullReviews [ ] * repoReviewerSelection
reviewersResult [ ] * repoReviewerSelection
teamReviewersResult [ ] * repoReviewerSelection
2022-03-29 08:29:02 +02:00
teamReviewers [ ] * organization . Team
2021-11-24 10:49:20 +01:00
reviewers [ ] * user_model . User
2020-10-12 21:55:13 +02:00
)
if canChooseReviewer {
posterID := issue . PosterID
if issue . OriginalAuthorID > 0 {
posterID = 0
}
2022-06-06 10:01:49 +02:00
reviewers , err = repo_model . GetReviewers ( ctx , repo , ctx . Doer . ID , posterID )
2020-10-12 21:55:13 +02:00
if err != nil {
ctx . ServerError ( "GetReviewers" , err )
return
}
2023-02-28 23:17:51 +01:00
teamReviewers , err = repo_service . GetReviewerTeams ( ctx , repo )
2020-10-12 21:55:13 +02:00
if err != nil {
ctx . ServerError ( "GetReviewerTeams" , err )
return
}
if len ( reviewers ) > 0 {
reviewersResult = make ( [ ] * repoReviewerSelection , 0 , len ( reviewers ) )
}
if len ( teamReviewers ) > 0 {
teamReviewersResult = make ( [ ] * repoReviewerSelection , 0 , len ( teamReviewers ) )
}
}
pullReviews = make ( [ ] * repoReviewerSelection , 0 , len ( reviews ) )
for _ , review := range reviews {
tmp := & repoReviewerSelection {
2022-06-13 11:37:59 +02:00
Checked : review . Type == issues_model . ReviewTypeRequest ,
2020-10-12 21:55:13 +02:00
Review : review ,
ItemID : review . ReviewerID ,
}
if review . ReviewerTeamID > 0 {
tmp . IsTeam = true
tmp . ItemID = - review . ReviewerTeamID
}
2024-02-24 13:38:43 +01:00
if canChooseReviewer {
// Users who can choose reviewers can also remove review requests
2020-10-12 21:55:13 +02:00
tmp . CanChange = true
2022-06-13 11:37:59 +02:00
} else if ctx . Doer != nil && ctx . Doer . ID == review . ReviewerID && review . Type == issues_model . ReviewTypeRequest {
2020-10-12 21:55:13 +02:00
// A user can refuse review requests
tmp . CanChange = true
}
pullReviews = append ( pullReviews , tmp )
if canChooseReviewer {
if tmp . IsTeam {
teamReviewersResult = append ( teamReviewersResult , tmp )
} else {
reviewersResult = append ( reviewersResult , tmp )
}
}
}
if len ( pullReviews ) > 0 {
// Drop all non-existing users and teams from the reviews
currentPullReviewers := make ( [ ] * repoReviewerSelection , 0 , len ( pullReviews ) )
for _ , item := range pullReviews {
if item . Review . ReviewerID > 0 {
2022-11-19 09:12:33 +01:00
if err = item . Review . LoadReviewer ( ctx ) ; err != nil {
2021-11-24 10:49:20 +01:00
if user_model . IsErrUserNotExist ( err ) {
2020-10-12 21:55:13 +02:00
continue
}
ctx . ServerError ( "LoadReviewer" , err )
return
}
item . User = item . Review . Reviewer
} else if item . Review . ReviewerTeamID > 0 {
2022-11-19 09:12:33 +01:00
if err = item . Review . LoadReviewerTeam ( ctx ) ; err != nil {
2022-03-29 08:29:02 +02:00
if organization . IsErrTeamNotExist ( err ) {
2020-10-12 21:55:13 +02:00
continue
}
ctx . ServerError ( "LoadReviewerTeam" , err )
return
}
item . Team = item . Review . ReviewerTeam
} else {
continue
}
currentPullReviewers = append ( currentPullReviewers , item )
}
ctx . Data [ "PullReviewers" ] = currentPullReviewers
}
if canChooseReviewer && reviewersResult != nil {
preadded := len ( reviewersResult )
for _ , reviewer := range reviewers {
found := false
reviewAddLoop :
for _ , tmp := range reviewersResult [ : preadded ] {
if tmp . ItemID == reviewer . ID {
tmp . User = reviewer
found = true
break reviewAddLoop
}
}
if found {
continue
}
reviewersResult = append ( reviewersResult , & repoReviewerSelection {
IsTeam : false ,
CanChange : true ,
User : reviewer ,
ItemID : reviewer . ID ,
} )
}
ctx . Data [ "Reviewers" ] = reviewersResult
}
if canChooseReviewer && teamReviewersResult != nil {
preadded := len ( teamReviewersResult )
for _ , team := range teamReviewers {
found := false
teamReviewAddLoop :
for _ , tmp := range teamReviewersResult [ : preadded ] {
if tmp . ItemID == - team . ID {
tmp . Team = team
found = true
break teamReviewAddLoop
}
}
if found {
continue
}
teamReviewersResult = append ( teamReviewersResult , & repoReviewerSelection {
IsTeam : true ,
CanChange : true ,
Team : team ,
ItemID : - team . ID ,
} )
}
ctx . Data [ "TeamReviewers" ] = teamReviewersResult
}
2020-04-06 18:33:34 +02:00
}
2016-11-24 08:04:31 +01:00
// RetrieveRepoMetas find all the meta information of a repository
2022-06-13 11:37:59 +02:00
func RetrieveRepoMetas ( ctx * context . Context , repo * repo_model . Repository , isPull bool ) [ ] * issues_model . Label {
2020-01-20 13:00:32 +01:00
if ! ctx . Repo . CanWriteIssuesOrPulls ( isPull ) {
2015-08-31 09:24:28 +02:00
return nil
}
2022-06-13 11:37:59 +02:00
labels , err := issues_model . GetLabelsByRepoID ( ctx , repo . ID , "" , db . ListOptions { } )
2015-08-31 09:24:28 +02:00
if err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "GetLabelsByRepoID" , err )
2015-08-31 09:24:28 +02:00
return nil
}
ctx . Data [ "Labels" ] = labels
Add Organization Wide Labels (#10814)
* Add organization wide labels
Implement organization wide labels similar to organization wide
webhooks. This lets you create individual labels for organizations that can be used
for all repos under that organization (so being able to reuse the same
label across multiple repos).
This makes it possible for small organizations with many repos to use
labels effectively.
Fixes #7406
* Add migration
* remove comments
* fix tests
* Update options/locale/locale_en-US.ini
Removed unused translation string
* show org labels in issue search label filter
* Use more clear var name
* rename migration after merge from master
* comment typo
* update migration again after rebase with master
* check for orgID <=0 per guillep2k review
* fmt
* Apply suggestions from code review
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* remove unused code
* Make sure RepoID is 0 when searching orgID per code review
* more changes/code review requests
* More descriptive translation var per code review
* func description/delete comment when issue label deleted instead of hiding it
* remove comment
* only use issues in that repo when calculating number of open issues for org label on repo label page
* Add integration test for IssuesSearch API with labels
* remove unused function
* Update models/issue_label.go
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* Use subquery in GetLabelIDsInReposByNames
* Fix tests to use correct orgID
* fix more tests
* IssuesSearch api now uses new BuildLabelNamesIssueIDsCondition. Add a few more tests as well
* update comment for clarity
* Revert previous code change now that we can use the new BuildLabelNamesIssueIDsCondition
* Don't sort repos by date in IssuesSearch API
After much debugging I've found a strange issue where in some cases MySQL will return a different result than other enigines if a query is sorted by a null collumn. For example with our integration test data where we don't set updated_unix in repository fixtures:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 45
Returns different results for MySQL than other engines. However, the similar query:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 30
Returns the same results.
This causes integration tests to fail on MySQL in certain cases but would never show up in a real installation. Since this API call always returns issues based on the optionally provided repo_priority_id or the issueID itself, there is no change to results by changing the repo sorting method used to get ids earlier in the function.
* linter is back!
* code review
* remove now unused option
* Fix newline at end of files
* more unused code
* update to master
* check for matching ids before query
* Update models/issue_label.go
Co-Authored-By: 6543 <6543@obermui.de>
* Update models/issue_label.go
* update comments
* Update routers/org/setting.go
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: guillep2k <18600385+guillep2k@users.noreply.github.com>
Co-authored-by: 6543 <6543@obermui.de>
2020-04-01 06:14:46 +02:00
if repo . Owner . IsOrganization ( ) {
2022-06-13 11:37:59 +02:00
orgLabels , err := issues_model . GetLabelsByOrgID ( ctx , repo . Owner . ID , ctx . FormString ( "sort" ) , db . ListOptions { } )
Add Organization Wide Labels (#10814)
* Add organization wide labels
Implement organization wide labels similar to organization wide
webhooks. This lets you create individual labels for organizations that can be used
for all repos under that organization (so being able to reuse the same
label across multiple repos).
This makes it possible for small organizations with many repos to use
labels effectively.
Fixes #7406
* Add migration
* remove comments
* fix tests
* Update options/locale/locale_en-US.ini
Removed unused translation string
* show org labels in issue search label filter
* Use more clear var name
* rename migration after merge from master
* comment typo
* update migration again after rebase with master
* check for orgID <=0 per guillep2k review
* fmt
* Apply suggestions from code review
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* remove unused code
* Make sure RepoID is 0 when searching orgID per code review
* more changes/code review requests
* More descriptive translation var per code review
* func description/delete comment when issue label deleted instead of hiding it
* remove comment
* only use issues in that repo when calculating number of open issues for org label on repo label page
* Add integration test for IssuesSearch API with labels
* remove unused function
* Update models/issue_label.go
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* Use subquery in GetLabelIDsInReposByNames
* Fix tests to use correct orgID
* fix more tests
* IssuesSearch api now uses new BuildLabelNamesIssueIDsCondition. Add a few more tests as well
* update comment for clarity
* Revert previous code change now that we can use the new BuildLabelNamesIssueIDsCondition
* Don't sort repos by date in IssuesSearch API
After much debugging I've found a strange issue where in some cases MySQL will return a different result than other enigines if a query is sorted by a null collumn. For example with our integration test data where we don't set updated_unix in repository fixtures:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 45
Returns different results for MySQL than other engines. However, the similar query:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 30
Returns the same results.
This causes integration tests to fail on MySQL in certain cases but would never show up in a real installation. Since this API call always returns issues based on the optionally provided repo_priority_id or the issueID itself, there is no change to results by changing the repo sorting method used to get ids earlier in the function.
* linter is back!
* code review
* remove now unused option
* Fix newline at end of files
* more unused code
* update to master
* check for matching ids before query
* Update models/issue_label.go
Co-Authored-By: 6543 <6543@obermui.de>
* Update models/issue_label.go
* update comments
* Update routers/org/setting.go
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: guillep2k <18600385+guillep2k@users.noreply.github.com>
Co-authored-by: 6543 <6543@obermui.de>
2020-04-01 06:14:46 +02:00
if err != nil {
return nil
}
ctx . Data [ "OrgLabels" ] = orgLabels
labels = append ( labels , orgLabels ... )
}
2015-08-31 09:24:28 +02:00
2015-09-02 01:07:02 +02:00
RetrieveRepoMilestonesAndAssignees ( ctx , repo )
if ctx . Written ( ) {
2015-08-31 09:24:28 +02:00
return nil
}
2020-08-17 05:07:38 +02:00
retrieveProjects ( ctx , repo )
if ctx . Written ( ) {
return nil
}
2023-07-21 13:20:04 +02:00
PrepareBranchList ( ctx )
if ctx . Written ( ) {
2017-08-24 14:30:27 +02:00
return nil
}
2018-07-17 23:23:58 +02:00
// Contains true if the user can create issue dependencies
2023-10-14 10:37:24 +02:00
ctx . Data [ "CanCreateIssueDependencies" ] = ctx . Repo . CanCreateIssueDependencies ( ctx , ctx . Doer , isPull )
2018-07-17 23:23:58 +02:00
2015-08-31 09:24:28 +02:00
return labels
}
2023-09-14 16:20:16 +02:00
// Tries to load and set an issue template. The first return value indicates if a template was loaded.
func setTemplateIfExists ( ctx * context . Context , ctxDataKey string , possibleFiles [ ] string ) ( bool , map [ string ] error ) {
2022-09-02 09:58:49 +02:00
commit , err := ctx . Repo . GitRepo . GetBranchCommit ( ctx . Repo . Repository . DefaultBranch )
2016-02-17 23:21:31 +01:00
if err != nil {
2023-09-14 16:20:16 +02:00
return false , nil
2016-02-17 23:21:31 +01:00
}
2022-09-02 09:58:49 +02:00
templateCandidates := make ( [ ] string , 0 , 1 + len ( possibleFiles ) )
if t := ctx . FormString ( "template" ) ; t != "" {
templateCandidates = append ( templateCandidates , t )
2020-09-11 16:48:39 +02:00
}
templateCandidates = append ( templateCandidates , possibleFiles ... ) // Append files to the end because they should be fallback
2022-09-02 09:58:49 +02:00
templateErrs := map [ string ] error { }
2020-09-11 16:48:39 +02:00
for _ , filename := range templateCandidates {
2022-09-02 09:58:49 +02:00
if ok , _ := commit . HasFile ( filename ) ; ! ok {
continue
}
template , err := issue_template . UnmarshalFromCommit ( commit , filename )
if err != nil {
templateErrs [ filename ] = err
continue
}
ctx . Data [ issueTemplateTitleKey ] = template . Title
ctx . Data [ ctxDataKey ] = template . Content
if template . Type ( ) == api . IssueTemplateTypeYaml {
2023-01-30 05:36:04 +01:00
// Replace field default values by values from query
for _ , field := range template . Fields {
fieldValue := ctx . FormString ( "field:" + field . ID )
if fieldValue != "" {
field . Attributes [ "value" ] = fieldValue
}
}
2022-09-02 09:58:49 +02:00
ctx . Data [ "Fields" ] = template . Fields
ctx . Data [ "TemplateFile" ] = template . FileName
}
labelIDs := make ( [ ] string , 0 , len ( template . Labels ) )
if repoLabels , err := issues_model . GetLabelsByRepoID ( ctx , ctx . Repo . Repository . ID , "" , db . ListOptions { } ) ; err == nil {
ctx . Data [ "Labels" ] = repoLabels
if ctx . Repo . Owner . IsOrganization ( ) {
if orgLabels , err := issues_model . GetLabelsByOrgID ( ctx , ctx . Repo . Owner . ID , ctx . FormString ( "sort" ) , db . ListOptions { } ) ; err == nil {
ctx . Data [ "OrgLabels" ] = orgLabels
repoLabels = append ( repoLabels , orgLabels ... )
2021-02-10 18:18:22 +01:00
}
2022-09-02 09:58:49 +02:00
}
2021-02-10 18:18:22 +01:00
2022-09-02 09:58:49 +02:00
for _ , metaLabel := range template . Labels {
for _ , repoLabel := range repoLabels {
if strings . EqualFold ( repoLabel . Name , metaLabel ) {
repoLabel . IsChecked = true
labelIDs = append ( labelIDs , strconv . FormatInt ( repoLabel . ID , 10 ) )
break
2020-09-11 16:48:39 +02:00
}
}
}
2022-11-22 13:58:49 +01:00
}
2024-08-12 10:00:40 +02:00
selectedAssigneeIDs := make ( [ ] int64 , 0 , len ( template . Assignees ) )
selectedAssigneeIDStrings := make ( [ ] string , 0 , len ( template . Assignees ) )
if userIDs , err := user_model . GetUserIDsByNames ( ctx , template . Assignees , false ) ; err == nil {
for _ , userID := range userIDs {
selectedAssigneeIDs = append ( selectedAssigneeIDs , userID )
selectedAssigneeIDStrings = append ( selectedAssigneeIDStrings , strconv . FormatInt ( userID , 10 ) )
}
}
2023-01-18 22:50:22 +01:00
if template . Ref != "" && ! strings . HasPrefix ( template . Ref , "refs/" ) { // Assume that the ref intended is always a branch - for tags users should use refs/tags/<ref>
2022-11-22 13:58:49 +01:00
template . Ref = git . BranchPrefix + template . Ref
2016-02-17 23:21:31 +01:00
}
2022-09-02 09:58:49 +02:00
ctx . Data [ "HasSelectedLabel" ] = len ( labelIDs ) > 0
ctx . Data [ "label_ids" ] = strings . Join ( labelIDs , "," )
2024-08-12 10:00:40 +02:00
ctx . Data [ "HasSelectedAssignee" ] = len ( selectedAssigneeIDs ) > 0
ctx . Data [ "assignee_ids" ] = strings . Join ( selectedAssigneeIDStrings , "," )
ctx . Data [ "SelectedAssigneeIDs" ] = selectedAssigneeIDs
2022-09-02 09:58:49 +02:00
ctx . Data [ "Reference" ] = template . Ref
2023-05-26 03:04:48 +02:00
ctx . Data [ "RefEndName" ] = git . RefName ( template . Ref ) . ShortName ( )
2023-09-14 16:20:16 +02:00
return true , templateErrs
2016-02-17 23:21:31 +01:00
}
2023-09-14 16:20:16 +02:00
return false , templateErrs
2016-02-17 23:21:31 +01:00
}
2019-01-21 12:45:32 +01:00
// NewIssue render creating issue page
2016-03-11 17:56:52 +01:00
func NewIssue ( ctx * context . Context ) {
2023-08-31 17:36:25 +02:00
issueConfig , _ := issue_service . GetTemplateConfigFromDefaultBranch ( ctx . Repo . Repository , ctx . Repo . GitRepo )
hasTemplates := issue_service . HasTemplatesOrContactLinks ( ctx . Repo . Repository , ctx . Repo . GitRepo )
2015-08-09 09:23:02 +02:00
ctx . Data [ "Title" ] = ctx . Tr ( "repo.issues.new" )
ctx . Data [ "PageIsIssueList" ] = true
2023-08-31 17:36:25 +02:00
ctx . Data [ "NewIssueChooseTemplate" ] = hasTemplates
2018-08-13 21:04:39 +02:00
ctx . Data [ "PullRequestWorkInProgressPrefixes" ] = setting . Repository . PullRequest . WorkInProgressPrefixes
2021-08-11 02:31:13 +02:00
title := ctx . FormString ( "title" )
2020-09-11 16:48:39 +02:00
ctx . Data [ "TitleQuery" ] = title
2021-08-11 02:31:13 +02:00
body := ctx . FormString ( "body" )
2019-01-28 16:23:59 +01:00
ctx . Data [ "BodyQuery" ] = body
2021-03-18 03:02:38 +01:00
2022-06-30 17:55:08 +02:00
isProjectsEnabled := ctx . Repo . CanRead ( unit . TypeProjects )
ctx . Data [ "IsProjectsEnabled" ] = isProjectsEnabled
2020-10-05 07:49:33 +02:00
ctx . Data [ "IsAttachmentEnabled" ] = setting . Attachment . Enabled
upload . AddUploadContext ( ctx , "comment" )
2018-11-29 02:46:30 +01:00
2021-07-29 03:42:15 +02:00
milestoneID := ctx . FormInt64 ( "milestone" )
2019-06-10 16:16:02 +02:00
if milestoneID > 0 {
2022-04-08 11:11:15 +02:00
milestone , err := issues_model . GetMilestoneByRepoID ( ctx , ctx . Repo . Repository . ID , milestoneID )
2019-06-10 16:16:02 +02:00
if err != nil {
log . Error ( "GetMilestoneByID: %d: %v" , milestoneID , err )
} else {
ctx . Data [ "milestone_id" ] = milestoneID
ctx . Data [ "Milestone" ] = milestone
}
2018-11-29 02:46:30 +01:00
}
2021-07-29 03:42:15 +02:00
projectID := ctx . FormInt64 ( "project" )
2022-06-30 17:55:08 +02:00
if projectID > 0 && isProjectsEnabled {
2022-05-20 16:08:52 +02:00
project , err := project_model . GetProjectByID ( ctx , projectID )
2020-08-17 05:07:38 +02:00
if err != nil {
log . Error ( "GetProjectByID: %d: %v" , projectID , err )
} else if project . RepoID != ctx . Repo . Repository . ID {
log . Error ( "GetProjectByID: %d: %v" , projectID , fmt . Errorf ( "project[%d] not in repo [%d]" , project . ID , ctx . Repo . Repository . ID ) )
} else {
ctx . Data [ "project_id" ] = projectID
ctx . Data [ "Project" ] = project
}
2021-10-05 21:21:52 +02:00
if len ( ctx . Req . URL . Query ( ) . Get ( "project" ) ) > 0 {
ctx . Data [ "redirect_after_creation" ] = "project"
}
2020-08-17 05:07:38 +02:00
}
2020-01-19 07:43:38 +01:00
RetrieveRepoMetas ( ctx , ctx . Repo . Repository , false )
2022-09-02 09:58:49 +02:00
2023-07-21 13:20:04 +02:00
tags , err := repo_model . GetTagNamesByRepoID ( ctx , ctx . Repo . Repository . ID )
if err != nil {
ctx . ServerError ( "GetTagNamesByRepoID" , err )
return
}
ctx . Data [ "Tags" ] = tags
2024-02-12 06:04:10 +01:00
ret := issue_service . ParseTemplatesFromDefaultBranch ( ctx . Repo . Repository , ctx . Repo . GitRepo )
2023-09-14 16:20:16 +02:00
templateLoaded , errs := setTemplateIfExists ( ctx , issueTemplateKey , IssueTemplateCandidates )
2023-10-06 08:49:37 +02:00
for k , v := range errs {
2024-02-12 06:04:10 +01:00
ret . TemplateErrors [ k ] = v
2022-09-02 09:58:49 +02:00
}
2015-08-31 09:24:28 +02:00
if ctx . Written ( ) {
return
2015-08-10 12:57:57 +02:00
}
2015-08-09 09:23:02 +02:00
2024-02-12 06:04:10 +01:00
if len ( ret . TemplateErrors ) > 0 {
ctx . Flash . Warning ( renderErrorOfTemplates ( ctx , ret . TemplateErrors ) , true )
2022-09-02 09:58:49 +02:00
}
2021-11-09 20:57:58 +01:00
ctx . Data [ "HasIssuesOrPullsWritePermission" ] = ctx . Repo . CanWrite ( unit . TypeIssues )
2020-04-04 07:39:48 +02:00
2023-09-14 16:20:16 +02:00
if ! issueConfig . BlankIssuesEnabled && hasTemplates && ! templateLoaded {
// The "issues/new" and "issues/new/choose" share the same query parameters "project" and "milestone", if blank issues are disabled, just redirect to the "issues/choose" page with these parameters.
ctx . Redirect ( fmt . Sprintf ( "%s/issues/new/choose?%s" , ctx . Repo . Repository . Link ( ) , ctx . Req . URL . RawQuery ) , http . StatusSeeOther )
return
}
2021-04-05 17:30:52 +02:00
ctx . HTML ( http . StatusOK , tplIssueNew )
2014-07-26 08:28:04 +02:00
}
2024-03-02 16:05:07 +01:00
func renderErrorOfTemplates ( ctx * context . Context , errs map [ string ] error ) template . HTML {
2022-09-02 09:58:49 +02:00
var files [ ] string
for k := range errs {
files = append ( files , k )
}
sort . Strings ( files ) // keep the output stable
var lines [ ] string
for _ , file := range files {
lines = append ( lines , fmt . Sprintf ( "%s: %v" , file , errs [ file ] ) )
}
2024-03-02 16:05:07 +01:00
flashError , err := ctx . RenderToHTML ( tplAlertDetails , map [ string ] any {
2022-09-02 09:58:49 +02:00
"Message" : ctx . Tr ( "repo.issues.choose.ignore_invalid_templates" ) ,
"Summary" : ctx . Tr ( "repo.issues.choose.invalid_templates" , len ( errs ) ) ,
"Details" : utils . SanitizeFlashErrorString ( strings . Join ( lines , "\n" ) ) ,
} )
if err != nil {
log . Debug ( "render flash error: %v" , err )
2024-03-02 16:05:07 +01:00
flashError = ctx . Locale . Tr ( "repo.issues.choose.ignore_invalid_templates" )
2022-09-02 09:58:49 +02:00
}
return flashError
}
2020-09-11 16:48:39 +02:00
// NewIssueChooseTemplate render creating issue from template page
func NewIssueChooseTemplate ( ctx * context . Context ) {
ctx . Data [ "Title" ] = ctx . Tr ( "repo.issues.new" )
ctx . Data [ "PageIsIssueList" ] = true
2024-02-12 06:04:10 +01:00
ret := issue_service . ParseTemplatesFromDefaultBranch ( ctx . Repo . Repository , ctx . Repo . GitRepo )
ctx . Data [ "IssueTemplates" ] = ret . IssueTemplates
2020-09-11 16:48:39 +02:00
2024-02-12 06:04:10 +01:00
if len ( ret . TemplateErrors ) > 0 {
ctx . Flash . Warning ( renderErrorOfTemplates ( ctx , ret . TemplateErrors ) , true )
2022-09-02 09:58:49 +02:00
}
2023-05-09 01:30:14 +02:00
if ! issue_service . HasTemplatesOrContactLinks ( ctx . Repo . Repository , ctx . Repo . GitRepo ) {
2022-03-22 20:54:24 +01:00
// The "issues/new" and "issues/new/choose" share the same query parameters "project" and "milestone", if no template here, just redirect to the "issues/new" page with these parameters.
2023-02-11 07:34:11 +01:00
ctx . Redirect ( fmt . Sprintf ( "%s/issues/new?%s" , ctx . Repo . Repository . Link ( ) , ctx . Req . URL . RawQuery ) , http . StatusSeeOther )
2022-03-22 20:54:24 +01:00
return
}
2023-05-09 01:30:14 +02:00
issueConfig , err := issue_service . GetTemplateConfigFromDefaultBranch ( ctx . Repo . Repository , ctx . Repo . GitRepo )
2023-03-28 20:22:07 +02:00
ctx . Data [ "IssueConfig" ] = issueConfig
ctx . Data [ "IssueConfigError" ] = err // ctx.Flash.Err makes problems here
2022-03-22 20:54:24 +01:00
ctx . Data [ "milestone" ] = ctx . FormInt64 ( "milestone" )
ctx . Data [ "project" ] = ctx . FormInt64 ( "project" )
2021-04-05 17:30:52 +02:00
ctx . HTML ( http . StatusOK , tplIssueChoose )
2020-09-11 16:48:39 +02:00
}
2022-03-09 01:38:11 +01:00
// DeleteIssue deletes an issue
func DeleteIssue ( ctx * context . Context ) {
issue := GetActionIssue ( ctx )
if ctx . Written ( ) {
return
}
2023-04-14 20:18:28 +02:00
if err := issue_service . DeleteIssue ( ctx , ctx . Doer , ctx . Repo . GitRepo , issue ) ; err != nil {
2022-03-09 01:38:11 +01:00
ctx . ServerError ( "DeleteIssueByID" , err )
return
}
2022-06-19 12:05:15 +02:00
if issue . IsPull {
2023-02-11 07:34:11 +01:00
ctx . Redirect ( fmt . Sprintf ( "%s/pulls" , ctx . Repo . Repository . Link ( ) ) , http . StatusSeeOther )
2022-06-19 12:05:15 +02:00
return
}
2023-02-11 07:34:11 +01:00
ctx . Redirect ( fmt . Sprintf ( "%s/issues" , ctx . Repo . Repository . Link ( ) ) , http . StatusSeeOther )
2022-03-09 01:38:11 +01:00
}
2021-07-08 13:38:13 +02:00
// ValidateRepoMetas check and returns repository's meta information
2021-04-06 21:44:05 +02:00
func ValidateRepoMetas ( ctx * context . Context , form forms . CreateIssueForm , isPull bool ) ( [ ] int64 , [ ] int64 , int64 , int64 ) {
2015-09-02 01:07:02 +02:00
var (
repo = ctx . Repo . Repository
err error
)
2020-01-19 07:43:38 +01:00
labels := RetrieveRepoMetas ( ctx , ctx . Repo . Repository , isPull )
2015-09-02 01:07:02 +02:00
if ctx . Written ( ) {
2020-08-17 05:07:38 +02:00
return nil , nil , 0 , 0
2015-09-02 01:07:02 +02:00
}
2017-02-01 03:36:08 +01:00
var labelIDs [ ] int64
2015-09-02 01:07:02 +02:00
hasSelected := false
2017-02-01 03:36:08 +01:00
// Check labels.
if len ( form . LabelIDs ) > 0 {
labelIDs , err = base . StringsToInt64s ( strings . Split ( form . LabelIDs , "," ) )
if err != nil {
2020-08-17 05:07:38 +02:00
return nil , nil , 0 , 0
2017-02-01 03:36:08 +01:00
}
2022-10-12 07:18:26 +02:00
labelIDMark := make ( container . Set [ int64 ] )
labelIDMark . AddMultiple ( labelIDs ... )
2017-02-01 03:36:08 +01:00
for i := range labels {
2022-10-12 07:18:26 +02:00
if labelIDMark . Contains ( labels [ i ] . ID ) {
2017-02-01 03:36:08 +01:00
labels [ i ] . IsChecked = true
hasSelected = true
}
2015-09-02 01:07:02 +02:00
}
}
2017-02-01 03:36:08 +01:00
ctx . Data [ "Labels" ] = labels
2015-09-02 01:07:02 +02:00
ctx . Data [ "HasSelectedLabel" ] = hasSelected
ctx . Data [ "label_ids" ] = form . LabelIDs
// Check milestone.
milestoneID := form . MilestoneID
if milestoneID > 0 {
2022-04-08 11:11:15 +02:00
milestone , err := issues_model . GetMilestoneByRepoID ( ctx , ctx . Repo . Repository . ID , milestoneID )
2015-09-02 01:07:02 +02:00
if err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "GetMilestoneByID" , err )
2020-08-17 05:07:38 +02:00
return nil , nil , 0 , 0
2015-09-02 01:07:02 +02:00
}
2021-12-10 02:27:50 +01:00
if milestone . RepoID != repo . ID {
ctx . ServerError ( "GetMilestoneByID" , err )
return nil , nil , 0 , 0
}
ctx . Data [ "Milestone" ] = milestone
2015-09-02 01:07:02 +02:00
ctx . Data [ "milestone_id" ] = milestoneID
}
2020-08-17 05:07:38 +02:00
if form . ProjectID > 0 {
2022-05-20 16:08:52 +02:00
p , err := project_model . GetProjectByID ( ctx , form . ProjectID )
2020-08-17 05:07:38 +02:00
if err != nil {
ctx . ServerError ( "GetProjectByID" , err )
return nil , nil , 0 , 0
}
2023-01-20 12:42:33 +01:00
if p . RepoID != ctx . Repo . Repository . ID && p . OwnerID != ctx . Repo . Repository . OwnerID {
2020-08-17 05:07:38 +02:00
ctx . NotFound ( "" , nil )
return nil , nil , 0 , 0
}
ctx . Data [ "Project" ] = p
ctx . Data [ "project_id" ] = form . ProjectID
}
2018-05-09 18:29:04 +02:00
// Check assignees
var assigneeIDs [ ] int64
if len ( form . AssigneeIDs ) > 0 {
assigneeIDs , err = base . StringsToInt64s ( strings . Split ( form . AssigneeIDs , "," ) )
2015-09-02 01:07:02 +02:00
if err != nil {
2020-08-17 05:07:38 +02:00
return nil , nil , 0 , 0
2018-05-09 18:29:04 +02:00
}
2019-10-25 16:46:37 +02:00
// Check if the passed assignees actually exists and is assignable
2018-05-09 18:29:04 +02:00
for _ , aID := range assigneeIDs {
2022-12-03 03:48:26 +01:00
assignee , err := user_model . GetUserByID ( ctx , aID )
2018-11-28 12:26:14 +01:00
if err != nil {
ctx . ServerError ( "GetUserByID" , err )
2020-08-17 05:07:38 +02:00
return nil , nil , 0 , 0
2018-11-28 12:26:14 +01:00
}
2022-05-11 12:09:36 +02:00
valid , err := access_model . CanBeAssigned ( ctx , assignee , repo , isPull )
2018-05-09 18:29:04 +02:00
if err != nil {
2020-08-17 05:07:38 +02:00
ctx . ServerError ( "CanBeAssigned" , err )
return nil , nil , 0 , 0
2018-11-28 12:26:14 +01:00
}
2020-08-17 05:07:38 +02:00
2019-10-25 16:46:37 +02:00
if ! valid {
2022-06-13 11:37:59 +02:00
ctx . ServerError ( "canBeAssigned" , repo_model . ErrUserDoesNotHaveAccessToRepo { UserID : aID , RepoName : repo . Name } )
2020-08-17 05:07:38 +02:00
return nil , nil , 0 , 0
2018-05-09 18:29:04 +02:00
}
2015-09-02 01:07:02 +02:00
}
}
2018-05-09 18:29:04 +02:00
// Keep the old assignee id thingy for compatibility reasons
if form . AssigneeID > 0 {
assigneeIDs = append ( assigneeIDs , form . AssigneeID )
}
2020-08-17 05:07:38 +02:00
return labelIDs , assigneeIDs , milestoneID , form . ProjectID
2015-09-02 01:07:02 +02:00
}
2016-11-24 08:04:31 +01:00
// NewIssuePost response for creating new issue
2021-01-26 16:36:53 +01:00
func NewIssuePost ( ctx * context . Context ) {
2021-04-06 21:44:05 +02:00
form := web . GetForm ( ctx ) . ( * forms . CreateIssueForm )
2015-08-09 09:23:02 +02:00
ctx . Data [ "Title" ] = ctx . Tr ( "repo.issues.new" )
ctx . Data [ "PageIsIssueList" ] = true
2023-05-09 01:30:14 +02:00
ctx . Data [ "NewIssueChooseTemplate" ] = issue_service . HasTemplatesOrContactLinks ( ctx . Repo . Repository , ctx . Repo . GitRepo )
2018-08-13 21:04:39 +02:00
ctx . Data [ "PullRequestWorkInProgressPrefixes" ] = setting . Repository . PullRequest . WorkInProgressPrefixes
2020-10-05 07:49:33 +02:00
ctx . Data [ "IsAttachmentEnabled" ] = setting . Attachment . Enabled
upload . AddUploadContext ( ctx , "comment" )
2014-07-26 08:28:04 +02:00
2015-08-10 10:52:08 +02:00
var (
2015-08-10 12:57:57 +02:00
repo = ctx . Repo . Repository
2015-08-11 17:24:40 +02:00
attachments [ ] string
2015-08-10 10:52:08 +02:00
)
2015-08-31 09:24:28 +02:00
2021-01-26 16:36:53 +01:00
labelIDs , assigneeIDs , milestoneID , projectID := ValidateRepoMetas ( ctx , * form , false )
2015-09-02 01:07:02 +02:00
if ctx . Written ( ) {
return
2015-08-10 10:52:08 +02:00
}
2024-03-04 12:24:02 +01:00
if projectID > 0 {
if ! ctx . Repo . CanRead ( unit . TypeProjects ) {
// User must also be able to see the project.
ctx . Error ( http . StatusBadRequest , "user hasn't permissions to read projects" )
return
}
}
2020-08-18 06:23:45 +02:00
if setting . Attachment . Enabled {
2016-08-11 14:48:08 +02:00
attachments = form . Files
2015-08-11 17:24:40 +02:00
}
2014-07-26 08:28:04 +02:00
if ctx . HasError ( ) {
2023-06-16 08:32:43 +02:00
ctx . JSONError ( ctx . GetErrMsg ( ) )
2014-07-26 08:28:04 +02:00
return
}
2019-01-21 12:45:32 +01:00
if util . IsEmptyString ( form . Title ) {
2023-06-16 08:32:43 +02:00
ctx . JSONError ( ctx . Tr ( "repo.issues.new.title_empty" ) )
2019-01-21 12:45:32 +01:00
return
}
2022-09-02 09:58:49 +02:00
content := form . Content
if filename := ctx . Req . Form . Get ( "template-file" ) ; filename != "" {
if template , err := issue_template . UnmarshalFromRepo ( ctx . Repo . GitRepo , ctx . Repo . Repository . DefaultBranch , filename ) ; err == nil {
content = issue_template . RenderToMarkdown ( template , ctx . Req . Form )
}
}
2022-06-13 11:37:59 +02:00
issue := & issues_model . Issue {
2016-03-14 04:20:22 +01:00
RepoID : repo . ID ,
2021-11-16 19:18:25 +01:00
Repo : repo ,
2016-08-14 12:32:24 +02:00
Title : form . Title ,
2022-03-22 08:03:22 +01:00
PosterID : ctx . Doer . ID ,
Poster : ctx . Doer ,
2015-08-10 12:57:57 +02:00
MilestoneID : milestoneID ,
2022-09-02 09:58:49 +02:00
Content : content ,
2017-08-24 14:30:27 +02:00
Ref : form . Ref ,
2014-07-26 08:28:04 +02:00
}
Add Organization Wide Labels (#10814)
* Add organization wide labels
Implement organization wide labels similar to organization wide
webhooks. This lets you create individual labels for organizations that can be used
for all repos under that organization (so being able to reuse the same
label across multiple repos).
This makes it possible for small organizations with many repos to use
labels effectively.
Fixes #7406
* Add migration
* remove comments
* fix tests
* Update options/locale/locale_en-US.ini
Removed unused translation string
* show org labels in issue search label filter
* Use more clear var name
* rename migration after merge from master
* comment typo
* update migration again after rebase with master
* check for orgID <=0 per guillep2k review
* fmt
* Apply suggestions from code review
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* remove unused code
* Make sure RepoID is 0 when searching orgID per code review
* more changes/code review requests
* More descriptive translation var per code review
* func description/delete comment when issue label deleted instead of hiding it
* remove comment
* only use issues in that repo when calculating number of open issues for org label on repo label page
* Add integration test for IssuesSearch API with labels
* remove unused function
* Update models/issue_label.go
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* Use subquery in GetLabelIDsInReposByNames
* Fix tests to use correct orgID
* fix more tests
* IssuesSearch api now uses new BuildLabelNamesIssueIDsCondition. Add a few more tests as well
* update comment for clarity
* Revert previous code change now that we can use the new BuildLabelNamesIssueIDsCondition
* Don't sort repos by date in IssuesSearch API
After much debugging I've found a strange issue where in some cases MySQL will return a different result than other enigines if a query is sorted by a null collumn. For example with our integration test data where we don't set updated_unix in repository fixtures:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 45
Returns different results for MySQL than other engines. However, the similar query:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 30
Returns the same results.
This causes integration tests to fail on MySQL in certain cases but would never show up in a real installation. Since this API call always returns issues based on the optionally provided repo_priority_id or the issueID itself, there is no change to results by changing the repo sorting method used to get ids earlier in the function.
* linter is back!
* code review
* remove now unused option
* Fix newline at end of files
* more unused code
* update to master
* check for matching ids before query
* Update models/issue_label.go
Co-Authored-By: 6543 <6543@obermui.de>
* Update models/issue_label.go
* update comments
* Update routers/org/setting.go
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: guillep2k <18600385+guillep2k@users.noreply.github.com>
Co-authored-by: 6543 <6543@obermui.de>
2020-04-01 06:14:46 +02:00
2024-03-04 12:24:02 +01:00
if err := issue_service . NewIssue ( ctx , repo , issue , labelIDs , attachments , assigneeIDs , projectID ) ; err != nil {
2022-06-13 11:37:59 +02:00
if repo_model . IsErrUserDoesNotHaveAccessToRepo ( err ) {
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusBadRequest , "UserDoesNotHaveAccessToRepo" , err . Error ( ) )
2024-03-04 09:16:03 +01:00
} else if errors . Is ( err , user_model . ErrBlockedUser ) {
ctx . JSONError ( ctx . Tr ( "repo.issues.new.blocked_user" ) )
} else {
ctx . ServerError ( "NewIssue" , err )
2018-05-09 18:29:04 +02:00
}
2014-07-26 08:28:04 +02:00
return
2015-08-10 17:31:59 +02:00
}
2015-09-02 01:07:02 +02:00
log . Trace ( "Issue created: %d/%d" , repo . ID , issue . ID )
2023-04-08 10:17:50 +02:00
if ctx . FormString ( "redirect_after_creation" ) == "project" && projectID > 0 {
2023-06-16 08:32:43 +02:00
ctx . JSONRedirect ( ctx . Repo . RepoLink + "/projects/" + strconv . FormatInt ( projectID , 10 ) )
2021-10-05 21:21:52 +02:00
} else {
2023-06-16 08:32:43 +02:00
ctx . JSONRedirect ( issue . Link ( ) )
2021-10-05 21:21:52 +02:00
}
2014-07-26 08:28:04 +02:00
}
2023-08-24 07:06:17 +02:00
// roleDescriptor returns the role descriptor for a comment in/with the given repo, poster and issue
2023-02-15 18:29:13 +01:00
func roleDescriptor ( ctx stdCtx . Context , repo * repo_model . Repository , poster * user_model . User , issue * issues_model . Issue , hasOriginalAuthor bool ) ( issues_model . RoleDescriptor , error ) {
2023-08-24 07:06:17 +02:00
roleDescriptor := issues_model . RoleDescriptor { }
2023-02-15 18:29:13 +01:00
if hasOriginalAuthor {
2023-08-24 07:06:17 +02:00
return roleDescriptor , nil
2023-02-15 18:29:13 +01:00
}
2022-05-11 12:09:36 +02:00
perm , err := access_model . GetUserRepoPermission ( ctx , repo , poster )
2018-11-28 12:26:14 +01:00
if err != nil {
2023-08-24 07:06:17 +02:00
return roleDescriptor , err
2017-12-21 08:43:26 +01:00
}
2020-11-28 16:52:29 +01:00
2023-08-24 07:06:17 +02:00
// If the poster is the actual poster of the issue, enable Poster role.
roleDescriptor . IsPoster = issue . IsPoster ( poster . ID )
2020-11-28 16:52:29 +01:00
2021-11-11 07:29:30 +01:00
// Check if the poster is owner of the repo.
if perm . IsOwner ( ) {
2023-08-24 07:06:17 +02:00
// If the poster isn't an admin, enable the owner role.
2021-11-11 07:29:30 +01:00
if ! poster . IsAdmin {
2023-08-24 07:06:17 +02:00
roleDescriptor . RoleInRepo = issues_model . RoleRepoOwner
return roleDescriptor , nil
}
2020-11-28 16:52:29 +01:00
2023-08-24 07:06:17 +02:00
// Otherwise check if poster is the real repo admin.
2023-10-03 12:30:41 +02:00
ok , err := access_model . IsUserRealRepoAdmin ( ctx , repo , poster )
2023-08-24 07:06:17 +02:00
if err != nil {
return roleDescriptor , err
}
if ok {
roleDescriptor . RoleInRepo = issues_model . RoleRepoOwner
return roleDescriptor , nil
2020-11-28 16:52:29 +01:00
}
2021-11-11 07:29:30 +01:00
}
2020-11-28 16:52:29 +01:00
2023-08-24 07:06:17 +02:00
// If repo is organization, check Member role
if err := repo . LoadOwner ( ctx ) ; err != nil {
return roleDescriptor , err
}
if repo . Owner . IsOrganization ( ) {
if isMember , err := organization . IsOrganizationMember ( ctx , repo . Owner . ID , poster . ID ) ; err != nil {
return roleDescriptor , err
} else if isMember {
roleDescriptor . RoleInRepo = issues_model . RoleRepoMember
return roleDescriptor , nil
}
2020-11-28 16:52:29 +01:00
}
2023-08-24 07:06:17 +02:00
// If the poster is the collaborator of the repo
if isCollaborator , err := repo_model . IsCollaborator ( ctx , repo . ID , poster . ID ) ; err != nil {
return roleDescriptor , err
} else if isCollaborator {
roleDescriptor . RoleInRepo = issues_model . RoleRepoCollaborator
return roleDescriptor , nil
}
hasMergedPR , err := issues_model . HasMergedPullRequestInRepo ( ctx , repo . ID , poster . ID )
if err != nil {
return roleDescriptor , err
} else if hasMergedPR {
roleDescriptor . RoleInRepo = issues_model . RoleRepoContributor
2023-11-27 11:46:55 +01:00
} else if issue . IsPull {
2023-08-24 07:06:17 +02:00
// only display first time contributor in the first opening pull request
roleDescriptor . RoleInRepo = issues_model . RoleRepoFirstTimeContributor
2017-12-21 08:43:26 +01:00
}
2018-11-28 12:26:14 +01:00
2021-11-11 07:29:30 +01:00
return roleDescriptor , nil
2017-12-21 08:43:26 +01:00
}
2022-06-13 11:37:59 +02:00
func getBranchData ( ctx * context . Context , issue * issues_model . Issue ) {
2019-12-16 07:20:25 +01:00
ctx . Data [ "BaseBranch" ] = nil
ctx . Data [ "HeadBranch" ] = nil
ctx . Data [ "HeadUserName" ] = nil
ctx . Data [ "BaseName" ] = ctx . Repo . Repository . OwnerName
if issue . IsPull {
pull := issue . PullRequest
ctx . Data [ "BaseBranch" ] = pull . BaseBranch
ctx . Data [ "HeadBranch" ] = pull . HeadBranch
2022-11-19 09:12:33 +01:00
ctx . Data [ "HeadUserName" ] = pull . MustHeadUserName ( ctx )
2019-12-16 07:20:25 +01:00
}
}
2016-11-24 08:04:31 +01:00
// ViewIssue render issue view page
2016-03-11 17:56:52 +01:00
func ViewIssue ( ctx * context . Context ) {
2024-06-19 00:32:45 +02:00
if ctx . PathParam ( ":type" ) == "issues" {
2019-12-14 01:53:32 +01:00
// If issue was requested we check if repo has external tracker and redirect
2022-12-10 03:46:31 +01:00
extIssueUnit , err := ctx . Repo . Repository . GetUnit ( ctx , unit . TypeExternalTracker )
2019-12-14 01:53:32 +01:00
if err == nil && extIssueUnit != nil {
if extIssueUnit . ExternalTrackerConfig ( ) . ExternalTrackerStyle == markup . IssueNameStyleNumeric || extIssueUnit . ExternalTrackerConfig ( ) . ExternalTrackerStyle == "" {
2023-10-11 06:24:07 +02:00
metas := ctx . Repo . Repository . ComposeMetas ( ctx )
2024-06-19 00:32:45 +02:00
metas [ "index" ] = ctx . PathParam ( ":index" )
2022-04-01 10:47:50 +02:00
res , err := vars . Expand ( extIssueUnit . ExternalTrackerConfig ( ) . ExternalTrackerFormat , metas )
if err != nil {
log . Error ( "unable to expand template vars for issue url. issue: %s, err: %v" , metas [ "index" ] , err )
ctx . ServerError ( "Expand" , err )
return
}
ctx . Redirect ( res )
2019-12-14 01:53:32 +01:00
return
}
2021-12-10 02:27:50 +01:00
} else if err != nil && ! repo_model . IsErrUnitTypeNotExist ( err ) {
2019-12-14 01:53:32 +01:00
ctx . ServerError ( "GetUnit" , err )
2019-12-07 05:21:18 +01:00
return
}
}
2024-06-19 00:32:45 +02:00
issue , err := issues_model . GetIssueByIndex ( ctx , ctx . Repo . Repository . ID , ctx . PathParamInt64 ( ":index" ) )
2014-07-26 08:28:04 +02:00
if err != nil {
2022-06-13 11:37:59 +02:00
if issues_model . IsErrIssueNotExist ( err ) {
2018-01-10 22:34:17 +01:00
ctx . NotFound ( "GetIssueByIndex" , err )
2014-07-26 08:28:04 +02:00
} else {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "GetIssueByIndex" , err )
2014-07-26 08:28:04 +02:00
}
return
}
2021-11-16 19:18:25 +01:00
if issue . Repo == nil {
issue . Repo = ctx . Repo . Repository
}
2017-03-30 01:31:47 +02:00
2015-09-02 01:07:02 +02:00
// Make sure type and URL matches.
2024-06-19 00:32:45 +02:00
if ctx . PathParam ( ":type" ) == "issues" && issue . IsPull {
2021-11-16 19:18:25 +01:00
ctx . Redirect ( issue . Link ( ) )
2015-09-02 01:07:02 +02:00
return
2024-06-19 00:32:45 +02:00
} else if ctx . PathParam ( ":type" ) == "pulls" && ! issue . IsPull {
2021-11-16 19:18:25 +01:00
ctx . Redirect ( issue . Link ( ) )
2015-09-02 01:07:02 +02:00
return
}
2015-09-02 10:08:05 +02:00
if issue . IsPull {
2016-03-07 05:57:46 +01:00
MustAllowPulls ( ctx )
if ctx . Written ( ) {
return
}
ctx . Data [ "PageIsPullList" ] = true
2015-09-02 10:08:05 +02:00
ctx . Data [ "PageIsPullConversation" ] = true
} else {
2015-12-05 03:30:33 +01:00
MustEnableIssues ( ctx )
if ctx . Written ( ) {
return
}
2015-09-02 10:08:05 +02:00
ctx . Data [ "PageIsIssueList" ] = true
2023-05-09 01:30:14 +02:00
ctx . Data [ "NewIssueChooseTemplate" ] = issue_service . HasTemplatesOrContactLinks ( ctx . Repo . Repository , ctx . Repo . GitRepo )
2015-09-02 10:08:05 +02:00
}
2021-11-09 20:57:58 +01:00
if issue . IsPull && ! ctx . Repo . CanRead ( unit . TypeIssues ) {
2020-01-19 07:43:38 +01:00
ctx . Data [ "IssueType" ] = "pulls"
2021-11-09 20:57:58 +01:00
} else if ! issue . IsPull && ! ctx . Repo . CanRead ( unit . TypePullRequests ) {
2020-01-19 07:43:38 +01:00
ctx . Data [ "IssueType" ] = "issues"
} else {
ctx . Data [ "IssueType" ] = "all"
}
2021-11-09 20:57:58 +01:00
ctx . Data [ "IsProjectsEnabled" ] = ctx . Repo . CanRead ( unit . TypeProjects )
2020-10-05 07:49:33 +02:00
ctx . Data [ "IsAttachmentEnabled" ] = setting . Attachment . Enabled
upload . AddUploadContext ( ctx , "comment" )
2018-11-28 12:26:14 +01:00
2022-06-13 11:37:59 +02:00
if err = issue . LoadAttributes ( ctx ) ; err != nil {
2019-09-20 07:45:38 +02:00
ctx . ServerError ( "LoadAttributes" , err )
return
}
if err = filterXRefComments ( ctx , issue ) ; err != nil {
ctx . ServerError ( "filterXRefComments" , err )
2018-12-13 16:55:43 +01:00
return
}
2024-02-24 23:34:51 +01:00
ctx . Data [ "Title" ] = fmt . Sprintf ( "#%d - %s" , issue . Index , emoji . ReplaceAliases ( issue . Title ) )
2018-11-28 12:26:14 +01:00
2022-06-13 11:37:59 +02:00
iw := new ( issues_model . IssueWatch )
2022-03-22 08:03:22 +01:00
if ctx . Doer != nil {
iw . UserID = ctx . Doer . ID
2020-04-21 15:48:53 +02:00
iw . IssueID = issue . ID
2023-09-16 16:39:12 +02:00
iw . IsWatching , err = issues_model . CheckIssueWatch ( ctx , ctx . Doer , issue )
2018-11-28 12:26:14 +01:00
if err != nil {
2021-01-14 21:27:22 +01:00
ctx . ServerError ( "CheckIssueWatch" , err )
2018-11-28 12:26:14 +01:00
return
}
}
ctx . Data [ "IssueWatch" ] = iw
2021-04-20 00:25:08 +02:00
issue . RenderedContent , err = markdown . RenderString ( & markup . RenderContext {
2024-01-15 09:49:24 +01:00
Links : markup . Links {
Base : ctx . Repo . RepoLink ,
} ,
Metas : ctx . Repo . Repository . ComposeMetas ( ctx ) ,
GitRepo : ctx . Repo . GitRepo ,
2024-05-30 09:04:01 +02:00
Repo : ctx . Repo . Repository ,
2024-01-15 09:49:24 +01:00
Ctx : ctx ,
2021-04-20 00:25:08 +02:00
} , issue . Content )
if err != nil {
ctx . ServerError ( "RenderString" , err )
return
}
2014-07-26 08:28:04 +02:00
2015-08-14 18:42:43 +02:00
repo := ctx . Repo . Repository
2015-09-02 01:07:02 +02:00
// Get more information if it's a pull request.
if issue . IsPull {
2016-08-16 19:19:09 +02:00
if issue . PullRequest . HasMerged {
ctx . Data [ "DisableStatusChange" ] = issue . PullRequest . HasMerged
2015-09-02 15:26:56 +02:00
PrepareMergedViewPullInfo ( ctx , issue )
} else {
PrepareViewPullInfo ( ctx , issue )
2019-04-20 22:50:34 +02:00
ctx . Data [ "DisableStatusChange" ] = ctx . Data [ "IsPullRequestBroken" ] == true && issue . IsClosed
2015-09-02 15:26:56 +02:00
}
2015-09-02 10:08:05 +02:00
if ctx . Written ( ) {
2015-09-02 01:07:02 +02:00
return
}
}
2015-08-12 11:04:23 +02:00
// Metas.
2015-08-14 18:42:43 +02:00
// Check labels.
2022-10-12 07:18:26 +02:00
labelIDMark := make ( container . Set [ int64 ] )
for _ , label := range issue . Labels {
labelIDMark . Add ( label . ID )
2015-08-14 18:42:43 +02:00
}
2022-06-13 11:37:59 +02:00
labels , err := issues_model . GetLabelsByRepoID ( ctx , repo . ID , "" , db . ListOptions { } )
2015-08-14 18:42:43 +02:00
if err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "GetLabelsByRepoID" , err )
2015-08-14 18:42:43 +02:00
return
}
Add Organization Wide Labels (#10814)
* Add organization wide labels
Implement organization wide labels similar to organization wide
webhooks. This lets you create individual labels for organizations that can be used
for all repos under that organization (so being able to reuse the same
label across multiple repos).
This makes it possible for small organizations with many repos to use
labels effectively.
Fixes #7406
* Add migration
* remove comments
* fix tests
* Update options/locale/locale_en-US.ini
Removed unused translation string
* show org labels in issue search label filter
* Use more clear var name
* rename migration after merge from master
* comment typo
* update migration again after rebase with master
* check for orgID <=0 per guillep2k review
* fmt
* Apply suggestions from code review
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* remove unused code
* Make sure RepoID is 0 when searching orgID per code review
* more changes/code review requests
* More descriptive translation var per code review
* func description/delete comment when issue label deleted instead of hiding it
* remove comment
* only use issues in that repo when calculating number of open issues for org label on repo label page
* Add integration test for IssuesSearch API with labels
* remove unused function
* Update models/issue_label.go
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* Use subquery in GetLabelIDsInReposByNames
* Fix tests to use correct orgID
* fix more tests
* IssuesSearch api now uses new BuildLabelNamesIssueIDsCondition. Add a few more tests as well
* update comment for clarity
* Revert previous code change now that we can use the new BuildLabelNamesIssueIDsCondition
* Don't sort repos by date in IssuesSearch API
After much debugging I've found a strange issue where in some cases MySQL will return a different result than other enigines if a query is sorted by a null collumn. For example with our integration test data where we don't set updated_unix in repository fixtures:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 45
Returns different results for MySQL than other engines. However, the similar query:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 30
Returns the same results.
This causes integration tests to fail on MySQL in certain cases but would never show up in a real installation. Since this API call always returns issues based on the optionally provided repo_priority_id or the issueID itself, there is no change to results by changing the repo sorting method used to get ids earlier in the function.
* linter is back!
* code review
* remove now unused option
* Fix newline at end of files
* more unused code
* update to master
* check for matching ids before query
* Update models/issue_label.go
Co-Authored-By: 6543 <6543@obermui.de>
* Update models/issue_label.go
* update comments
* Update routers/org/setting.go
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: guillep2k <18600385+guillep2k@users.noreply.github.com>
Co-authored-by: 6543 <6543@obermui.de>
2020-04-01 06:14:46 +02:00
ctx . Data [ "Labels" ] = labels
if repo . Owner . IsOrganization ( ) {
2022-06-13 11:37:59 +02:00
orgLabels , err := issues_model . GetLabelsByOrgID ( ctx , repo . Owner . ID , ctx . FormString ( "sort" ) , db . ListOptions { } )
Add Organization Wide Labels (#10814)
* Add organization wide labels
Implement organization wide labels similar to organization wide
webhooks. This lets you create individual labels for organizations that can be used
for all repos under that organization (so being able to reuse the same
label across multiple repos).
This makes it possible for small organizations with many repos to use
labels effectively.
Fixes #7406
* Add migration
* remove comments
* fix tests
* Update options/locale/locale_en-US.ini
Removed unused translation string
* show org labels in issue search label filter
* Use more clear var name
* rename migration after merge from master
* comment typo
* update migration again after rebase with master
* check for orgID <=0 per guillep2k review
* fmt
* Apply suggestions from code review
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* remove unused code
* Make sure RepoID is 0 when searching orgID per code review
* more changes/code review requests
* More descriptive translation var per code review
* func description/delete comment when issue label deleted instead of hiding it
* remove comment
* only use issues in that repo when calculating number of open issues for org label on repo label page
* Add integration test for IssuesSearch API with labels
* remove unused function
* Update models/issue_label.go
Co-Authored-By: guillep2k <18600385+guillep2k@users.noreply.github.com>
* Use subquery in GetLabelIDsInReposByNames
* Fix tests to use correct orgID
* fix more tests
* IssuesSearch api now uses new BuildLabelNamesIssueIDsCondition. Add a few more tests as well
* update comment for clarity
* Revert previous code change now that we can use the new BuildLabelNamesIssueIDsCondition
* Don't sort repos by date in IssuesSearch API
After much debugging I've found a strange issue where in some cases MySQL will return a different result than other enigines if a query is sorted by a null collumn. For example with our integration test data where we don't set updated_unix in repository fixtures:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 45
Returns different results for MySQL than other engines. However, the similar query:
SELECT `id`, `owner_id`, `owner_name`, `lower_name`, `name`, `description`, `website`, `original_service_type`, `original_url`, `default_branch`, `num_watches`, `num_stars`, `num_forks`, `num_issues`, `num_closed_issues`, `num_pulls`, `num_closed_pulls`, `num_milestones`, `num_closed_milestones`, `is_private`, `is_empty`, `is_archived`, `is_mirror`, `status`, `is_fork`, `fork_id`, `is_template`, `template_id`, `size`, `is_fsck_enabled`, `close_issues_via_commit_in_any_branch`, `topics`, `avatar`, `created_unix`, `updated_unix` FROM `repository` ORDER BY updated_unix DESC LIMIT 15 OFFSET 30
Returns the same results.
This causes integration tests to fail on MySQL in certain cases but would never show up in a real installation. Since this API call always returns issues based on the optionally provided repo_priority_id or the issueID itself, there is no change to results by changing the repo sorting method used to get ids earlier in the function.
* linter is back!
* code review
* remove now unused option
* Fix newline at end of files
* more unused code
* update to master
* check for matching ids before query
* Update models/issue_label.go
Co-Authored-By: 6543 <6543@obermui.de>
* Update models/issue_label.go
* update comments
* Update routers/org/setting.go
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: guillep2k <18600385+guillep2k@users.noreply.github.com>
Co-authored-by: 6543 <6543@obermui.de>
2020-04-01 06:14:46 +02:00
if err != nil {
ctx . ServerError ( "GetLabelsByOrgID" , err )
return
}
ctx . Data [ "OrgLabels" ] = orgLabels
labels = append ( labels , orgLabels ... )
}
2015-08-14 18:42:43 +02:00
hasSelected := false
for i := range labels {
2022-10-12 07:18:26 +02:00
if labelIDMark . Contains ( labels [ i ] . ID ) {
2015-08-14 18:42:43 +02:00
labels [ i ] . IsChecked = true
hasSelected = true
}
}
ctx . Data [ "HasSelectedLabel" ] = hasSelected
// Check milestone and assignee.
2018-11-28 12:26:14 +01:00
if ctx . Repo . CanWriteIssuesOrPulls ( issue . IsPull ) {
2015-09-02 01:07:02 +02:00
RetrieveRepoMilestonesAndAssignees ( ctx , repo )
2020-08-17 05:07:38 +02:00
retrieveProjects ( ctx , repo )
2015-09-02 01:07:02 +02:00
if ctx . Written ( ) {
2015-08-14 18:42:43 +02:00
return
}
}
2014-07-26 08:28:04 +02:00
2020-04-06 18:33:34 +02:00
if issue . IsPull {
2024-02-24 13:38:43 +01:00
canChooseReviewer := false
2022-09-09 19:27:47 +02:00
if ctx . Doer != nil && ctx . IsSigned {
2024-02-24 13:38:43 +01:00
canChooseReviewer = issue_service . CanDoerChangeReviewRequests ( ctx , ctx . Doer , repo , issue )
2020-04-06 18:33:34 +02:00
}
2020-10-12 21:55:13 +02:00
RetrieveRepoReviewers ( ctx , repo , issue , canChooseReviewer )
2020-04-06 18:33:34 +02:00
if ctx . Written ( ) {
return
}
}
2015-08-12 11:04:23 +02:00
if ctx . IsSigned {
2015-08-12 12:44:09 +02:00
// Update issue-user.
2022-08-25 04:31:57 +02:00
if err = activities_model . SetIssueReadBy ( ctx , issue . ID , ctx . Doer . ID ) ; err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "ReadBy" , err )
2015-08-12 12:44:09 +02:00
return
}
2015-08-12 11:04:23 +02:00
}
2015-08-13 20:43:40 +02:00
var (
Fix cannot reopen after pushing commits to a closed PR (#23189)
Close: #22784
1. On GH, we can reopen a PR which was closed before after pushing
commits. After reopening PR, we can see the commits that were pushed
after closing PR in the time line. So the case of
[issue](https://github.com/go-gitea/gitea/issues/22784) is a bug which
needs to be fixed.
2. After closing a PR and pushing commits, `headBranchSha` is not equal
to `sha`(which is the last commit ID string of reference). If the
judgement exists, the button of reopen will not display. So, skip the
judgement if the status of PR is closed.

3. Even if PR is already close, we should still insert comment record
into DB when we push commits.
So we should still call function `CreatePushPullComment()`.
https://github.com/go-gitea/gitea/blob/067b0c2664d127c552ccdfd264257caca4907a77/services/pull/pull.go#L260-L282
So, I add a switch(`includeClosed`) to the
`GetUnmergedPullRequestsByHeadInfo` func to control whether the status
of PR must be open. In this case, by setting `includeClosed` to `true`,
we can query the closed PR.
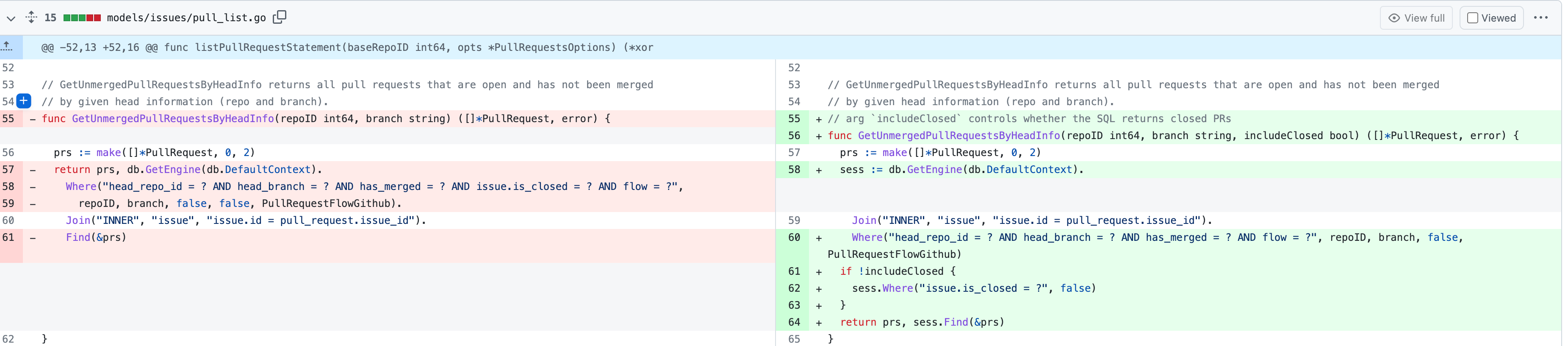
4. In the loop of comments, I use the`latestCloseCommentID` variable to
record the last occurrence of the close comment.
In the go template, if the status of PR is closed, the comments whose
type is `CommentTypePullRequestPush(29)` after `latestCloseCommentID`
won't be rendered.
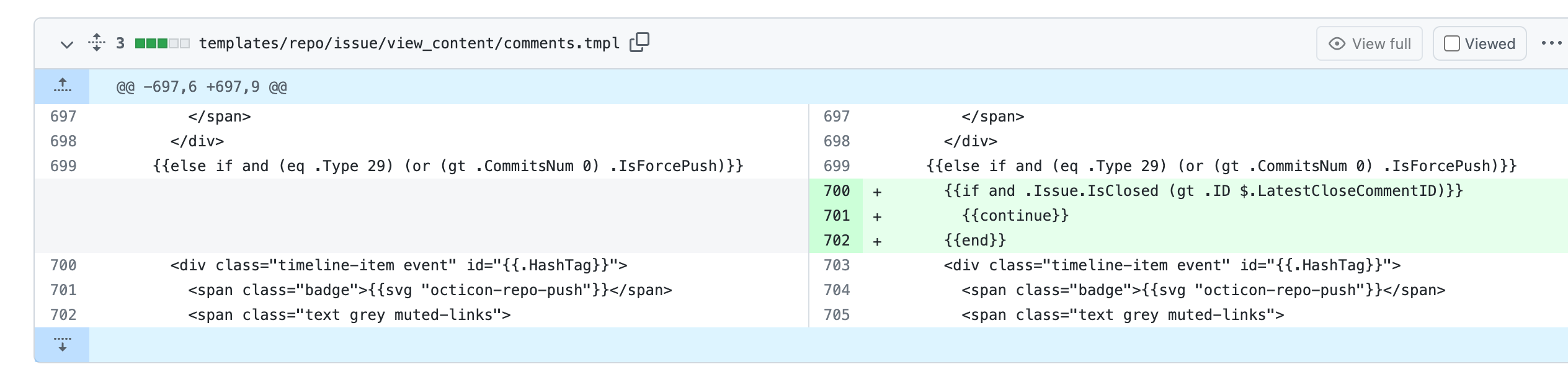
e.g.
1). The initial status of the PR is opened.
2). Then I click the button of `Close`. PR is closed now.
3). I try to push a commit to this PR, even though its current status is
closed.

But in comments list, this commit do not display.This is as expected :)
4). Click the `Reopen` button, the commit which is pushed after closing
PR display now.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-03-03 14:16:58 +01:00
role issues_model . RoleDescriptor
ok bool
marked = make ( map [ int64 ] issues_model . RoleDescriptor )
comment * issues_model . Comment
participants = make ( [ ] * user_model . User , 1 , 10 )
latestCloseCommentID int64
2015-08-13 20:43:40 +02:00
)
2022-12-10 03:46:31 +01:00
if ctx . Repo . Repository . IsTimetrackerEnabled ( ctx ) {
2017-09-12 08:48:13 +02:00
if ctx . IsSigned {
// Deal with the stopwatch
2023-09-16 16:39:12 +02:00
ctx . Data [ "IsStopwatchRunning" ] = issues_model . StopwatchExists ( ctx , ctx . Doer . ID , issue . ID )
2017-09-12 08:48:13 +02:00
if ! ctx . Data [ "IsStopwatchRunning" ] . ( bool ) {
var exists bool
2023-02-27 19:46:00 +01:00
var swIssue * issues_model . Issue
if exists , _ , swIssue , err = issues_model . HasUserStopwatch ( ctx , ctx . Doer . ID ) ; err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "HasUserStopwatch" , err )
2017-09-12 08:48:13 +02:00
return
}
ctx . Data [ "HasUserStopwatch" ] = exists
if exists {
// Add warning if the user has already a stopwatch
// Add link to the issue of the already running stopwatch
2023-02-27 19:46:00 +01:00
ctx . Data [ "OtherStopwatchURL" ] = swIssue . Link ( )
2017-09-12 08:48:13 +02:00
}
}
2023-10-14 10:37:24 +02:00
ctx . Data [ "CanUseTimetracker" ] = ctx . Repo . CanUseTimetracker ( ctx , issue , ctx . Doer )
2017-09-12 08:48:13 +02:00
} else {
ctx . Data [ "CanUseTimetracker" ] = false
}
2023-10-03 12:30:41 +02:00
if ctx . Data [ "WorkingUsers" ] , err = issues_model . TotalTimesForEachUser ( ctx , & issues_model . FindTrackedTimesOptions { IssueID : issue . ID } ) ; err != nil {
2023-09-29 15:04:14 +02:00
ctx . ServerError ( "TotalTimesForEachUser" , err )
2017-09-12 08:48:13 +02:00
return
}
}
2016-02-02 02:55:12 +01:00
2018-07-17 23:23:58 +02:00
// Check if the user can use the dependencies
2023-10-14 10:37:24 +02:00
ctx . Data [ "CanCreateIssueDependencies" ] = ctx . Repo . CanCreateIssueDependencies ( ctx , ctx . Doer , issue . IsPull )
2018-07-17 23:23:58 +02:00
Allow cross-repository dependencies on issues (#7901)
* in progress changes for #7405, added ability to add cross-repo dependencies
* removed unused repolink var
* fixed query that was breaking ci tests; fixed check in issue dependency add so that the id of the issue and dependency is checked rather than the indexes
* reverted removal of string in local files becasue these are done via crowdin, not updated manually
* removed 'Select("issue.*")' from getBlockedByDependencies and getBlockingDependencies based on comments in PR review
* changed getBlockedByDependencies and getBlockingDependencies to use a more xorm-like query, also updated the sidebar as a result
* simplified the getBlockingDependencies and getBlockedByDependencies methods; changed the sidebar to show the dependencies in a different format where you can see the name of the repository
* made some changes to the issue view in the dependencies (issue name on top, repo full name on separate line). Change view of issue in the dependency search results (also showing the full repo name on separate line)
* replace call to FindUserAccessibleRepoIDs with SearchRepositoryByName. The former was hardcoded to use isPrivate = false on the repo search, but this code needed it to be true. The SearchRepositoryByName method is used more in the code including on the user's dashboard
* some more tweaks to the layout of the issues when showing dependencies and in the search box when you add new dependencies
* added Name to the RepositoryMeta struct
* updated swagger doc
* fixed total count for link header on SearchIssues
* fixed indentation
* fixed aligment of remove icon on dependencies in issue sidebar
* removed unnecessary nil check (unnecessary because issue.loadRepo is called prior to this block)
* reverting .css change, somehow missed or forgot that less is used
* updated less file and generated css; updated sidebar template with styles to line up delete and issue index
* added ordering to the blocked by/depends on queries
* fixed sorting in issue dependency search and the depends on/blocks views to show issues from the current repo first, then by created date descending; added a "all cross repository dependencies" setting to allow this feature to be turned off, if turned off, the issue dependency search will work the way it did before (restricted to the current repository)
* re-applied my swagger changes after merge
* fixed split string condition in issue search
* changed ALLOW_CROSS_REPOSITORY_DEPENDENCIES description to sound more global than just the issue dependency search; returning 400 in the cross repo issue search api method if not enabled; fixed bug where the issue count did not respect the state parameter
* when adding a dependency to an issue, added a check to make sure the issue and dependency are in the same repo if cross repo dependencies is not enabled
* updated sortIssuesSession call in PullRequests, another commit moved this method from pull.go to pull_list.go so I had to re-apply my change here
* fixed incorrect setting of user id parameter in search repos call
2019-10-31 06:06:10 +01:00
// check if dependencies can be created across repositories
ctx . Data [ "AllowCrossRepositoryDependencies" ] = setting . Service . AllowCrossRepositoryDependencies
2023-02-15 18:29:13 +01:00
if issue . ShowRole , err = roleDescriptor ( ctx , repo , issue . Poster , issue , issue . HasOriginalAuthor ( ) ) ; err != nil {
2021-11-11 07:29:30 +01:00
ctx . ServerError ( "roleDescriptor" , err )
2020-09-10 20:09:14 +02:00
return
}
2021-11-11 07:29:30 +01:00
marked [ issue . PosterID ] = issue . ShowRole
2020-09-10 20:09:14 +02:00
2024-03-26 08:48:53 +01:00
// Render comments and fetch participants.
2016-02-02 02:55:12 +01:00
participants [ 0 ] = issue . Poster
2024-03-12 08:23:44 +01:00
if err := issue . Comments . LoadAttachmentsByIssue ( ctx ) ; err != nil {
ctx . ServerError ( "LoadAttachmentsByIssue" , err )
return
}
if err := issue . Comments . LoadPosters ( ctx ) ; err != nil {
ctx . ServerError ( "LoadPosters" , err )
return
}
2015-08-13 20:43:40 +02:00
for _ , comment = range issue . Comments {
2019-05-06 14:09:31 +02:00
comment . Issue = issue
2022-06-13 11:37:59 +02:00
if comment . Type == issues_model . CommentTypeComment || comment . Type == issues_model . CommentTypeReview {
2021-04-20 00:25:08 +02:00
comment . RenderedContent , err = markdown . RenderString ( & markup . RenderContext {
2024-01-15 09:49:24 +01:00
Links : markup . Links {
Base : ctx . Repo . RepoLink ,
} ,
Metas : ctx . Repo . Repository . ComposeMetas ( ctx ) ,
GitRepo : ctx . Repo . GitRepo ,
2024-05-30 09:04:01 +02:00
Repo : ctx . Repo . Repository ,
2024-01-15 09:49:24 +01:00
Ctx : ctx ,
2021-04-20 00:25:08 +02:00
} , comment . Content )
if err != nil {
ctx . ServerError ( "RenderString" , err )
return
}
2015-08-13 20:43:40 +02:00
// Check tag.
2021-11-11 07:29:30 +01:00
role , ok = marked [ comment . PosterID ]
2015-08-13 20:43:40 +02:00
if ok {
2021-11-11 07:29:30 +01:00
comment . ShowRole = role
2015-08-13 20:43:40 +02:00
continue
}
2023-02-15 18:29:13 +01:00
comment . ShowRole , err = roleDescriptor ( ctx , repo , comment . Poster , issue , comment . HasOriginalAuthor ( ) )
2017-12-21 08:43:26 +01:00
if err != nil {
2021-11-11 07:29:30 +01:00
ctx . ServerError ( "roleDescriptor" , err )
2017-12-21 08:43:26 +01:00
return
2015-08-13 20:43:40 +02:00
}
2021-11-11 07:29:30 +01:00
marked [ comment . PosterID ] = comment . ShowRole
2019-09-07 16:53:35 +02:00
participants = addParticipant ( comment . Poster , participants )
2022-06-13 11:37:59 +02:00
} else if comment . Type == issues_model . CommentTypeLabel {
2023-09-29 14:12:54 +02:00
if err = comment . LoadLabel ( ctx ) ; err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "LoadLabel" , err )
2017-01-30 13:46:45 +01:00
return
}
2022-06-13 11:37:59 +02:00
} else if comment . Type == issues_model . CommentTypeMilestone {
2022-11-19 09:12:33 +01:00
if err = comment . LoadMilestone ( ctx ) ; err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "LoadMilestone" , err )
2017-02-01 03:36:08 +01:00
return
}
2022-04-08 11:11:15 +02:00
ghostMilestone := & issues_model . Milestone {
2017-06-17 06:51:28 +02:00
ID : - 1 ,
2024-02-14 22:48:45 +01:00
Name : ctx . Locale . TrString ( "repo.issues.deleted_milestone" ) ,
2017-06-17 06:51:28 +02:00
}
if comment . OldMilestoneID > 0 && comment . OldMilestone == nil {
comment . OldMilestone = ghostMilestone
}
if comment . MilestoneID > 0 && comment . Milestone == nil {
comment . Milestone = ghostMilestone
}
2022-06-13 11:37:59 +02:00
} else if comment . Type == issues_model . CommentTypeProject {
2023-09-29 14:12:54 +02:00
if err = comment . LoadProject ( ctx ) ; err != nil {
2020-08-17 05:07:38 +02:00
ctx . ServerError ( "LoadProject" , err )
return
}
2022-03-29 16:16:31 +02:00
ghostProject := & project_model . Project {
2024-07-30 06:37:43 +02:00
ID : project_model . GhostProjectID ,
2024-02-14 22:48:45 +01:00
Title : ctx . Locale . TrString ( "repo.issues.deleted_project" ) ,
2020-08-17 05:07:38 +02:00
}
if comment . OldProjectID > 0 && comment . OldProject == nil {
comment . OldProject = ghostProject
}
if comment . ProjectID > 0 && comment . Project == nil {
comment . Project = ghostProject
}
2024-08-09 03:29:02 +02:00
} else if comment . Type == issues_model . CommentTypeProjectColumn {
if err = comment . LoadProject ( ctx ) ; err != nil {
ctx . ServerError ( "LoadProject" , err )
return
}
2022-06-13 11:37:59 +02:00
} else if comment . Type == issues_model . CommentTypeAssignees || comment . Type == issues_model . CommentTypeReviewRequest {
2023-09-29 14:12:54 +02:00
if err = comment . LoadAssigneeUserAndTeam ( ctx ) ; err != nil {
2020-10-12 21:55:13 +02:00
ctx . ServerError ( "LoadAssigneeUserAndTeam" , err )
2017-02-03 16:09:10 +01:00
return
}
2022-06-13 11:37:59 +02:00
} else if comment . Type == issues_model . CommentTypeRemoveDependency || comment . Type == issues_model . CommentTypeAddDependency {
2023-09-29 14:12:54 +02:00
if err = comment . LoadDepIssueDetails ( ctx ) ; err != nil {
2022-06-13 11:37:59 +02:00
if ! issues_model . IsErrIssueNotExist ( err ) {
2020-09-04 03:36:56 +02:00
ctx . ServerError ( "LoadDepIssueDetails" , err )
return
}
2018-07-17 23:23:58 +02:00
}
2023-04-20 08:39:44 +02:00
} else if comment . Type . HasContentSupport ( ) {
2021-04-20 00:25:08 +02:00
comment . RenderedContent , err = markdown . RenderString ( & markup . RenderContext {
2024-01-15 09:49:24 +01:00
Links : markup . Links {
Base : ctx . Repo . RepoLink ,
} ,
Metas : ctx . Repo . Repository . ComposeMetas ( ctx ) ,
GitRepo : ctx . Repo . GitRepo ,
2024-05-30 09:04:01 +02:00
Repo : ctx . Repo . Repository ,
2024-01-15 09:49:24 +01:00
Ctx : ctx ,
2021-04-20 00:25:08 +02:00
} , comment . Content )
if err != nil {
ctx . ServerError ( "RenderString" , err )
return
}
2023-09-29 14:12:54 +02:00
if err = comment . LoadReview ( ctx ) ; err != nil && ! issues_model . IsErrReviewNotExist ( err ) {
2018-08-06 06:43:22 +02:00
ctx . ServerError ( "LoadReview" , err )
return
}
2019-09-07 16:53:35 +02:00
participants = addParticipant ( comment . Poster , participants )
2018-08-06 06:43:22 +02:00
if comment . Review == nil {
continue
}
2022-01-20 00:26:57 +01:00
if err = comment . Review . LoadAttributes ( ctx ) ; err != nil {
2021-11-24 10:49:20 +01:00
if ! user_model . IsErrUserNotExist ( err ) {
2019-05-06 14:09:31 +02:00
ctx . ServerError ( "Review.LoadAttributes" , err )
return
}
2021-11-24 10:49:20 +01:00
comment . Review . Reviewer = user_model . NewGhostUser ( )
2018-08-06 06:43:22 +02:00
}
2022-01-20 00:26:57 +01:00
if err = comment . Review . LoadCodeComments ( ctx ) ; err != nil {
2018-08-06 06:43:22 +02:00
ctx . ServerError ( "Review.LoadCodeComments" , err )
return
}
2021-01-17 18:29:10 +01:00
for _ , codeComments := range comment . Review . CodeComments {
for _ , lineComments := range codeComments {
for _ , c := range lineComments {
// Check tag.
2021-11-11 07:29:30 +01:00
role , ok = marked [ c . PosterID ]
2021-01-17 18:29:10 +01:00
if ok {
2021-11-11 07:29:30 +01:00
c . ShowRole = role
2021-01-17 18:29:10 +01:00
continue
}
2020-04-18 15:50:25 +02:00
2023-02-15 18:29:13 +01:00
c . ShowRole , err = roleDescriptor ( ctx , repo , c . Poster , issue , c . HasOriginalAuthor ( ) )
2021-01-17 18:29:10 +01:00
if err != nil {
2021-11-11 07:29:30 +01:00
ctx . ServerError ( "roleDescriptor" , err )
2021-01-17 18:29:10 +01:00
return
}
2021-11-11 07:29:30 +01:00
marked [ c . PosterID ] = c . ShowRole
2021-01-17 18:29:10 +01:00
participants = addParticipant ( c . Poster , participants )
}
}
}
2023-09-29 14:12:54 +02:00
if err = comment . LoadResolveDoer ( ctx ) ; err != nil {
2020-04-18 15:50:25 +02:00
ctx . ServerError ( "LoadResolveDoer" , err )
return
}
2022-06-13 11:37:59 +02:00
} else if comment . Type == issues_model . CommentTypePullRequestPush {
2020-05-20 14:47:24 +02:00
participants = addParticipant ( comment . Poster , participants )
2022-01-20 00:26:57 +01:00
if err = comment . LoadPushCommits ( ctx ) ; err != nil {
2020-05-20 14:47:24 +02:00
ctx . ServerError ( "LoadPushCommits" , err )
return
}
2024-07-28 17:11:40 +02:00
if ! ctx . Repo . CanRead ( unit . TypeActions ) {
for _ , commit := range comment . Commits {
commit . Status . HideActionsURL ( ctx )
git_model . CommitStatusesHideActionsURL ( ctx , commit . Statuses )
}
}
2022-06-13 11:37:59 +02:00
} else if comment . Type == issues_model . CommentTypeAddTimeManual ||
2023-06-23 14:12:39 +02:00
comment . Type == issues_model . CommentTypeStopTracking ||
comment . Type == issues_model . CommentTypeDeleteTimeManual {
2021-02-19 11:52:11 +01:00
// drop error since times could be pruned from DB..
2023-10-03 12:30:41 +02:00
_ = comment . LoadTime ( ctx )
2023-06-23 14:12:39 +02:00
if comment . Content != "" {
2024-04-27 10:03:49 +02:00
// Content before v1.21 did store the formatted string instead of seconds,
// so "|" is used as delimiter to mark the new format
2023-06-23 14:12:39 +02:00
if comment . Content [ 0 ] != '|' {
// handle old time comments that have formatted text stored
2024-03-01 11:16:19 +01:00
comment . RenderedContent = templates . SanitizeHTML ( comment . Content )
2023-06-23 14:12:39 +02:00
comment . Content = ""
} else {
// else it's just a duration in seconds to pass on to the frontend
comment . Content = comment . Content [ 1 : ]
}
}
2023-04-21 18:36:37 +02:00
}
if comment . Type == issues_model . CommentTypeClose || comment . Type == issues_model . CommentTypeMergePull {
// record ID of the latest closed/merged comment.
Fix cannot reopen after pushing commits to a closed PR (#23189)
Close: #22784
1. On GH, we can reopen a PR which was closed before after pushing
commits. After reopening PR, we can see the commits that were pushed
after closing PR in the time line. So the case of
[issue](https://github.com/go-gitea/gitea/issues/22784) is a bug which
needs to be fixed.
2. After closing a PR and pushing commits, `headBranchSha` is not equal
to `sha`(which is the last commit ID string of reference). If the
judgement exists, the button of reopen will not display. So, skip the
judgement if the status of PR is closed.

3. Even if PR is already close, we should still insert comment record
into DB when we push commits.
So we should still call function `CreatePushPullComment()`.
https://github.com/go-gitea/gitea/blob/067b0c2664d127c552ccdfd264257caca4907a77/services/pull/pull.go#L260-L282
So, I add a switch(`includeClosed`) to the
`GetUnmergedPullRequestsByHeadInfo` func to control whether the status
of PR must be open. In this case, by setting `includeClosed` to `true`,
we can query the closed PR.

4. In the loop of comments, I use the`latestCloseCommentID` variable to
record the last occurrence of the close comment.
In the go template, if the status of PR is closed, the comments whose
type is `CommentTypePullRequestPush(29)` after `latestCloseCommentID`
won't be rendered.

e.g.
1). The initial status of the PR is opened.

2). Then I click the button of `Close`. PR is closed now.

3). I try to push a commit to this PR, even though its current status is
closed.

But in comments list, this commit do not display.This is as expected :)

4). Click the `Reopen` button, the commit which is pushed after closing
PR display now.

---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-03-03 14:16:58 +01:00
// if PR is closed, the comments whose type is CommentTypePullRequestPush(29) after latestCloseCommentID won't be rendered.
latestCloseCommentID = comment . ID
2015-08-13 10:07:11 +02:00
}
}
2014-07-26 08:28:04 +02:00
Fix cannot reopen after pushing commits to a closed PR (#23189)
Close: #22784
1. On GH, we can reopen a PR which was closed before after pushing
commits. After reopening PR, we can see the commits that were pushed
after closing PR in the time line. So the case of
[issue](https://github.com/go-gitea/gitea/issues/22784) is a bug which
needs to be fixed.
2. After closing a PR and pushing commits, `headBranchSha` is not equal
to `sha`(which is the last commit ID string of reference). If the
judgement exists, the button of reopen will not display. So, skip the
judgement if the status of PR is closed.

3. Even if PR is already close, we should still insert comment record
into DB when we push commits.
So we should still call function `CreatePushPullComment()`.
https://github.com/go-gitea/gitea/blob/067b0c2664d127c552ccdfd264257caca4907a77/services/pull/pull.go#L260-L282
So, I add a switch(`includeClosed`) to the
`GetUnmergedPullRequestsByHeadInfo` func to control whether the status
of PR must be open. In this case, by setting `includeClosed` to `true`,
we can query the closed PR.

4. In the loop of comments, I use the`latestCloseCommentID` variable to
record the last occurrence of the close comment.
In the go template, if the status of PR is closed, the comments whose
type is `CommentTypePullRequestPush(29)` after `latestCloseCommentID`
won't be rendered.

e.g.
1). The initial status of the PR is opened.

2). Then I click the button of `Close`. PR is closed now.

3). I try to push a commit to this PR, even though its current status is
closed.

But in comments list, this commit do not display.This is as expected :)

4). Click the `Reopen` button, the commit which is pushed after closing
PR display now.

---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-03-03 14:16:58 +01:00
ctx . Data [ "LatestCloseCommentID" ] = latestCloseCommentID
2020-10-25 22:49:48 +01:00
// Combine multiple label assignments into a single comment
combineLabelComments ( issue )
2019-12-16 07:20:25 +01:00
getBranchData ( ctx , issue )
2016-12-25 16:27:25 +01:00
if issue . IsPull {
pull := issue . PullRequest
2018-12-12 00:49:33 +01:00
pull . Issue = issue
2016-12-25 17:19:25 +01:00
canDelete := false
2023-10-30 04:13:06 +01:00
allowMerge := false
2024-06-03 00:45:21 +02:00
canWriteToHeadRepo := false
2016-12-25 17:19:25 +01:00
2017-06-21 03:00:03 +02:00
if ctx . IsSigned {
2022-11-19 09:12:33 +01:00
if err := pull . LoadHeadRepo ( ctx ) ; err != nil {
2020-03-02 23:31:55 +01:00
log . Error ( "LoadHeadRepo: %v" , err )
2022-04-28 17:45:33 +02:00
} else if pull . HeadRepo != nil {
2022-05-11 12:09:36 +02:00
perm , err := access_model . GetUserRepoPermission ( ctx , pull . HeadRepo , ctx . Doer )
2018-11-28 12:26:14 +01:00
if err != nil {
ctx . ServerError ( "GetUserRepoPermission" , err )
return
}
2021-11-09 20:57:58 +01:00
if perm . CanWrite ( unit . TypeCode ) {
2018-11-28 12:26:14 +01:00
// Check if branch is not protected
2022-04-28 17:45:33 +02:00
if pull . HeadBranch != pull . HeadRepo . DefaultBranch {
2023-01-16 09:00:22 +01:00
if protected , err := git_model . IsBranchProtected ( ctx , pull . HeadRepo . ID , pull . HeadBranch ) ; err != nil {
2022-04-28 17:45:33 +02:00
log . Error ( "IsProtectedBranch: %v" , err )
} else if ! protected {
canDelete = true
ctx . Data [ "DeleteBranchLink" ] = issue . Link ( ) + "/cleanup"
}
2018-11-28 12:26:14 +01:00
}
2024-06-03 00:45:21 +02:00
canWriteToHeadRepo = true
2017-06-21 03:00:03 +02:00
}
2016-12-25 17:19:25 +01:00
}
2020-01-11 08:29:34 +01:00
2022-11-19 09:12:33 +01:00
if err := pull . LoadBaseRepo ( ctx ) ; err != nil {
2020-03-02 23:31:55 +01:00
log . Error ( "LoadBaseRepo: %v" , err )
2020-01-11 08:29:34 +01:00
}
2022-05-11 12:09:36 +02:00
perm , err := access_model . GetUserRepoPermission ( ctx , pull . BaseRepo , ctx . Doer )
2020-01-11 08:29:34 +01:00
if err != nil {
ctx . ServerError ( "GetUserRepoPermission" , err )
return
}
2024-06-03 00:45:21 +02:00
if ! canWriteToHeadRepo { // maintainers maybe allowed to push to head repo even if they can't write to it
canWriteToHeadRepo = pull . AllowMaintainerEdit && perm . CanWrite ( unit . TypeCode )
}
2023-10-30 04:13:06 +01:00
allowMerge , err = pull_service . IsUserAllowedToMerge ( ctx , pull , perm , ctx . Doer )
2020-01-11 08:29:34 +01:00
if err != nil {
ctx . ServerError ( "IsUserAllowedToMerge" , err )
return
}
2020-04-18 15:50:25 +02:00
2023-09-29 14:12:54 +02:00
if ctx . Data [ "CanMarkConversation" ] , err = issues_model . CanMarkConversation ( ctx , issue , ctx . Doer ) ; err != nil {
2020-04-18 15:50:25 +02:00
ctx . ServerError ( "CanMarkConversation" , err )
return
}
2016-12-25 17:19:25 +01:00
}
2016-12-25 16:27:25 +01:00
2024-06-03 00:45:21 +02:00
ctx . Data [ "CanWriteToHeadRepo" ] = canWriteToHeadRepo
ctx . Data [ "ShowMergeInstructions" ] = canWriteToHeadRepo
2023-10-30 04:13:06 +01:00
ctx . Data [ "AllowMerge" ] = allowMerge
2022-12-10 03:46:31 +01:00
prUnit , err := repo . GetUnit ( ctx , unit . TypePullRequests )
2018-01-05 19:56:50 +01:00
if err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "GetUnit" , err )
2018-01-05 19:56:50 +01:00
return
}
prConfig := prUnit . PullRequestsConfig ( )
2024-08-10 03:09:34 +02:00
ctx . Data [ "AutodetectManualMerge" ] = prConfig . AutodetectManualMerge
2022-05-08 14:32:45 +02:00
var mergeStyle repo_model . MergeStyle
2018-01-05 19:56:50 +01:00
// Check correct values and select default
2021-12-10 02:27:50 +01:00
if ms , ok := ctx . Data [ "MergeStyle" ] . ( repo_model . MergeStyle ) ; ! ok ||
2018-01-05 19:56:50 +01:00
! prConfig . IsMergeStyleAllowed ( ms ) {
2021-03-27 15:55:40 +01:00
defaultMergeStyle := prConfig . GetDefaultMergeStyle ( )
if prConfig . IsMergeStyleAllowed ( defaultMergeStyle ) && ! ok {
2022-05-08 14:32:45 +02:00
mergeStyle = defaultMergeStyle
2021-03-27 15:55:40 +01:00
} else if prConfig . AllowMerge {
2022-05-08 14:32:45 +02:00
mergeStyle = repo_model . MergeStyleMerge
2018-01-05 19:56:50 +01:00
} else if prConfig . AllowRebase {
2022-05-08 14:32:45 +02:00
mergeStyle = repo_model . MergeStyleRebase
2018-12-27 11:27:08 +01:00
} else if prConfig . AllowRebaseMerge {
2022-05-08 14:32:45 +02:00
mergeStyle = repo_model . MergeStyleRebaseMerge
2018-01-05 19:56:50 +01:00
} else if prConfig . AllowSquash {
2022-05-08 14:32:45 +02:00
mergeStyle = repo_model . MergeStyleSquash
2024-02-12 23:37:23 +01:00
} else if prConfig . AllowFastForwardOnly {
mergeStyle = repo_model . MergeStyleFastForwardOnly
2021-03-04 04:41:23 +01:00
} else if prConfig . AllowManualMerge {
2022-05-08 14:32:45 +02:00
mergeStyle = repo_model . MergeStyleManuallyMerged
2018-01-05 19:56:50 +01:00
}
}
2022-05-08 14:32:45 +02:00
ctx . Data [ "MergeStyle" ] = mergeStyle
2022-12-29 13:40:20 +01:00
defaultMergeMessage , defaultMergeBody , err := pull_service . GetDefaultMergeMessage ( ctx , ctx . Repo . GitRepo , pull , mergeStyle )
2022-05-08 14:32:45 +02:00
if err != nil {
ctx . ServerError ( "GetDefaultMergeMessage" , err )
return
}
ctx . Data [ "DefaultMergeMessage" ] = defaultMergeMessage
2022-12-29 13:40:20 +01:00
ctx . Data [ "DefaultMergeBody" ] = defaultMergeBody
2022-05-08 14:32:45 +02:00
2022-12-29 13:40:20 +01:00
defaultSquashMergeMessage , defaultSquashMergeBody , err := pull_service . GetDefaultMergeMessage ( ctx , ctx . Repo . GitRepo , pull , repo_model . MergeStyleSquash )
2022-05-08 14:32:45 +02:00
if err != nil {
ctx . ServerError ( "GetDefaultSquashMergeMessage" , err )
return
}
ctx . Data [ "DefaultSquashMergeMessage" ] = defaultSquashMergeMessage
2022-12-29 13:40:20 +01:00
ctx . Data [ "DefaultSquashMergeBody" ] = defaultSquashMergeBody
2022-05-08 14:32:45 +02:00
2023-01-16 09:00:22 +01:00
pb , err := git_model . GetFirstMatchProtectedBranchRule ( ctx , pull . BaseRepoID , pull . BaseBranch )
if err != nil {
2018-12-11 12:28:37 +01:00
ctx . ServerError ( "LoadProtectedBranch" , err )
return
}
2024-06-03 00:45:21 +02:00
2023-01-16 09:00:22 +01:00
if pb != nil {
pb . Repo = pull . BaseRepo
ctx . Data [ "ProtectedBranch" ] = pb
ctx . Data [ "IsBlockedByApprovals" ] = ! issues_model . HasEnoughApprovals ( ctx , pb , pull )
ctx . Data [ "IsBlockedByRejection" ] = issues_model . MergeBlockedByRejectedReview ( ctx , pb , pull )
ctx . Data [ "IsBlockedByOfficialReviewRequests" ] = issues_model . MergeBlockedByOfficialReviewRequests ( ctx , pb , pull )
ctx . Data [ "IsBlockedByOutdatedBranch" ] = issues_model . MergeBlockedByOutdatedBranch ( pb , pull )
ctx . Data [ "GrantedApprovals" ] = issues_model . GetGrantedApprovalsCount ( ctx , pb , pull )
ctx . Data [ "RequireSigned" ] = pb . RequireSignedCommits
2020-10-13 20:50:57 +02:00
ctx . Data [ "ChangedProtectedFiles" ] = pull . ChangedProtectedFiles
ctx . Data [ "IsBlockedByChangedProtectedFiles" ] = len ( pull . ChangedProtectedFiles ) != 0
ctx . Data [ "ChangedProtectedFilesNum" ] = len ( pull . ChangedProtectedFiles )
2024-09-06 08:40:02 +02:00
ctx . Data [ "RequireApprovalsWhitelist" ] = pb . EnableApprovalsWhitelist
2020-01-15 09:32:57 +01:00
}
ctx . Data [ "WillSign" ] = false
2022-03-22 08:03:22 +01:00
if ctx . Doer != nil {
sign , key , _ , err := asymkey_service . SignMerge ( ctx , pull , ctx . Doer , pull . BaseRepo . RepoPath ( ) , pull . BaseBranch , pull . GetGitRefName ( ) )
2020-01-15 09:32:57 +01:00
ctx . Data [ "WillSign" ] = sign
ctx . Data [ "SigningKey" ] = key
if err != nil {
2021-12-10 09:14:24 +01:00
if asymkey_service . IsErrWontSign ( err ) {
ctx . Data [ "WontSignReason" ] = err . ( * asymkey_service . ErrWontSign ) . Reason
2020-01-15 09:32:57 +01:00
} else {
ctx . Data [ "WontSignReason" ] = "error"
log . Error ( "Error whilst checking if could sign pr %d in repo %s. Error: %v" , pull . ID , pull . BaseRepo . FullName ( ) , err )
}
}
2020-08-23 23:59:41 +02:00
} else {
ctx . Data [ "WontSignReason" ] = "not_signed_in"
2018-12-11 12:28:37 +01:00
}
2022-01-03 20:45:58 +01:00
isPullBranchDeletable := canDelete &&
2020-01-07 18:06:14 +01:00
pull . HeadRepo != nil &&
2021-11-30 21:06:32 +01:00
git . IsBranchExist ( ctx , pull . HeadRepo . RepoPath ( ) , pull . HeadBranch ) &&
2020-01-07 18:06:14 +01:00
( ! pull . HasMerged || ctx . Data [ "HeadBranchCommitID" ] == ctx . Data [ "PullHeadCommitID" ] )
2021-03-04 04:41:23 +01:00
2022-01-03 20:45:58 +01:00
if isPullBranchDeletable && pull . HasMerged {
2022-06-13 11:37:59 +02:00
exist , err := issues_model . HasUnmergedPullRequestsByHeadInfo ( ctx , pull . HeadRepoID , pull . HeadBranch )
2022-01-03 20:45:58 +01:00
if err != nil {
ctx . ServerError ( "HasUnmergedPullRequestsByHeadInfo" , err )
return
}
isPullBranchDeletable = ! exist
}
ctx . Data [ "IsPullBranchDeletable" ] = isPullBranchDeletable
2021-03-04 04:41:23 +01:00
stillCanManualMerge := func ( ) bool {
if pull . HasMerged || issue . IsClosed || ! ctx . IsSigned {
return false
}
2023-10-11 06:24:07 +02:00
if pull . CanAutoMerge ( ) || pull . IsWorkInProgress ( ctx ) || pull . IsChecking ( ) {
2021-03-04 04:41:23 +01:00
return false
}
2023-10-30 04:13:06 +01:00
if allowMerge && prConfig . AllowManualMerge {
2021-03-04 04:41:23 +01:00
return true
}
return false
}
ctx . Data [ "StillCanManualMerge" ] = stillCanManualMerge ( )
2022-05-07 19:05:52 +02:00
// Check if there is a pending pr merge
ctx . Data [ "HasPendingPullRequestMerge" ] , ctx . Data [ "PendingPullRequestMerge" ] , err = pull_model . GetScheduledMergeByPullID ( ctx , pull . ID )
if err != nil {
ctx . ServerError ( "GetScheduledMergeByPullID" , err )
return
}
2016-12-25 16:27:25 +01:00
}
2018-07-17 23:23:58 +02:00
// Get Dependencies
2023-03-28 19:23:25 +02:00
blockedBy , err := issue . BlockedByDependencies ( ctx , db . ListOptions { } )
2019-06-12 21:41:28 +02:00
if err != nil {
ctx . ServerError ( "BlockedByDependencies" , err )
return
}
2023-03-28 19:23:25 +02:00
ctx . Data [ "BlockedByDependencies" ] , ctx . Data [ "BlockedByDependenciesNotPermitted" ] = checkBlockedByIssues ( ctx , blockedBy )
if ctx . Written ( ) {
return
}
blocking , err := issue . BlockingDependencies ( ctx )
2019-06-12 21:41:28 +02:00
if err != nil {
ctx . ServerError ( "BlockingDependencies" , err )
return
}
2018-07-17 23:23:58 +02:00
2024-01-12 17:49:02 +01:00
ctx . Data [ "BlockingDependencies" ] , ctx . Data [ "BlockingDependenciesNotPermitted" ] = checkBlockedByIssues ( ctx , blocking )
2023-03-28 19:23:25 +02:00
if ctx . Written ( ) {
return
}
2023-05-25 15:17:19 +02:00
var pinAllowed bool
if ! issue . IsPinned ( ) {
pinAllowed , err = issues_model . IsNewPinAllowed ( ctx , issue . RepoID , issue . IsPull )
if err != nil {
ctx . ServerError ( "IsNewPinAllowed" , err )
return
}
} else {
pinAllowed = true
}
2016-01-19 14:04:24 +01:00
ctx . Data [ "Participants" ] = participants
2016-02-02 02:55:12 +01:00
ctx . Data [ "NumParticipants" ] = len ( participants )
2014-07-26 08:28:04 +02:00
ctx . Data [ "Issue" ] = issue
2021-12-17 22:29:09 +01:00
ctx . Data [ "Reference" ] = issue . Ref
2021-11-16 19:18:25 +01:00
ctx . Data [ "SignInLink" ] = setting . AppSubURL + "/user/login?redirect_to=" + url . QueryEscape ( ctx . Data [ "Link" ] . ( string ) )
2022-03-22 08:03:22 +01:00
ctx . Data [ "IsIssuePoster" ] = ctx . IsSigned && issue . IsPoster ( ctx . Doer . ID )
2020-04-04 07:39:48 +02:00
ctx . Data [ "HasIssuesOrPullsWritePermission" ] = ctx . Repo . CanWriteIssuesOrPulls ( issue . IsPull )
2021-11-09 20:57:58 +01:00
ctx . Data [ "HasProjectsWritePermission" ] = ctx . Repo . CanWrite ( unit . TypeProjects )
2022-03-22 08:03:22 +01:00
ctx . Data [ "IsRepoAdmin" ] = ctx . IsSigned && ( ctx . Repo . IsAdmin ( ) || ctx . Doer . IsAdmin )
2019-02-18 21:55:04 +01:00
ctx . Data [ "LockReasons" ] = setting . Repository . Issue . LockReasons
2023-05-26 03:04:48 +02:00
ctx . Data [ "RefEndName" ] = git . RefName ( issue . Ref ) . ShortName ( )
2023-05-25 15:17:19 +02:00
ctx . Data [ "NewPinAllowed" ] = pinAllowed
ctx . Data [ "PinEnabled" ] = setting . Repository . Issue . MaxPinned != 0
2022-01-21 18:59:26 +01:00
var hiddenCommentTypes * big . Int
if ctx . IsSigned {
2023-09-15 08:13:19 +02:00
val , err := user_model . GetUserSetting ( ctx , ctx . Doer . ID , user_model . SettingsKeyHiddenCommentTypes )
2022-01-21 18:59:26 +01:00
if err != nil {
ctx . ServerError ( "GetUserSetting" , err )
return
}
hiddenCommentTypes , _ = new ( big . Int ) . SetString ( val , 10 ) // we can safely ignore the failed conversion here
}
2022-06-13 11:37:59 +02:00
ctx . Data [ "ShouldShowCommentType" ] = func ( commentType issues_model . CommentType ) bool {
2022-01-21 18:59:26 +01:00
return hiddenCommentTypes == nil || hiddenCommentTypes . Bit ( int ( commentType ) ) == 0
}
2023-07-21 13:20:04 +02:00
// For sidebar
PrepareBranchList ( ctx )
if ctx . Written ( ) {
return
}
tags , err := repo_model . GetTagNamesByRepoID ( ctx , ctx . Repo . Repository . ID )
if err != nil {
ctx . ServerError ( "GetTagNamesByRepoID" , err )
return
}
ctx . Data [ "Tags" ] = tags
2022-01-21 18:59:26 +01:00
2024-03-04 09:16:03 +01:00
ctx . Data [ "CanBlockUser" ] = func ( blocker , blockee * user_model . User ) bool {
return user_service . CanBlockUser ( ctx , ctx . Doer , blocker , blockee )
}
2021-04-05 17:30:52 +02:00
ctx . HTML ( http . StatusOK , tplIssueView )
2014-07-26 08:28:04 +02:00
}
2023-07-07 07:31:56 +02:00
// checkBlockedByIssues return canRead and notPermitted
2023-03-28 19:23:25 +02:00
func checkBlockedByIssues ( ctx * context . Context , blockers [ ] * issues_model . DependencyInfo ) ( canRead , notPermitted [ ] * issues_model . DependencyInfo ) {
2024-01-12 17:49:02 +01:00
repoPerms := make ( map [ int64 ] access_model . Permission )
repoPerms [ ctx . Repo . Repository . ID ] = ctx . Repo . Permission
for _ , blocker := range blockers {
2023-03-28 19:23:25 +02:00
// Get the permissions for this repository
2024-01-12 17:49:02 +01:00
// If the repo ID exists in the map, return the exist permissions
// else get the permission and add it to the map
var perm access_model . Permission
existPerm , ok := repoPerms [ blocker . RepoID ]
if ok {
perm = existPerm
} else {
var err error
perm , err = access_model . GetUserRepoPermission ( ctx , & blocker . Repository , ctx . Doer )
if err != nil {
ctx . ServerError ( "GetUserRepoPermission" , err )
return nil , nil
2023-03-28 19:23:25 +02:00
}
2024-01-12 17:49:02 +01:00
repoPerms [ blocker . RepoID ] = perm
2023-03-28 19:23:25 +02:00
}
2024-01-12 17:49:02 +01:00
if perm . CanReadIssuesOrPulls ( blocker . Issue . IsPull ) {
canRead = append ( canRead , blocker )
} else {
notPermitted = append ( notPermitted , blocker )
2023-03-28 19:23:25 +02:00
}
}
2024-01-12 17:49:02 +01:00
sortDependencyInfo ( canRead )
2023-03-28 19:23:25 +02:00
sortDependencyInfo ( notPermitted )
2024-01-12 17:49:02 +01:00
return canRead , notPermitted
2023-03-28 19:23:25 +02:00
}
func sortDependencyInfo ( blockers [ ] * issues_model . DependencyInfo ) {
sort . Slice ( blockers , func ( i , j int ) bool {
if blockers [ i ] . RepoID == blockers [ j ] . RepoID {
return blockers [ i ] . Issue . CreatedUnix < blockers [ j ] . Issue . CreatedUnix
}
return blockers [ i ] . RepoID < blockers [ j ] . RepoID
} )
}
2017-09-12 08:48:13 +02:00
// GetActionIssue will return the issue which is used in the context.
2022-06-13 11:37:59 +02:00
func GetActionIssue ( ctx * context . Context ) * issues_model . Issue {
2024-06-19 00:32:45 +02:00
issue , err := issues_model . GetIssueByIndex ( ctx , ctx . Repo . Repository . ID , ctx . PathParamInt64 ( ":index" ) )
2014-07-26 08:28:04 +02:00
if err != nil {
2022-06-13 11:37:59 +02:00
ctx . NotFoundOrServerError ( "GetIssueByIndex" , issues_model . IsErrIssueNotExist , err )
2017-10-16 09:55:43 +02:00
return nil
}
2018-12-13 16:55:43 +01:00
issue . Repo = ctx . Repo . Repository
2017-12-04 00:14:26 +01:00
checkIssueRights ( ctx , issue )
if ctx . Written ( ) {
2017-10-16 09:55:43 +02:00
return nil
}
2022-06-13 11:37:59 +02:00
if err = issue . LoadAttributes ( ctx ) ; err != nil {
2023-07-05 20:52:12 +02:00
ctx . ServerError ( "LoadAttributes" , err )
2015-08-19 17:14:57 +02:00
return nil
}
return issue
}
2022-06-13 11:37:59 +02:00
func checkIssueRights ( ctx * context . Context , issue * issues_model . Issue ) {
2021-11-09 20:57:58 +01:00
if issue . IsPull && ! ctx . Repo . CanRead ( unit . TypePullRequests ) ||
! issue . IsPull && ! ctx . Repo . CanRead ( unit . TypeIssues ) {
2018-01-10 22:34:17 +01:00
ctx . NotFound ( "IssueOrPullRequestUnitNotAllowed" , nil )
2017-12-04 00:14:26 +01:00
}
}
2023-06-24 17:31:28 +02:00
func getActionIssues ( ctx * context . Context ) issues_model . IssueList {
2021-08-11 02:31:13 +02:00
commaSeparatedIssueIDs := ctx . FormString ( "issue_ids" )
2017-03-15 02:10:35 +01:00
if len ( commaSeparatedIssueIDs ) == 0 {
return nil
}
issueIDs := make ( [ ] int64 , 0 , 10 )
for _ , stringIssueID := range strings . Split ( commaSeparatedIssueIDs , "," ) {
issueID , err := strconv . ParseInt ( stringIssueID , 10 , 64 )
if err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "ParseInt" , err )
2017-03-15 02:10:35 +01:00
return nil
}
issueIDs = append ( issueIDs , issueID )
}
2022-06-13 11:37:59 +02:00
issues , err := issues_model . GetIssuesByIDs ( ctx , issueIDs )
2017-03-15 02:10:35 +01:00
if err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "GetIssuesByIDs" , err )
2017-03-15 02:10:35 +01:00
return nil
}
2017-10-16 09:55:43 +02:00
// Check access rights for all issues
2021-11-09 20:57:58 +01:00
issueUnitEnabled := ctx . Repo . CanRead ( unit . TypeIssues )
prUnitEnabled := ctx . Repo . CanRead ( unit . TypePullRequests )
2017-10-16 09:55:43 +02:00
for _ , issue := range issues {
2022-06-30 17:55:08 +02:00
if issue . RepoID != ctx . Repo . Repository . ID {
ctx . NotFound ( "some issue's RepoID is incorrect" , errors . New ( "some issue's RepoID is incorrect" ) )
return nil
}
2017-10-16 09:55:43 +02:00
if issue . IsPull && ! prUnitEnabled || ! issue . IsPull && ! issueUnitEnabled {
2018-01-10 22:34:17 +01:00
ctx . NotFound ( "IssueOrPullRequestUnitNotAllowed" , nil )
2017-10-16 09:55:43 +02:00
return nil
}
2022-06-13 11:37:59 +02:00
if err = issue . LoadAttributes ( ctx ) ; err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "LoadAttributes" , err )
2017-10-16 09:55:43 +02:00
return nil
}
}
2017-03-15 02:10:35 +01:00
return issues
}
2022-04-07 20:59:56 +02:00
// GetIssueInfo get an issue of a repository
func GetIssueInfo ( ctx * context . Context ) {
2024-06-19 00:32:45 +02:00
issue , err := issues_model . GetIssueWithAttrsByIndex ( ctx , ctx . Repo . Repository . ID , ctx . PathParamInt64 ( ":index" ) )
2022-04-07 20:59:56 +02:00
if err != nil {
2022-06-13 11:37:59 +02:00
if issues_model . IsErrIssueNotExist ( err ) {
2022-04-07 20:59:56 +02:00
ctx . Error ( http . StatusNotFound )
} else {
ctx . Error ( http . StatusInternalServerError , "GetIssueByIndex" , err . Error ( ) )
}
return
}
2022-06-04 22:10:54 +02:00
if issue . IsPull {
// Need to check if Pulls are enabled and we can read Pulls
if ! ctx . Repo . Repository . CanEnablePulls ( ) || ! ctx . Repo . CanRead ( unit . TypePullRequests ) {
ctx . Error ( http . StatusNotFound )
return
}
} else {
// Need to check if Issues are enabled and we can read Issues
if ! ctx . Repo . CanRead ( unit . TypeIssues ) {
ctx . Error ( http . StatusNotFound )
return
}
}
2024-04-30 04:36:32 +02:00
ctx . JSON ( http . StatusOK , map [ string ] any {
"convertedIssue" : convert . ToIssue ( ctx , ctx . Doer , issue ) ,
"renderedLabels" : templates . RenderLabels ( ctx , ctx . Locale , issue . Labels , ctx . Repo . RepoLink , issue ) ,
} )
2022-04-07 20:59:56 +02:00
}
2016-11-24 08:04:31 +01:00
// UpdateIssueTitle change issue's title
2016-03-11 17:56:52 +01:00
func UpdateIssueTitle ( ctx * context . Context ) {
2017-09-12 08:48:13 +02:00
issue := GetActionIssue ( ctx )
2015-08-19 17:14:57 +02:00
if ctx . Written ( ) {
2014-07-26 08:28:04 +02:00
return
}
2022-03-22 08:03:22 +01:00
if ! ctx . IsSigned || ( ! issue . IsPoster ( ctx . Doer . ID ) && ! ctx . Repo . CanWriteIssuesOrPulls ( issue . IsPull ) ) {
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusForbidden )
2014-07-26 08:28:04 +02:00
return
}
2021-07-29 03:42:15 +02:00
title := ctx . FormTrim ( "title" )
2016-08-14 12:32:24 +02:00
if len ( title ) == 0 {
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusNoContent )
2015-08-19 17:14:57 +02:00
return
2014-07-26 08:28:04 +02:00
}
2015-08-19 17:14:57 +02:00
2023-04-14 20:18:28 +02:00
if err := issue_service . ChangeTitle ( ctx , issue , ctx . Doer , title ) ; err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "ChangeTitle" , err )
2014-07-26 08:28:04 +02:00
return
}
2023-07-04 20:36:08 +02:00
ctx . JSON ( http . StatusOK , map [ string ] any {
2016-08-14 12:32:24 +02:00
"title" : issue . Title ,
2014-07-26 08:28:04 +02:00
} )
}
2020-09-08 18:29:51 +02:00
// UpdateIssueRef change issue's ref (branch)
func UpdateIssueRef ( ctx * context . Context ) {
issue := GetActionIssue ( ctx )
if ctx . Written ( ) {
return
}
2022-03-22 08:03:22 +01:00
if ! ctx . IsSigned || ( ! issue . IsPoster ( ctx . Doer . ID ) && ! ctx . Repo . CanWriteIssuesOrPulls ( issue . IsPull ) ) || issue . IsPull {
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusForbidden )
2020-09-08 18:29:51 +02:00
return
}
2021-07-29 03:42:15 +02:00
ref := ctx . FormTrim ( "ref" )
2020-09-08 18:29:51 +02:00
2023-04-14 20:18:28 +02:00
if err := issue_service . ChangeIssueRef ( ctx , issue , ctx . Doer , ref ) ; err != nil {
2020-09-08 18:29:51 +02:00
ctx . ServerError ( "ChangeRef" , err )
return
}
2023-07-04 20:36:08 +02:00
ctx . JSON ( http . StatusOK , map [ string ] any {
2020-09-08 18:29:51 +02:00
"ref" : ref ,
} )
}
2016-11-24 08:04:31 +01:00
// UpdateIssueContent change issue's content
2016-03-11 17:56:52 +01:00
func UpdateIssueContent ( ctx * context . Context ) {
2017-09-12 08:48:13 +02:00
issue := GetActionIssue ( ctx )
2015-08-19 22:31:28 +02:00
if ctx . Written ( ) {
return
}
2022-03-22 08:03:22 +01:00
if ! ctx . IsSigned || ( ctx . Doer . ID != issue . PosterID && ! ctx . Repo . CanWriteIssuesOrPulls ( issue . IsPull ) ) {
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusForbidden )
2015-08-19 22:31:28 +02:00
return
}
2024-05-27 17:34:18 +02:00
if err := issue_service . ChangeContent ( ctx , issue , ctx . Doer , ctx . Req . FormValue ( "content" ) , ctx . FormInt ( "content_version" ) ) ; err != nil {
2024-03-04 09:16:03 +01:00
if errors . Is ( err , user_model . ErrBlockedUser ) {
ctx . JSONError ( ctx . Tr ( "repo.issues.edit.blocked_user" ) )
2024-05-27 17:34:18 +02:00
} else if errors . Is ( err , issues_model . ErrIssueAlreadyChanged ) {
if issue . IsPull {
ctx . JSONError ( ctx . Tr ( "repo.pulls.edit.already_changed" ) )
} else {
ctx . JSONError ( ctx . Tr ( "repo.issues.edit.already_changed" ) )
}
2024-03-04 09:16:03 +01:00
} else {
ctx . ServerError ( "ChangeContent" , err )
}
2015-08-19 22:31:28 +02:00
return
}
2021-08-21 15:04:47 +02:00
// when update the request doesn't intend to update attachments (eg: change checkbox state), ignore attachment updates
if ! ctx . FormBool ( "ignore_attachments" ) {
2022-05-20 16:08:52 +02:00
if err := updateAttachments ( ctx , issue , ctx . FormStrings ( "files[]" ) ) ; err != nil {
2021-08-21 15:04:47 +02:00
ctx . ServerError ( "UpdateAttachments" , err )
return
}
2021-04-20 00:25:08 +02:00
}
content , err := markdown . RenderString ( & markup . RenderContext {
2024-01-15 09:49:24 +01:00
Links : markup . Links {
Base : ctx . FormString ( "context" ) , // FIXME: <- IS THIS SAFE ?
} ,
Metas : ctx . Repo . Repository . ComposeMetas ( ctx ) ,
GitRepo : ctx . Repo . GitRepo ,
2024-05-30 09:04:01 +02:00
Repo : ctx . Repo . Repository ,
2024-01-15 09:49:24 +01:00
Ctx : ctx ,
2021-04-20 00:25:08 +02:00
} , issue . Content )
if err != nil {
ctx . ServerError ( "RenderString" , err )
return
2019-10-15 14:19:32 +02:00
}
2023-07-04 20:36:08 +02:00
ctx . JSON ( http . StatusOK , map [ string ] any {
2024-05-27 17:34:18 +02:00
"content" : content ,
"contentVersion" : issue . ContentVersion ,
"attachments" : attachmentsHTML ( ctx , issue . Attachments , issue . Content ) ,
2015-08-19 22:31:28 +02:00
} )
}
2022-04-07 20:59:56 +02:00
// UpdateIssueDeadline updates an issue deadline
func UpdateIssueDeadline ( ctx * context . Context ) {
form := web . GetForm ( ctx ) . ( * api . EditDeadlineOption )
2024-06-19 00:32:45 +02:00
issue , err := issues_model . GetIssueByIndex ( ctx , ctx . Repo . Repository . ID , ctx . PathParamInt64 ( ":index" ) )
2022-04-07 20:59:56 +02:00
if err != nil {
2022-06-13 11:37:59 +02:00
if issues_model . IsErrIssueNotExist ( err ) {
2022-04-07 20:59:56 +02:00
ctx . NotFound ( "GetIssueByIndex" , err )
} else {
ctx . Error ( http . StatusInternalServerError , "GetIssueByIndex" , err . Error ( ) )
}
return
}
if ! ctx . Repo . CanWriteIssuesOrPulls ( issue . IsPull ) {
ctx . Error ( http . StatusForbidden , "" , "Not repo writer" )
return
}
var deadlineUnix timeutil . TimeStamp
var deadline time . Time
if form . Deadline != nil && ! form . Deadline . IsZero ( ) {
deadline = time . Date ( form . Deadline . Year ( ) , form . Deadline . Month ( ) , form . Deadline . Day ( ) ,
23 , 59 , 59 , 0 , time . Local )
deadlineUnix = timeutil . TimeStamp ( deadline . Unix ( ) )
}
2023-09-29 14:12:54 +02:00
if err := issues_model . UpdateIssueDeadline ( ctx , issue , deadlineUnix , ctx . Doer ) ; err != nil {
2022-04-07 20:59:56 +02:00
ctx . Error ( http . StatusInternalServerError , "UpdateIssueDeadline" , err . Error ( ) )
return
}
ctx . JSON ( http . StatusCreated , api . IssueDeadline { Deadline : & deadline } )
}
2016-11-24 08:04:31 +01:00
// UpdateIssueMilestone change issue's milestone
2016-03-11 17:56:52 +01:00
func UpdateIssueMilestone ( ctx * context . Context ) {
2017-03-15 02:10:35 +01:00
issues := getActionIssues ( ctx )
2015-08-14 18:42:43 +02:00
if ctx . Written ( ) {
2014-07-26 08:28:04 +02:00
return
}
2021-07-29 03:42:15 +02:00
milestoneID := ctx . FormInt64 ( "id" )
2017-03-15 02:10:35 +01:00
for _ , issue := range issues {
oldMilestoneID := issue . MilestoneID
if oldMilestoneID == milestoneID {
continue
}
issue . MilestoneID = milestoneID
2023-10-11 06:24:07 +02:00
if err := issue_service . ChangeMilestoneAssign ( ctx , issue , ctx . Doer , oldMilestoneID ) ; err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "ChangeMilestoneAssign" , err )
2017-03-15 02:10:35 +01:00
return
}
2014-07-26 08:28:04 +02:00
}
2023-07-26 08:04:01 +02:00
ctx . JSONOK ( )
2014-07-26 08:28:04 +02:00
}
2019-10-25 16:46:37 +02:00
// UpdateIssueAssignee change issue's or pull's assignee
2016-03-11 17:56:52 +01:00
func UpdateIssueAssignee ( ctx * context . Context ) {
2017-03-15 02:10:35 +01:00
issues := getActionIssues ( ctx )
2015-08-14 18:42:43 +02:00
if ctx . Written ( ) {
2014-07-26 08:28:04 +02:00
return
}
2021-07-29 03:42:15 +02:00
assigneeID := ctx . FormInt64 ( "id" )
2021-08-11 02:31:13 +02:00
action := ctx . FormString ( "action" )
2018-05-09 18:29:04 +02:00
2017-03-15 02:10:35 +01:00
for _ , issue := range issues {
2018-05-09 18:29:04 +02:00
switch action {
case "clear" :
2023-04-14 20:18:28 +02:00
if err := issue_service . DeleteNotPassedAssignee ( ctx , issue , ctx . Doer , [ ] * user_model . User { } ) ; err != nil {
2018-05-09 18:29:04 +02:00
ctx . ServerError ( "ClearAssignees" , err )
return
}
default :
2022-12-03 03:48:26 +01:00
assignee , err := user_model . GetUserByID ( ctx , assigneeID )
2019-10-25 16:46:37 +02:00
if err != nil {
ctx . ServerError ( "GetUserByID" , err )
return
}
2022-05-11 12:09:36 +02:00
valid , err := access_model . CanBeAssigned ( ctx , assignee , issue . Repo , issue . IsPull )
2019-10-25 16:46:37 +02:00
if err != nil {
ctx . ServerError ( "canBeAssigned" , err )
2018-05-09 18:29:04 +02:00
return
}
2019-10-25 16:46:37 +02:00
if ! valid {
2022-06-13 11:37:59 +02:00
ctx . ServerError ( "canBeAssigned" , repo_model . ErrUserDoesNotHaveAccessToRepo { UserID : assigneeID , RepoName : issue . Repo . Name } )
2019-10-25 16:46:37 +02:00
return
}
2023-08-10 04:39:21 +02:00
_ , _ , err = issue_service . ToggleAssigneeWithNotify ( ctx , issue , ctx . Doer , assigneeID )
2019-10-25 16:46:37 +02:00
if err != nil {
ctx . ServerError ( "ToggleAssignee" , err )
return
}
2017-03-15 02:10:35 +01:00
}
2014-07-26 08:28:04 +02:00
}
2023-07-26 08:04:01 +02:00
ctx . JSONOK ( )
2017-03-15 02:10:35 +01:00
}
2014-07-26 08:28:04 +02:00
2020-10-12 21:55:13 +02:00
// UpdatePullReviewRequest add or remove review request
func UpdatePullReviewRequest ( ctx * context . Context ) {
2020-04-06 18:33:34 +02:00
issues := getActionIssues ( ctx )
if ctx . Written ( ) {
return
}
2021-07-29 03:42:15 +02:00
reviewID := ctx . FormInt64 ( "id" )
2021-08-11 02:31:13 +02:00
action := ctx . FormString ( "action" )
2020-04-06 18:33:34 +02:00
2020-09-02 18:55:13 +02:00
// TODO: Not support 'clear' now
if action != "attach" && action != "detach" {
2022-03-23 05:54:07 +01:00
ctx . Status ( http . StatusForbidden )
2020-04-06 18:33:34 +02:00
return
}
for _ , issue := range issues {
2022-04-08 11:11:15 +02:00
if err := issue . LoadRepo ( ctx ) ; err != nil {
2020-10-12 21:55:13 +02:00
ctx . ServerError ( "issue.LoadRepo" , err )
return
}
if ! issue . IsPull {
log . Warn (
"UpdatePullReviewRequest: refusing to add review request for non-PR issue %-v#%d" ,
issue . Repo , issue . Index ,
)
2022-03-23 05:54:07 +01:00
ctx . Status ( http . StatusForbidden )
2020-10-12 21:55:13 +02:00
return
}
if reviewID < 0 {
// negative reviewIDs represent team requests
2023-02-18 13:11:03 +01:00
if err := issue . Repo . LoadOwner ( ctx ) ; err != nil {
ctx . ServerError ( "issue.Repo.LoadOwner" , err )
2020-10-12 21:55:13 +02:00
return
}
if ! issue . Repo . Owner . IsOrganization ( ) {
log . Warn (
"UpdatePullReviewRequest: refusing to add team review request for %s#%d owned by non organization UID[%d]" ,
issue . Repo . FullName ( ) , issue . Index , issue . Repo . ID ,
)
2022-03-23 05:54:07 +01:00
ctx . Status ( http . StatusForbidden )
2020-10-12 21:55:13 +02:00
return
}
2020-04-06 18:33:34 +02:00
2022-05-20 16:08:52 +02:00
team , err := organization . GetTeamByID ( ctx , - reviewID )
2020-04-06 18:33:34 +02:00
if err != nil {
2022-03-29 08:29:02 +02:00
ctx . ServerError ( "GetTeamByID" , err )
2020-04-06 18:33:34 +02:00
return
}
2020-10-12 21:55:13 +02:00
if team . OrgID != issue . Repo . OwnerID {
log . Warn (
"UpdatePullReviewRequest: refusing to add team review request for UID[%d] team %s to %s#%d owned by UID[%d]" ,
team . OrgID , team . Name , issue . Repo . FullName ( ) , issue . Index , issue . Repo . ID )
2022-03-23 05:54:07 +01:00
ctx . Status ( http . StatusForbidden )
2020-10-12 21:55:13 +02:00
return
}
2022-04-28 13:48:48 +02:00
err = issue_service . IsValidTeamReviewRequest ( ctx , team , ctx . Doer , action == "attach" , issue )
2020-04-06 18:33:34 +02:00
if err != nil {
2022-06-13 11:37:59 +02:00
if issues_model . IsErrNotValidReviewRequest ( err ) {
2020-10-12 21:55:13 +02:00
log . Warn (
"UpdatePullReviewRequest: refusing to add invalid team review request for UID[%d] team %s to %s#%d owned by UID[%d]: Error: %v" ,
team . OrgID , team . Name , issue . Repo . FullName ( ) , issue . Index , issue . Repo . ID ,
err ,
)
2022-03-23 05:54:07 +01:00
ctx . Status ( http . StatusForbidden )
2020-10-12 21:55:13 +02:00
return
}
2020-10-20 20:18:25 +02:00
ctx . ServerError ( "IsValidTeamReviewRequest" , err )
2020-04-06 18:33:34 +02:00
return
}
2023-04-14 20:18:28 +02:00
_ , err = issue_service . TeamReviewRequest ( ctx , issue , ctx . Doer , team , action == "attach" )
2020-04-06 18:33:34 +02:00
if err != nil {
2020-10-12 21:55:13 +02:00
ctx . ServerError ( "TeamReviewRequest" , err )
2020-04-06 18:33:34 +02:00
return
}
2020-10-12 21:55:13 +02:00
continue
}
2022-12-03 03:48:26 +01:00
reviewer , err := user_model . GetUserByID ( ctx , reviewID )
2020-10-12 21:55:13 +02:00
if err != nil {
2021-11-24 10:49:20 +01:00
if user_model . IsErrUserNotExist ( err ) {
2020-10-12 21:55:13 +02:00
log . Warn (
"UpdatePullReviewRequest: requested reviewer [%d] for %-v to %-v#%d is not exist: Error: %v" ,
reviewID , issue . Repo , issue . Index ,
err ,
)
2022-03-23 05:54:07 +01:00
ctx . Status ( http . StatusForbidden )
2020-10-12 21:55:13 +02:00
return
}
ctx . ServerError ( "GetUserByID" , err )
return
}
2022-04-28 13:48:48 +02:00
err = issue_service . IsValidReviewRequest ( ctx , reviewer , ctx . Doer , action == "attach" , issue , nil )
2020-10-12 21:55:13 +02:00
if err != nil {
2022-06-13 11:37:59 +02:00
if issues_model . IsErrNotValidReviewRequest ( err ) {
2020-10-12 21:55:13 +02:00
log . Warn (
"UpdatePullReviewRequest: refusing to add invalid review request for %-v to %-v#%d: Error: %v" ,
reviewer , issue . Repo , issue . Index ,
err ,
)
2022-03-23 05:54:07 +01:00
ctx . Status ( http . StatusForbidden )
2020-10-12 21:55:13 +02:00
return
}
ctx . ServerError ( "isValidReviewRequest" , err )
return
}
2023-04-14 20:18:28 +02:00
_ , err = issue_service . ReviewRequest ( ctx , issue , ctx . Doer , reviewer , action == "attach" )
2020-10-12 21:55:13 +02:00
if err != nil {
2024-03-28 16:19:24 +01:00
if issues_model . IsErrReviewRequestOnClosedPR ( err ) {
ctx . Status ( http . StatusForbidden )
return
}
2020-10-12 21:55:13 +02:00
ctx . ServerError ( "ReviewRequest" , err )
2020-09-02 18:55:13 +02:00
return
2020-04-06 18:33:34 +02:00
}
}
2023-07-26 08:04:01 +02:00
ctx . JSONOK ( )
2020-04-06 18:33:34 +02:00
}
2022-04-07 20:59:56 +02:00
// SearchIssues searches for issues across the repositories that the user has access to
func SearchIssues ( ctx * context . Context ) {
2023-05-21 03:50:53 +02:00
before , since , err := context . GetQueryBeforeSince ( ctx . Base )
2022-04-07 20:59:56 +02:00
if err != nil {
ctx . Error ( http . StatusUnprocessableEntity , err . Error ( ) )
return
}
2024-03-02 16:42:31 +01:00
var isClosed optional . Option [ bool ]
2022-04-07 20:59:56 +02:00
switch ctx . FormString ( "state" ) {
case "closed" :
2024-03-02 16:42:31 +01:00
isClosed = optional . Some ( true )
2022-04-07 20:59:56 +02:00
case "all" :
2024-03-02 16:42:31 +01:00
isClosed = optional . None [ bool ] ( )
2022-04-07 20:59:56 +02:00
default :
2024-03-02 16:42:31 +01:00
isClosed = optional . Some ( false )
2022-04-07 20:59:56 +02:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
var (
repoIDs [ ] int64
allPublic bool
)
{
// find repos user can access (for issue search)
opts := & repo_model . SearchRepoOptions {
Private : false ,
AllPublic : true ,
TopicOnly : false ,
2024-02-29 19:52:49 +01:00
Collaborate : optional . None [ bool ] ( ) ,
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
// This needs to be a column that is not nil in fixtures or
// MySQL will return different results when sorting by null in some cases
OrderBy : db . SearchOrderByAlphabetically ,
Actor : ctx . Doer ,
}
if ctx . IsSigned {
opts . Private = true
opts . AllLimited = true
}
if ctx . FormString ( "owner" ) != "" {
owner , err := user_model . GetUserByName ( ctx , ctx . FormString ( "owner" ) )
if err != nil {
if user_model . IsErrUserNotExist ( err ) {
ctx . Error ( http . StatusBadRequest , "Owner not found" , err . Error ( ) )
} else {
ctx . Error ( http . StatusInternalServerError , "GetUserByName" , err . Error ( ) )
}
return
2022-04-07 20:59:56 +02:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
opts . OwnerID = owner . ID
opts . AllLimited = false
opts . AllPublic = false
2024-02-29 19:52:49 +01:00
opts . Collaborate = optional . Some ( false )
2022-04-07 20:59:56 +02:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
if ctx . FormString ( "team" ) != "" {
if ctx . FormString ( "owner" ) == "" {
ctx . Error ( http . StatusBadRequest , "" , "Owner organisation is required for filtering on team" )
return
}
team , err := organization . GetTeam ( ctx , opts . OwnerID , ctx . FormString ( "team" ) )
if err != nil {
if organization . IsErrTeamNotExist ( err ) {
ctx . Error ( http . StatusBadRequest , "Team not found" , err . Error ( ) )
} else {
ctx . Error ( http . StatusInternalServerError , "GetUserByName" , err . Error ( ) )
}
return
}
opts . TeamID = team . ID
}
if opts . AllPublic {
allPublic = true
opts . AllPublic = false // set it false to avoid returning too many repos, we could filter by indexer
2022-04-07 20:59:56 +02:00
}
2023-10-11 06:24:07 +02:00
repoIDs , _ , err = repo_model . SearchRepositoryIDs ( ctx , opts )
2022-04-07 20:59:56 +02:00
if err != nil {
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
ctx . Error ( http . StatusInternalServerError , "SearchRepositoryIDs" , err . Error ( ) )
2022-04-07 20:59:56 +02:00
return
}
2023-08-17 19:42:17 +02:00
if len ( repoIDs ) == 0 {
// no repos found, don't let the indexer return all repos
repoIDs = [ ] int64 { 0 }
}
2022-04-07 20:59:56 +02:00
}
keyword := ctx . FormTrim ( "q" )
if strings . IndexByte ( keyword , 0 ) >= 0 {
keyword = ""
}
2024-03-02 16:42:31 +01:00
isPull := optional . None [ bool ] ( )
2022-04-07 20:59:56 +02:00
switch ctx . FormString ( "type" ) {
case "pulls" :
2024-03-02 16:42:31 +01:00
isPull = optional . Some ( true )
2022-04-07 20:59:56 +02:00
case "issues" :
2024-03-02 16:42:31 +01:00
isPull = optional . Some ( false )
2022-04-07 20:59:56 +02:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
var includedAnyLabels [ ] int64
{
labels := ctx . FormTrim ( "labels" )
var includedLabelNames [ ] string
if len ( labels ) > 0 {
includedLabelNames = strings . Split ( labels , "," )
}
includedAnyLabels , err = issues_model . GetLabelIDsByNames ( ctx , includedLabelNames )
if err != nil {
ctx . Error ( http . StatusInternalServerError , "GetLabelIDsByNames" , err . Error ( ) )
return
}
2022-04-07 20:59:56 +02:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
var includedMilestones [ ] int64
{
milestones := ctx . FormTrim ( "milestones" )
var includedMilestoneNames [ ] string
if len ( milestones ) > 0 {
includedMilestoneNames = strings . Split ( milestones , "," )
}
includedMilestones , err = issues_model . GetMilestoneIDsByNames ( ctx , includedMilestoneNames )
if err != nil {
ctx . Error ( http . StatusInternalServerError , "GetMilestoneIDsByNames" , err . Error ( ) )
return
}
2022-04-07 20:59:56 +02:00
}
2024-03-13 09:25:53 +01:00
projectID := optional . None [ int64 ] ( )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
if v := ctx . FormInt64 ( "project" ) ; v > 0 {
2024-03-13 09:25:53 +01:00
projectID = optional . Some ( v )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
2023-01-29 04:45:29 +01:00
2022-04-07 20:59:56 +02:00
// this api is also used in UI,
// so the default limit is set to fit UI needs
limit := ctx . FormInt ( "limit" )
if limit == 0 {
limit = setting . UI . IssuePagingNum
} else if limit > setting . API . MaxResponseItems {
limit = setting . API . MaxResponseItems
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
searchOpt := & issue_indexer . SearchOptions {
Paginator : & db . ListOptions {
Page : ctx . FormInt ( "page" ) ,
PageSize : limit ,
} ,
Keyword : keyword ,
RepoIDs : repoIDs ,
AllPublic : allPublic ,
IsPull : isPull ,
IsClosed : isClosed ,
IncludedAnyLabelIDs : includedAnyLabels ,
MilestoneIDs : includedMilestones ,
ProjectID : projectID ,
SortBy : issue_indexer . SortByCreatedDesc ,
}
2022-04-07 20:59:56 +02:00
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
if since != 0 {
2024-03-13 09:25:53 +01:00
searchOpt . UpdatedAfterUnix = optional . Some ( since )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
if before != 0 {
2024-03-13 09:25:53 +01:00
searchOpt . UpdatedBeforeUnix = optional . Some ( before )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
if ctx . IsSigned {
ctxUserID := ctx . Doer . ID
2022-04-07 20:59:56 +02:00
if ctx . FormBool ( "created" ) {
2024-03-13 09:25:53 +01:00
searchOpt . PosterID = optional . Some ( ctxUserID )
2022-04-07 20:59:56 +02:00
}
if ctx . FormBool ( "assigned" ) {
2024-03-13 09:25:53 +01:00
searchOpt . AssigneeID = optional . Some ( ctxUserID )
2022-04-07 20:59:56 +02:00
}
if ctx . FormBool ( "mentioned" ) {
2024-03-13 09:25:53 +01:00
searchOpt . MentionID = optional . Some ( ctxUserID )
2022-04-07 20:59:56 +02:00
}
if ctx . FormBool ( "review_requested" ) {
2024-03-13 09:25:53 +01:00
searchOpt . ReviewRequestedID = optional . Some ( ctxUserID )
2022-04-07 20:59:56 +02:00
}
2023-02-25 03:55:50 +01:00
if ctx . FormBool ( "reviewed" ) {
2024-03-13 09:25:53 +01:00
searchOpt . ReviewedID = optional . Some ( ctxUserID )
2023-02-25 03:55:50 +01:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
2022-04-07 20:59:56 +02:00
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
// FIXME: It's unsupported to sort by priority repo when searching by indexer,
// it's indeed an regression, but I think it is worth to support filtering by indexer first.
_ = ctx . FormInt64 ( "priority_repo_id" )
2022-04-07 20:59:56 +02:00
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
ids , total , err := issue_indexer . SearchIssues ( ctx , searchOpt )
if err != nil {
ctx . Error ( http . StatusInternalServerError , "SearchIssues" , err . Error ( ) )
return
}
issues , err := issues_model . GetIssuesByIDs ( ctx , ids , true )
if err != nil {
ctx . Error ( http . StatusInternalServerError , "FindIssuesByIDs" , err . Error ( ) )
return
2022-04-07 20:59:56 +02:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
ctx . SetTotalCountHeader ( total )
2024-04-08 23:26:41 +02:00
ctx . JSON ( http . StatusOK , convert . ToIssueList ( ctx , ctx . Doer , issues ) )
2022-04-07 20:59:56 +02:00
}
func getUserIDForFilter ( ctx * context . Context , queryName string ) int64 {
userName := ctx . FormString ( queryName )
if len ( userName ) == 0 {
return 0
}
2022-05-20 16:08:52 +02:00
user , err := user_model . GetUserByName ( ctx , userName )
2022-04-07 20:59:56 +02:00
if user_model . IsErrUserNotExist ( err ) {
ctx . NotFound ( "" , err )
return 0
}
if err != nil {
ctx . Error ( http . StatusInternalServerError , err . Error ( ) )
return 0
}
return user . ID
}
// ListIssues list the issues of a repository
func ListIssues ( ctx * context . Context ) {
2023-05-21 03:50:53 +02:00
before , since , err := context . GetQueryBeforeSince ( ctx . Base )
2022-04-07 20:59:56 +02:00
if err != nil {
ctx . Error ( http . StatusUnprocessableEntity , err . Error ( ) )
return
}
2024-03-02 16:42:31 +01:00
var isClosed optional . Option [ bool ]
2022-04-07 20:59:56 +02:00
switch ctx . FormString ( "state" ) {
case "closed" :
2024-03-02 16:42:31 +01:00
isClosed = optional . Some ( true )
2022-04-07 20:59:56 +02:00
case "all" :
2024-03-02 16:42:31 +01:00
isClosed = optional . None [ bool ] ( )
2022-04-07 20:59:56 +02:00
default :
2024-03-02 16:42:31 +01:00
isClosed = optional . Some ( false )
2022-04-07 20:59:56 +02:00
}
keyword := ctx . FormTrim ( "q" )
if strings . IndexByte ( keyword , 0 ) >= 0 {
keyword = ""
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
var labelIDs [ ] int64
2022-04-07 20:59:56 +02:00
if splitted := strings . Split ( ctx . FormString ( "labels" ) , "," ) ; len ( splitted ) > 0 {
2023-09-16 16:39:12 +02:00
labelIDs , err = issues_model . GetLabelIDsInRepoByNames ( ctx , ctx . Repo . Repository . ID , splitted )
2022-04-07 20:59:56 +02:00
if err != nil {
ctx . Error ( http . StatusInternalServerError , err . Error ( ) )
return
}
}
var mileIDs [ ] int64
if part := strings . Split ( ctx . FormString ( "milestones" ) , "," ) ; len ( part ) > 0 {
for i := range part {
// uses names and fall back to ids
// non existent milestones are discarded
2023-09-16 16:39:12 +02:00
mile , err := issues_model . GetMilestoneByRepoIDANDName ( ctx , ctx . Repo . Repository . ID , part [ i ] )
2022-04-07 20:59:56 +02:00
if err == nil {
mileIDs = append ( mileIDs , mile . ID )
continue
}
2022-04-08 11:11:15 +02:00
if ! issues_model . IsErrMilestoneNotExist ( err ) {
2022-04-07 20:59:56 +02:00
ctx . Error ( http . StatusInternalServerError , err . Error ( ) )
return
}
id , err := strconv . ParseInt ( part [ i ] , 10 , 64 )
if err != nil {
continue
}
2022-04-08 11:11:15 +02:00
mile , err = issues_model . GetMilestoneByRepoID ( ctx , ctx . Repo . Repository . ID , id )
2022-04-07 20:59:56 +02:00
if err == nil {
mileIDs = append ( mileIDs , mile . ID )
continue
}
2022-04-08 11:11:15 +02:00
if issues_model . IsErrMilestoneNotExist ( err ) {
2022-04-07 20:59:56 +02:00
continue
}
ctx . Error ( http . StatusInternalServerError , err . Error ( ) )
}
}
2024-03-13 09:25:53 +01:00
projectID := optional . None [ int64 ] ( )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
if v := ctx . FormInt64 ( "project" ) ; v > 0 {
2024-03-13 09:25:53 +01:00
projectID = optional . Some ( v )
2022-04-07 20:59:56 +02:00
}
2024-03-02 16:42:31 +01:00
isPull := optional . None [ bool ] ( )
2022-04-07 20:59:56 +02:00
switch ctx . FormString ( "type" ) {
case "pulls" :
2024-03-02 16:42:31 +01:00
isPull = optional . Some ( true )
2022-04-07 20:59:56 +02:00
case "issues" :
2024-03-02 16:42:31 +01:00
isPull = optional . Some ( false )
2022-04-07 20:59:56 +02:00
}
// FIXME: we should be more efficient here
createdByID := getUserIDForFilter ( ctx , "created_by" )
if ctx . Written ( ) {
return
}
assignedByID := getUserIDForFilter ( ctx , "assigned_by" )
if ctx . Written ( ) {
return
}
mentionedByID := getUserIDForFilter ( ctx , "mentioned_by" )
if ctx . Written ( ) {
return
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
searchOpt := & issue_indexer . SearchOptions {
Paginator : & db . ListOptions {
Page : ctx . FormInt ( "page" ) ,
PageSize : convert . ToCorrectPageSize ( ctx . FormInt ( "limit" ) ) ,
} ,
2024-05-27 10:59:54 +02:00
Keyword : keyword ,
RepoIDs : [ ] int64 { ctx . Repo . Repository . ID } ,
IsPull : isPull ,
IsClosed : isClosed ,
ProjectID : projectID ,
SortBy : issue_indexer . SortByCreatedDesc ,
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
if since != 0 {
2024-03-13 09:25:53 +01:00
searchOpt . UpdatedAfterUnix = optional . Some ( since )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
if before != 0 {
2024-03-13 09:25:53 +01:00
searchOpt . UpdatedBeforeUnix = optional . Some ( before )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
if len ( labelIDs ) == 1 && labelIDs [ 0 ] == 0 {
searchOpt . NoLabelOnly = true
} else {
for _ , labelID := range labelIDs {
if labelID > 0 {
searchOpt . IncludedLabelIDs = append ( searchOpt . IncludedLabelIDs , labelID )
} else {
searchOpt . ExcludedLabelIDs = append ( searchOpt . ExcludedLabelIDs , - labelID )
}
2022-04-07 20:59:56 +02:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
2022-04-07 20:59:56 +02:00
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
if len ( mileIDs ) == 1 && mileIDs [ 0 ] == db . NoConditionID {
searchOpt . MilestoneIDs = [ ] int64 { 0 }
} else {
searchOpt . MilestoneIDs = mileIDs
}
2022-04-07 20:59:56 +02:00
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
if createdByID > 0 {
2024-03-13 09:25:53 +01:00
searchOpt . PosterID = optional . Some ( createdByID )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
if assignedByID > 0 {
2024-03-13 09:25:53 +01:00
searchOpt . AssigneeID = optional . Some ( assignedByID )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
if mentionedByID > 0 {
2024-03-13 09:25:53 +01:00
searchOpt . MentionID = optional . Some ( mentionedByID )
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
}
ids , total , err := issue_indexer . SearchIssues ( ctx , searchOpt )
if err != nil {
ctx . Error ( http . StatusInternalServerError , "SearchIssues" , err . Error ( ) )
return
}
issues , err := issues_model . GetIssuesByIDs ( ctx , ids , true )
if err != nil {
ctx . Error ( http . StatusInternalServerError , "FindIssuesByIDs" , err . Error ( ) )
return
2022-04-07 20:59:56 +02:00
}
Refactor and enhance issue indexer to support both searching, filtering and paging (#26012)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
2023-07-31 08:28:53 +02:00
ctx . SetTotalCountHeader ( total )
2024-04-08 23:26:41 +02:00
ctx . JSON ( http . StatusOK , convert . ToIssueList ( ctx , ctx . Doer , issues ) )
2022-04-07 20:59:56 +02:00
}
2023-06-19 09:46:50 +02:00
func BatchDeleteIssues ( ctx * context . Context ) {
issues := getActionIssues ( ctx )
if ctx . Written ( ) {
return
}
for _ , issue := range issues {
if err := issue_service . DeleteIssue ( ctx , ctx . Doer , ctx . Repo . GitRepo , issue ) ; err != nil {
ctx . ServerError ( "DeleteIssue" , err )
return
}
}
ctx . JSONOK ( )
}
2017-03-15 02:10:35 +01:00
// UpdateIssueStatus change issue's status
func UpdateIssueStatus ( ctx * context . Context ) {
issues := getActionIssues ( ctx )
if ctx . Written ( ) {
2014-07-26 08:28:04 +02:00
return
}
2017-03-15 02:10:35 +01:00
var isClosed bool
2021-08-11 02:31:13 +02:00
switch action := ctx . FormString ( "action" ) ; action {
2017-03-15 02:10:35 +01:00
case "open" :
isClosed = false
case "close" :
isClosed = true
default :
log . Warn ( "Unrecognized action: %s" , action )
}
2023-06-24 17:31:28 +02:00
if _ , err := issues . LoadRepositories ( ctx ) ; err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "LoadRepositories" , err )
2017-03-15 02:10:35 +01:00
return
}
2023-07-16 00:10:49 +02:00
if err := issues . LoadPullRequests ( ctx ) ; err != nil {
ctx . ServerError ( "LoadPullRequests" , err )
return
}
2017-03-15 02:10:35 +01:00
for _ , issue := range issues {
2023-07-16 00:10:49 +02:00
if issue . IsPull && issue . PullRequest . HasMerged {
continue
}
2018-10-18 13:23:05 +02:00
if issue . IsClosed != isClosed {
2023-07-22 16:14:27 +02:00
if err := issue_service . ChangeStatus ( ctx , issue , ctx . Doer , "" , isClosed ) ; err != nil {
2022-06-13 11:37:59 +02:00
if issues_model . IsErrDependenciesLeft ( err ) {
2023-07-04 20:36:08 +02:00
ctx . JSON ( http . StatusPreconditionFailed , map [ string ] any {
2023-04-26 18:54:17 +02:00
"error" : ctx . Tr ( "repo.issues.dependency.issue_batch_close_blocked" , issue . Index ) ,
2018-10-18 13:23:05 +02:00
} )
return
}
ctx . ServerError ( "ChangeStatus" , err )
2018-07-17 23:23:58 +02:00
return
}
2017-03-15 02:10:35 +01:00
}
}
2023-06-19 09:46:50 +02:00
ctx . JSONOK ( )
2014-07-26 08:28:04 +02:00
}
2016-11-24 08:04:31 +01:00
// NewComment create a comment for issue
2021-01-26 16:36:53 +01:00
func NewComment ( ctx * context . Context ) {
2021-04-06 21:44:05 +02:00
form := web . GetForm ( ctx ) . ( * forms . CreateCommentForm )
2017-10-16 09:55:43 +02:00
issue := GetActionIssue ( ctx )
if ctx . Written ( ) {
2014-07-26 08:28:04 +02:00
return
}
2022-03-22 08:03:22 +01:00
if ! ctx . IsSigned || ( ctx . Doer . ID != issue . PosterID && ! ctx . Repo . CanReadIssuesOrPulls ( issue . IsPull ) ) {
2019-04-22 22:40:51 +02:00
if log . IsTrace ( ) {
if ctx . IsSigned {
issueType := "issues"
if issue . IsPull {
issueType = "pulls"
}
log . Trace ( "Permission Denied: User %-v not the Poster (ID: %d) and cannot read %s in Repo %-v.\n" +
"User in Repo has Permissions: %-+v" ,
2022-03-22 08:03:22 +01:00
ctx . Doer ,
Rewrite logger system (#24726)
## ⚠️ Breaking
The `log.<mode>.<logger>` style config has been dropped. If you used it,
please check the new config manual & app.example.ini to make your
instance output logs as expected.
Although many legacy options still work, it's encouraged to upgrade to
the new options.
The SMTP logger is deleted because SMTP is not suitable to collect logs.
If you have manually configured Gitea log options, please confirm the
logger system works as expected after upgrading.
## Description
Close #12082 and maybe more log-related issues, resolve some related
FIXMEs in old code (which seems unfixable before)
Just like rewriting queue #24505 : make code maintainable, clear legacy
bugs, and add the ability to support more writers (eg: JSON, structured
log)
There is a new document (with examples): `logging-config.en-us.md`
This PR is safer than the queue rewriting, because it's just for
logging, it won't break other logic.
## The old problems
The logging system is quite old and difficult to maintain:
* Unclear concepts: Logger, NamedLogger, MultiChannelledLogger,
SubLogger, EventLogger, WriterLogger etc
* Some code is diffuclt to konw whether it is right:
`log.DelNamedLogger("console")` vs `log.DelNamedLogger(log.DEFAULT)` vs
`log.DelLogger("console")`
* The old system heavily depends on ini config system, it's difficult to
create new logger for different purpose, and it's very fragile.
* The "color" trick is difficult to use and read, many colors are
unnecessary, and in the future structured log could help
* It's difficult to add other log formats, eg: JSON format
* The log outputer doesn't have full control of its goroutine, it's
difficult to make outputer have advanced behaviors
* The logs could be lost in some cases: eg: no Fatal error when using
CLI.
* Config options are passed by JSON, which is quite fragile.
* INI package makes the KEY in `[log]` section visible in `[log.sub1]`
and `[log.sub1.subA]`, this behavior is quite fragile and would cause
more unclear problems, and there is no strong requirement to support
`log.<mode>.<logger>` syntax.
## The new design
See `logger.go` for documents.
## Screenshot
<details>



</details>
## TODO
* [x] add some new tests
* [x] fix some tests
* [x] test some sub-commands (manually ....)
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Giteabot <teabot@gitea.io>
2023-05-22 00:35:11 +02:00
issue . PosterID ,
2019-04-22 22:40:51 +02:00
issueType ,
ctx . Repo . Repository ,
ctx . Repo . Permission )
} else {
log . Trace ( "Permission Denied: Not logged in" )
}
}
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusForbidden )
2020-01-20 13:00:32 +01:00
return
2019-02-18 21:55:04 +01:00
}
2022-03-22 08:03:22 +01:00
if issue . IsLocked && ! ctx . Repo . CanWriteIssuesOrPulls ( issue . IsPull ) && ! ctx . Doer . IsAdmin {
2023-06-16 08:32:43 +02:00
ctx . JSONError ( ctx . Tr ( "repo.issues.comment_on_locked" ) )
2018-11-28 12:26:14 +01:00
return
}
2015-08-13 10:07:11 +02:00
var attachments [ ] string
2020-08-18 06:23:45 +02:00
if setting . Attachment . Enabled {
2016-08-11 14:48:08 +02:00
attachments = form . Files
2014-07-26 08:28:04 +02:00
}
2015-08-13 10:07:11 +02:00
if ctx . HasError ( ) {
2023-06-16 08:32:43 +02:00
ctx . JSONError ( ctx . GetErrMsg ( ) )
2015-08-13 10:07:11 +02:00
return
2014-07-26 08:28:04 +02:00
}
2022-06-13 11:37:59 +02:00
var comment * issues_model . Comment
2015-09-13 17:26:25 +02:00
defer func ( ) {
2015-10-31 23:59:07 +01:00
// Check if issue admin/poster changes the status of issue.
2022-03-22 08:03:22 +01:00
if ( ctx . Repo . CanWriteIssuesOrPulls ( issue . IsPull ) || ( ctx . IsSigned && issue . IsPoster ( ctx . Doer . ID ) ) ) &&
2015-09-13 17:26:25 +02:00
( form . Status == "reopen" || form . Status == "close" ) &&
2016-08-16 19:19:09 +02:00
! ( issue . IsPull && issue . PullRequest . HasMerged ) {
2015-10-25 08:10:22 +01:00
// Duplication and conflict check should apply to reopen pull request.
2022-06-13 11:37:59 +02:00
var pr * issues_model . PullRequest
2015-10-19 01:30:39 +02:00
2015-10-23 16:31:13 +02:00
if form . Status == "reopen" && issue . IsPull {
2015-10-19 01:30:39 +02:00
pull := issue . PullRequest
2019-06-12 21:41:28 +02:00
var err error
2022-11-19 09:12:33 +01:00
pr , err = issues_model . GetUnmergedPullRequest ( ctx , pull . HeadRepoID , pull . BaseRepoID , pull . HeadBranch , pull . BaseBranch , pull . Flow )
2015-10-19 01:30:39 +02:00
if err != nil {
2022-06-13 11:37:59 +02:00
if ! issues_model . IsErrPullRequestNotExist ( err ) {
2023-06-16 08:32:43 +02:00
ctx . JSONError ( ctx . Tr ( "repo.issues.dependency.pr_close_blocked" ) )
2015-10-19 01:30:39 +02:00
return
}
}
2015-10-25 08:10:22 +01:00
// Regenerate patch and test conflict.
if pr == nil {
2021-07-28 11:42:56 +02:00
issue . PullRequest . HeadCommitID = ""
2023-07-22 16:14:27 +02:00
pull_service . AddToTaskQueue ( ctx , issue . PullRequest )
2015-10-25 08:10:22 +01:00
}
2023-05-08 08:39:32 +02:00
// check whether the ref of PR <refs/pulls/pr_index/head> in base repo is consistent with the head commit of head branch in the head repo
// get head commit of PR
2023-08-19 11:29:34 +02:00
if pull . Flow == issues_model . PullRequestFlowGithub {
prHeadRef := pull . GetGitRefName ( )
if err := pull . LoadBaseRepo ( ctx ) ; err != nil {
ctx . ServerError ( "Unable to load base repo" , err )
return
}
prHeadCommitID , err := git . GetFullCommitID ( ctx , pull . BaseRepo . RepoPath ( ) , prHeadRef )
if err != nil {
ctx . ServerError ( "Get head commit Id of pr fail" , err )
return
}
2023-05-08 08:39:32 +02:00
2023-08-19 11:29:34 +02:00
// get head commit of branch in the head repo
if err := pull . LoadHeadRepo ( ctx ) ; err != nil {
ctx . ServerError ( "Unable to load head repo" , err )
return
}
if ok := git . IsBranchExist ( ctx , pull . HeadRepo . RepoPath ( ) , pull . BaseBranch ) ; ! ok {
// todo localize
ctx . JSONError ( "The origin branch is delete, cannot reopen." )
return
}
headBranchRef := pull . GetGitHeadBranchRefName ( )
headBranchCommitID , err := git . GetFullCommitID ( ctx , pull . HeadRepo . RepoPath ( ) , headBranchRef )
if err != nil {
ctx . ServerError ( "Get head commit Id of head branch fail" , err )
return
}
2023-05-08 08:39:32 +02:00
2023-08-19 11:29:34 +02:00
err = pull . LoadIssue ( ctx )
2023-05-08 08:39:32 +02:00
if err != nil {
2023-08-19 11:29:34 +02:00
ctx . ServerError ( "load the issue of pull request error" , err )
2023-05-08 08:39:32 +02:00
return
}
2023-08-19 11:29:34 +02:00
if prHeadCommitID != headBranchCommitID {
// force push to base repo
err := git . Push ( ctx , pull . HeadRepo . RepoPath ( ) , git . PushOptions {
Remote : pull . BaseRepo . RepoPath ( ) ,
Branch : pull . HeadBranch + ":" + prHeadRef ,
Force : true ,
Env : repo_module . InternalPushingEnvironment ( pull . Issue . Poster , pull . BaseRepo ) ,
} )
if err != nil {
ctx . ServerError ( "force push error" , err )
return
}
}
2023-05-08 08:39:32 +02:00
}
2015-10-19 01:30:39 +02:00
}
if pr != nil {
ctx . Flash . Info ( ctx . Tr ( "repo.pulls.open_unmerged_pull_exists" , pr . Index ) )
2015-09-13 17:26:25 +02:00
} else {
2018-10-18 13:23:05 +02:00
isClosed := form . Status == "close"
2023-07-22 16:14:27 +02:00
if err := issue_service . ChangeStatus ( ctx , issue , ctx . Doer , "" , isClosed ) ; err != nil {
2019-04-02 09:48:31 +02:00
log . Error ( "ChangeStatus: %v" , err )
2018-07-17 23:23:58 +02:00
2022-06-13 11:37:59 +02:00
if issues_model . IsErrDependenciesLeft ( err ) {
2018-07-17 23:23:58 +02:00
if issue . IsPull {
2023-06-16 08:32:43 +02:00
ctx . JSONError ( ctx . Tr ( "repo.issues.dependency.pr_close_blocked" ) )
2018-07-17 23:23:58 +02:00
} else {
2023-06-16 08:32:43 +02:00
ctx . JSONError ( ctx . Tr ( "repo.issues.dependency.issue_close_blocked" ) )
2018-07-17 23:23:58 +02:00
}
return
}
2015-10-19 01:30:39 +02:00
} else {
2023-09-16 16:39:12 +02:00
if err := stopTimerIfAvailable ( ctx , ctx . Doer , issue ) ; err != nil {
2019-02-05 12:38:11 +01:00
ctx . ServerError ( "CreateOrStopIssueStopwatch" , err )
return
}
2016-02-22 18:40:00 +01:00
log . Trace ( "Issue [%d] status changed to closed: %v" , issue . ID , issue . IsClosed )
2015-10-19 01:30:39 +02:00
}
2015-09-13 17:26:25 +02:00
}
}
2015-10-19 01:30:39 +02:00
// Redirect to comment hashtag if there is any actual content.
typeName := "issues"
if issue . IsPull {
typeName = "pulls"
}
if comment != nil {
2023-06-16 08:32:43 +02:00
ctx . JSONRedirect ( fmt . Sprintf ( "%s/%s/%d#%s" , ctx . Repo . RepoLink , typeName , issue . Index , comment . HashTag ( ) ) )
2015-10-19 01:30:39 +02:00
} else {
2023-06-16 08:32:43 +02:00
ctx . JSONRedirect ( fmt . Sprintf ( "%s/%s/%d" , ctx . Repo . RepoLink , typeName , issue . Index ) )
2015-10-19 01:30:39 +02:00
}
2015-09-13 17:26:25 +02:00
} ( )
2015-08-13 10:07:11 +02:00
// Fix #321: Allow empty comments, as long as we have attachments.
if len ( form . Content ) == 0 && len ( attachments ) == 0 {
return
2014-07-26 08:28:04 +02:00
}
2022-12-10 03:46:31 +01:00
comment , err := issue_service . CreateIssueComment ( ctx , ctx . Doer , ctx . Repo . Repository , issue , form . Content , attachments )
2015-08-13 10:07:11 +02:00
if err != nil {
2024-03-04 09:16:03 +01:00
if errors . Is ( err , user_model . ErrBlockedUser ) {
ctx . JSONError ( ctx . Tr ( "repo.issues.comment.blocked_user" ) )
} else {
ctx . ServerError ( "CreateIssueComment" , err )
}
2014-07-26 08:28:04 +02:00
return
}
2015-08-13 10:07:11 +02:00
log . Trace ( "Comment created: %d/%d/%d" , ctx . Repo . Repository . ID , issue . ID , comment . ID )
2014-07-26 08:28:04 +02:00
}
2016-11-24 08:04:31 +01:00
// UpdateCommentContent change comment of issue's content
2016-03-11 17:56:52 +01:00
func UpdateCommentContent ( ctx * context . Context ) {
2024-06-19 00:32:45 +02:00
comment , err := issues_model . GetCommentByID ( ctx , ctx . PathParamInt64 ( ":id" ) )
2015-08-19 22:31:28 +02:00
if err != nil {
2022-06-13 11:37:59 +02:00
ctx . NotFoundOrServerError ( "GetCommentByID" , issues_model . IsErrCommentNotExist , err )
2015-08-19 22:31:28 +02:00
return
}
2022-11-19 09:12:33 +01:00
if err := comment . LoadIssue ( ctx ) ; err != nil {
2022-06-13 11:37:59 +02:00
ctx . NotFoundOrServerError ( "LoadIssue" , issues_model . IsErrIssueNotExist , err )
2018-11-28 12:26:14 +01:00
return
}
2023-11-25 18:21:21 +01:00
if comment . Issue . RepoID != ctx . Repo . Repository . ID {
ctx . NotFound ( "CompareRepoID" , issues_model . ErrCommentNotExist { } )
return
}
2022-03-22 08:03:22 +01:00
if ! ctx . IsSigned || ( ctx . Doer . ID != comment . PosterID && ! ctx . Repo . CanWriteIssuesOrPulls ( comment . Issue . IsPull ) ) {
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusForbidden )
2015-08-19 22:31:28 +02:00
return
2022-01-18 18:28:38 +01:00
}
2023-04-20 08:39:44 +02:00
if ! comment . Type . HasContentSupport ( ) {
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusNoContent )
2015-08-19 22:31:28 +02:00
return
}
2018-05-16 16:01:55 +02:00
oldContent := comment . Content
2024-04-26 03:17:43 +02:00
newContent := ctx . FormString ( "content" )
2024-05-27 17:34:18 +02:00
contentVersion := ctx . FormInt ( "content_version" )
2024-04-26 03:17:43 +02:00
// allow to save empty content
comment . Content = newContent
2024-05-27 17:34:18 +02:00
if err = issue_service . UpdateComment ( ctx , comment , contentVersion , ctx . Doer , oldContent ) ; err != nil {
2024-03-04 09:16:03 +01:00
if errors . Is ( err , user_model . ErrBlockedUser ) {
ctx . JSONError ( ctx . Tr ( "repo.issues.comment.blocked_user" ) )
2024-05-27 17:34:18 +02:00
} else if errors . Is ( err , issues_model . ErrCommentAlreadyChanged ) {
ctx . JSONError ( ctx . Tr ( "repo.comments.edit.already_changed" ) )
2024-03-04 09:16:03 +01:00
} else {
ctx . ServerError ( "UpdateComment" , err )
}
2015-08-19 22:31:28 +02:00
return
}
2022-11-19 09:12:33 +01:00
if err := comment . LoadAttachments ( ctx ) ; err != nil {
2022-01-18 18:28:38 +01:00
ctx . ServerError ( "LoadAttachments" , err )
return
2021-08-20 21:26:19 +02:00
}
2021-08-21 15:04:47 +02:00
// when the update request doesn't intend to update attachments (eg: change checkbox state), ignore attachment updates
if ! ctx . FormBool ( "ignore_attachments" ) {
2022-05-20 16:08:52 +02:00
if err := updateAttachments ( ctx , comment , ctx . FormStrings ( "files[]" ) ) ; err != nil {
2021-08-21 15:04:47 +02:00
ctx . ServerError ( "UpdateAttachments" , err )
return
}
2021-04-20 00:25:08 +02:00
}
2024-04-26 03:17:43 +02:00
var renderedContent template . HTML
if comment . Content != "" {
renderedContent , err = markdown . RenderString ( & markup . RenderContext {
Links : markup . Links {
Base : ctx . FormString ( "context" ) , // FIXME: <- IS THIS SAFE ?
} ,
Metas : ctx . Repo . Repository . ComposeMetas ( ctx ) ,
GitRepo : ctx . Repo . GitRepo ,
2024-05-30 09:04:01 +02:00
Repo : ctx . Repo . Repository ,
2024-04-26 03:17:43 +02:00
Ctx : ctx ,
} , comment . Content )
if err != nil {
ctx . ServerError ( "RenderString" , err )
return
}
} else {
contentEmpty := fmt . Sprintf ( ` <span class="no-content">%s</span> ` , ctx . Tr ( "repo.issues.no_content" ) )
renderedContent = template . HTML ( contentEmpty )
2019-10-15 14:19:32 +02:00
}
2023-07-04 20:36:08 +02:00
ctx . JSON ( http . StatusOK , map [ string ] any {
2024-05-27 17:34:18 +02:00
"content" : renderedContent ,
"contentVersion" : comment . ContentVersion ,
"attachments" : attachmentsHTML ( ctx , comment . Attachments , comment . Content ) ,
2015-08-19 22:31:28 +02:00
} )
}
2016-11-24 08:04:31 +01:00
// DeleteComment delete comment of issue
2016-07-25 20:48:17 +02:00
func DeleteComment ( ctx * context . Context ) {
2024-06-19 00:32:45 +02:00
comment , err := issues_model . GetCommentByID ( ctx , ctx . PathParamInt64 ( ":id" ) )
2016-07-25 20:48:17 +02:00
if err != nil {
2022-06-13 11:37:59 +02:00
ctx . NotFoundOrServerError ( "GetCommentByID" , issues_model . IsErrCommentNotExist , err )
2016-07-25 20:48:17 +02:00
return
}
2022-11-19 09:12:33 +01:00
if err := comment . LoadIssue ( ctx ) ; err != nil {
2022-06-13 11:37:59 +02:00
ctx . NotFoundOrServerError ( "LoadIssue" , issues_model . IsErrIssueNotExist , err )
2018-11-28 12:26:14 +01:00
return
}
2023-11-25 18:21:21 +01:00
if comment . Issue . RepoID != ctx . Repo . Repository . ID {
ctx . NotFound ( "CompareRepoID" , issues_model . ErrCommentNotExist { } )
return
}
2022-03-22 08:03:22 +01:00
if ! ctx . IsSigned || ( ctx . Doer . ID != comment . PosterID && ! ctx . Repo . CanWriteIssuesOrPulls ( comment . Issue . IsPull ) ) {
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusForbidden )
2016-07-25 20:48:17 +02:00
return
2023-04-20 08:39:44 +02:00
} else if ! comment . Type . HasContentSupport ( ) {
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusNoContent )
2016-07-25 20:48:17 +02:00
return
}
2022-12-10 03:46:31 +01:00
if err = issue_service . DeleteComment ( ctx , ctx . Doer , comment ) ; err != nil {
2022-11-19 09:12:33 +01:00
ctx . ServerError ( "DeleteComment" , err )
2016-07-25 20:48:17 +02:00
return
}
2022-03-23 05:54:07 +01:00
ctx . Status ( http . StatusOK )
2016-07-25 20:48:17 +02:00
}
2017-12-04 00:14:26 +01:00
// ChangeIssueReaction create a reaction for issue
2021-01-26 16:36:53 +01:00
func ChangeIssueReaction ( ctx * context . Context ) {
2021-04-06 21:44:05 +02:00
form := web . GetForm ( ctx ) . ( * forms . ReactionForm )
2017-12-04 00:14:26 +01:00
issue := GetActionIssue ( ctx )
if ctx . Written ( ) {
return
}
2022-03-22 08:03:22 +01:00
if ! ctx . IsSigned || ( ctx . Doer . ID != issue . PosterID && ! ctx . Repo . CanReadIssuesOrPulls ( issue . IsPull ) ) {
2019-04-22 22:40:51 +02:00
if log . IsTrace ( ) {
if ctx . IsSigned {
issueType := "issues"
if issue . IsPull {
issueType = "pulls"
}
log . Trace ( "Permission Denied: User %-v not the Poster (ID: %d) and cannot read %s in Repo %-v.\n" +
"User in Repo has Permissions: %-+v" ,
2022-03-22 08:03:22 +01:00
ctx . Doer ,
Rewrite logger system (#24726)
## ⚠️ Breaking
The `log.<mode>.<logger>` style config has been dropped. If you used it,
please check the new config manual & app.example.ini to make your
instance output logs as expected.
Although many legacy options still work, it's encouraged to upgrade to
the new options.
The SMTP logger is deleted because SMTP is not suitable to collect logs.
If you have manually configured Gitea log options, please confirm the
logger system works as expected after upgrading.
## Description
Close #12082 and maybe more log-related issues, resolve some related
FIXMEs in old code (which seems unfixable before)
Just like rewriting queue #24505 : make code maintainable, clear legacy
bugs, and add the ability to support more writers (eg: JSON, structured
log)
There is a new document (with examples): `logging-config.en-us.md`
This PR is safer than the queue rewriting, because it's just for
logging, it won't break other logic.
## The old problems
The logging system is quite old and difficult to maintain:
* Unclear concepts: Logger, NamedLogger, MultiChannelledLogger,
SubLogger, EventLogger, WriterLogger etc
* Some code is diffuclt to konw whether it is right:
`log.DelNamedLogger("console")` vs `log.DelNamedLogger(log.DEFAULT)` vs
`log.DelLogger("console")`
* The old system heavily depends on ini config system, it's difficult to
create new logger for different purpose, and it's very fragile.
* The "color" trick is difficult to use and read, many colors are
unnecessary, and in the future structured log could help
* It's difficult to add other log formats, eg: JSON format
* The log outputer doesn't have full control of its goroutine, it's
difficult to make outputer have advanced behaviors
* The logs could be lost in some cases: eg: no Fatal error when using
CLI.
* Config options are passed by JSON, which is quite fragile.
* INI package makes the KEY in `[log]` section visible in `[log.sub1]`
and `[log.sub1.subA]`, this behavior is quite fragile and would cause
more unclear problems, and there is no strong requirement to support
`log.<mode>.<logger>` syntax.
## The new design
See `logger.go` for documents.
## Screenshot
<details>



</details>
## TODO
* [x] add some new tests
* [x] fix some tests
* [x] test some sub-commands (manually ....)
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Giteabot <teabot@gitea.io>
2023-05-22 00:35:11 +02:00
issue . PosterID ,
2019-04-22 22:40:51 +02:00
issueType ,
ctx . Repo . Repository ,
ctx . Repo . Permission )
} else {
log . Trace ( "Permission Denied: Not logged in" )
}
}
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusForbidden )
2018-11-28 12:26:14 +01:00
return
}
2017-12-04 00:14:26 +01:00
if ctx . HasError ( ) {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "ChangeIssueReaction" , errors . New ( ctx . GetErrMsg ( ) ) )
2017-12-04 00:14:26 +01:00
return
}
2024-06-19 00:32:45 +02:00
switch ctx . PathParam ( ":action" ) {
2017-12-04 00:14:26 +01:00
case "react" :
2024-03-04 09:16:03 +01:00
reaction , err := issue_service . CreateIssueReaction ( ctx , ctx . Doer , issue , form . Content )
2017-12-04 00:14:26 +01:00
if err != nil {
2024-03-04 09:16:03 +01:00
if issues_model . IsErrForbiddenIssueReaction ( err ) || errors . Is ( err , user_model . ErrBlockedUser ) {
2019-12-07 23:04:19 +01:00
ctx . ServerError ( "ChangeIssueReaction" , err )
return
}
2017-12-04 00:14:26 +01:00
log . Info ( "CreateIssueReaction: %s" , err )
break
}
// Reload new reactions
issue . Reactions = nil
2022-06-13 11:37:59 +02:00
if err = issue . LoadAttributes ( ctx ) ; err != nil {
2017-12-04 00:14:26 +01:00
log . Info ( "issue.LoadAttributes: %s" , err )
break
}
log . Trace ( "Reaction for issue created: %d/%d/%d" , ctx . Repo . Repository . ID , issue . ID , reaction . ID )
case "unreact" :
2023-09-25 15:17:37 +02:00
if err := issues_model . DeleteIssueReaction ( ctx , ctx . Doer . ID , issue . ID , form . Content ) ; err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "DeleteIssueReaction" , err )
2017-12-04 00:14:26 +01:00
return
}
// Reload new reactions
issue . Reactions = nil
2022-06-13 11:37:59 +02:00
if err := issue . LoadAttributes ( ctx ) ; err != nil {
2017-12-04 00:14:26 +01:00
log . Info ( "issue.LoadAttributes: %s" , err )
break
}
log . Trace ( "Reaction for issue removed: %d/%d" , ctx . Repo . Repository . ID , issue . ID )
default :
2024-06-19 00:32:45 +02:00
ctx . NotFound ( fmt . Sprintf ( "Unknown action %s" , ctx . PathParam ( ":action" ) ) , nil )
2017-12-04 00:14:26 +01:00
return
}
if len ( issue . Reactions ) == 0 {
2023-07-04 20:36:08 +02:00
ctx . JSON ( http . StatusOK , map [ string ] any {
2017-12-04 00:14:26 +01:00
"empty" : true ,
"html" : "" ,
} )
return
}
2024-03-02 16:05:07 +01:00
html , err := ctx . RenderToHTML ( tplReactions , map [ string ] any {
2017-12-04 00:14:26 +01:00
"ActionURL" : fmt . Sprintf ( "%s/issues/%d/reactions" , ctx . Repo . RepoLink , issue . Index ) ,
"Reactions" : issue . Reactions . GroupByType ( ) ,
} )
if err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "ChangeIssueReaction.HTMLString" , err )
2017-12-04 00:14:26 +01:00
return
}
2023-07-04 20:36:08 +02:00
ctx . JSON ( http . StatusOK , map [ string ] any {
2017-12-04 00:14:26 +01:00
"html" : html ,
} )
}
// ChangeCommentReaction create a reaction for comment
2021-01-26 16:36:53 +01:00
func ChangeCommentReaction ( ctx * context . Context ) {
2021-04-06 21:44:05 +02:00
form := web . GetForm ( ctx ) . ( * forms . ReactionForm )
2024-06-19 00:32:45 +02:00
comment , err := issues_model . GetCommentByID ( ctx , ctx . PathParamInt64 ( ":id" ) )
2017-12-04 00:14:26 +01:00
if err != nil {
2022-06-13 11:37:59 +02:00
ctx . NotFoundOrServerError ( "GetCommentByID" , issues_model . IsErrCommentNotExist , err )
2017-12-04 00:14:26 +01:00
return
}
2022-11-19 09:12:33 +01:00
if err := comment . LoadIssue ( ctx ) ; err != nil {
2022-06-13 11:37:59 +02:00
ctx . NotFoundOrServerError ( "LoadIssue" , issues_model . IsErrIssueNotExist , err )
2017-12-04 00:14:26 +01:00
return
}
2023-11-25 18:21:21 +01:00
if comment . Issue . RepoID != ctx . Repo . Repository . ID {
ctx . NotFound ( "CompareRepoID" , issues_model . ErrCommentNotExist { } )
return
}
2022-03-22 08:03:22 +01:00
if ! ctx . IsSigned || ( ctx . Doer . ID != comment . PosterID && ! ctx . Repo . CanReadIssuesOrPulls ( comment . Issue . IsPull ) ) {
2019-04-22 22:40:51 +02:00
if log . IsTrace ( ) {
if ctx . IsSigned {
issueType := "issues"
if comment . Issue . IsPull {
issueType = "pulls"
}
log . Trace ( "Permission Denied: User %-v not the Poster (ID: %d) and cannot read %s in Repo %-v.\n" +
"User in Repo has Permissions: %-+v" ,
2022-03-22 08:03:22 +01:00
ctx . Doer ,
Rewrite logger system (#24726)
## ⚠️ Breaking
The `log.<mode>.<logger>` style config has been dropped. If you used it,
please check the new config manual & app.example.ini to make your
instance output logs as expected.
Although many legacy options still work, it's encouraged to upgrade to
the new options.
The SMTP logger is deleted because SMTP is not suitable to collect logs.
If you have manually configured Gitea log options, please confirm the
logger system works as expected after upgrading.
## Description
Close #12082 and maybe more log-related issues, resolve some related
FIXMEs in old code (which seems unfixable before)
Just like rewriting queue #24505 : make code maintainable, clear legacy
bugs, and add the ability to support more writers (eg: JSON, structured
log)
There is a new document (with examples): `logging-config.en-us.md`
This PR is safer than the queue rewriting, because it's just for
logging, it won't break other logic.
## The old problems
The logging system is quite old and difficult to maintain:
* Unclear concepts: Logger, NamedLogger, MultiChannelledLogger,
SubLogger, EventLogger, WriterLogger etc
* Some code is diffuclt to konw whether it is right:
`log.DelNamedLogger("console")` vs `log.DelNamedLogger(log.DEFAULT)` vs
`log.DelLogger("console")`
* The old system heavily depends on ini config system, it's difficult to
create new logger for different purpose, and it's very fragile.
* The "color" trick is difficult to use and read, many colors are
unnecessary, and in the future structured log could help
* It's difficult to add other log formats, eg: JSON format
* The log outputer doesn't have full control of its goroutine, it's
difficult to make outputer have advanced behaviors
* The logs could be lost in some cases: eg: no Fatal error when using
CLI.
* Config options are passed by JSON, which is quite fragile.
* INI package makes the KEY in `[log]` section visible in `[log.sub1]`
and `[log.sub1.subA]`, this behavior is quite fragile and would cause
more unclear problems, and there is no strong requirement to support
`log.<mode>.<logger>` syntax.
## The new design
See `logger.go` for documents.
## Screenshot
<details>



</details>
## TODO
* [x] add some new tests
* [x] fix some tests
* [x] test some sub-commands (manually ....)
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Giteabot <teabot@gitea.io>
2023-05-22 00:35:11 +02:00
comment . Issue . PosterID ,
2019-04-22 22:40:51 +02:00
issueType ,
ctx . Repo . Repository ,
ctx . Repo . Permission )
} else {
log . Trace ( "Permission Denied: Not logged in" )
}
}
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusForbidden )
2018-11-28 12:26:14 +01:00
return
2022-01-18 18:28:38 +01:00
}
2023-04-20 08:39:44 +02:00
if ! comment . Type . HasContentSupport ( ) {
2021-04-05 17:30:52 +02:00
ctx . Error ( http . StatusNoContent )
2017-12-04 00:14:26 +01:00
return
}
2024-06-19 00:32:45 +02:00
switch ctx . PathParam ( ":action" ) {
2017-12-04 00:14:26 +01:00
case "react" :
2024-03-04 09:16:03 +01:00
reaction , err := issue_service . CreateCommentReaction ( ctx , ctx . Doer , comment , form . Content )
2017-12-04 00:14:26 +01:00
if err != nil {
2024-03-04 09:16:03 +01:00
if issues_model . IsErrForbiddenIssueReaction ( err ) || errors . Is ( err , user_model . ErrBlockedUser ) {
2019-12-07 23:04:19 +01:00
ctx . ServerError ( "ChangeIssueReaction" , err )
return
}
2017-12-04 00:14:26 +01:00
log . Info ( "CreateCommentReaction: %s" , err )
break
}
// Reload new reactions
comment . Reactions = nil
2023-09-29 14:12:54 +02:00
if err = comment . LoadReactions ( ctx , ctx . Repo . Repository ) ; err != nil {
2017-12-04 00:14:26 +01:00
log . Info ( "comment.LoadReactions: %s" , err )
break
}
2018-11-28 12:26:14 +01:00
log . Trace ( "Reaction for comment created: %d/%d/%d/%d" , ctx . Repo . Repository . ID , comment . Issue . ID , comment . ID , reaction . ID )
2017-12-04 00:14:26 +01:00
case "unreact" :
2023-09-25 15:17:37 +02:00
if err := issues_model . DeleteCommentReaction ( ctx , ctx . Doer . ID , comment . Issue . ID , comment . ID , form . Content ) ; err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "DeleteCommentReaction" , err )
2017-12-04 00:14:26 +01:00
return
}
// Reload new reactions
comment . Reactions = nil
2023-09-29 14:12:54 +02:00
if err = comment . LoadReactions ( ctx , ctx . Repo . Repository ) ; err != nil {
2017-12-04 00:14:26 +01:00
log . Info ( "comment.LoadReactions: %s" , err )
break
}
2018-11-28 12:26:14 +01:00
log . Trace ( "Reaction for comment removed: %d/%d/%d" , ctx . Repo . Repository . ID , comment . Issue . ID , comment . ID )
2017-12-04 00:14:26 +01:00
default :
2024-06-19 00:32:45 +02:00
ctx . NotFound ( fmt . Sprintf ( "Unknown action %s" , ctx . PathParam ( ":action" ) ) , nil )
2017-12-04 00:14:26 +01:00
return
}
if len ( comment . Reactions ) == 0 {
2023-07-04 20:36:08 +02:00
ctx . JSON ( http . StatusOK , map [ string ] any {
2017-12-04 00:14:26 +01:00
"empty" : true ,
"html" : "" ,
} )
return
}
2024-03-02 16:05:07 +01:00
html , err := ctx . RenderToHTML ( tplReactions , map [ string ] any {
2017-12-04 00:14:26 +01:00
"ActionURL" : fmt . Sprintf ( "%s/comments/%d/reactions" , ctx . Repo . RepoLink , comment . ID ) ,
"Reactions" : comment . Reactions . GroupByType ( ) ,
} )
if err != nil {
2018-01-10 22:34:17 +01:00
ctx . ServerError ( "ChangeCommentReaction.HTMLString" , err )
2017-12-04 00:14:26 +01:00
return
}
2023-07-04 20:36:08 +02:00
ctx . JSON ( http . StatusOK , map [ string ] any {
2017-12-04 00:14:26 +01:00
"html" : html ,
} )
}
2019-09-07 16:53:35 +02:00
2021-11-24 10:49:20 +01:00
func addParticipant ( poster * user_model . User , participants [ ] * user_model . User ) [ ] * user_model . User {
2019-09-07 16:53:35 +02:00
for _ , part := range participants {
if poster . ID == part . ID {
return participants
}
}
return append ( participants , poster )
}
2019-09-20 07:45:38 +02:00
2022-06-13 11:37:59 +02:00
func filterXRefComments ( ctx * context . Context , issue * issues_model . Issue ) error {
2019-09-20 07:45:38 +02:00
// Remove comments that the user has no permissions to see
for i := 0 ; i < len ( issue . Comments ) ; {
c := issue . Comments [ i ]
2022-06-13 11:37:59 +02:00
if issues_model . CommentTypeIsRef ( c . Type ) && c . RefRepoID != issue . RepoID && c . RefRepoID != 0 {
2019-09-20 07:45:38 +02:00
var err error
// Set RefRepo for description in template
2022-12-03 03:48:26 +01:00
c . RefRepo , err = repo_model . GetRepositoryByID ( ctx , c . RefRepoID )
2019-09-20 07:45:38 +02:00
if err != nil {
return err
}
2022-05-11 12:09:36 +02:00
perm , err := access_model . GetUserRepoPermission ( ctx , c . RefRepo , ctx . Doer )
2019-09-20 07:45:38 +02:00
if err != nil {
return err
}
if ! perm . CanReadIssuesOrPulls ( c . RefIsPull ) {
issue . Comments = append ( issue . Comments [ : i ] , issue . Comments [ i + 1 : ] ... )
continue
}
}
i ++
}
return nil
}
2019-10-15 14:19:32 +02:00
// GetIssueAttachments returns attachments for the issue
func GetIssueAttachments ( ctx * context . Context ) {
issue := GetActionIssue ( ctx )
2023-07-05 20:52:12 +02:00
if ctx . Written ( ) {
return
}
2022-01-20 18:46:10 +01:00
attachments := make ( [ ] * api . Attachment , len ( issue . Attachments ) )
2019-10-15 14:19:32 +02:00
for i := 0 ; i < len ( issue . Attachments ) ; i ++ {
2023-07-10 11:31:19 +02:00
attachments [ i ] = convert . ToAttachment ( ctx . Repo . Repository , issue . Attachments [ i ] )
2019-10-15 14:19:32 +02:00
}
2021-04-05 17:30:52 +02:00
ctx . JSON ( http . StatusOK , attachments )
2019-10-15 14:19:32 +02:00
}
// GetCommentAttachments returns attachments for the comment
func GetCommentAttachments ( ctx * context . Context ) {
2024-06-19 00:32:45 +02:00
comment , err := issues_model . GetCommentByID ( ctx , ctx . PathParamInt64 ( ":id" ) )
2019-10-15 14:19:32 +02:00
if err != nil {
2022-06-13 11:37:59 +02:00
ctx . NotFoundOrServerError ( "GetCommentByID" , issues_model . IsErrCommentNotExist , err )
2019-10-15 14:19:32 +02:00
return
}
2023-04-20 08:39:44 +02:00
2023-11-25 18:21:21 +01:00
if err := comment . LoadIssue ( ctx ) ; err != nil {
ctx . NotFoundOrServerError ( "LoadIssue" , issues_model . IsErrIssueNotExist , err )
return
}
if comment . Issue . RepoID != ctx . Repo . Repository . ID {
ctx . NotFound ( "CompareRepoID" , issues_model . ErrCommentNotExist { } )
return
}
if ! ctx . Repo . Permission . CanReadIssuesOrPulls ( comment . Issue . IsPull ) {
ctx . NotFound ( "CanReadIssuesOrPulls" , issues_model . ErrCommentNotExist { } )
return
}
2023-04-20 08:39:44 +02:00
if ! comment . Type . HasAttachmentSupport ( ) {
ctx . ServerError ( "GetCommentAttachments" , fmt . Errorf ( "comment type %v does not support attachments" , comment . Type ) )
return
}
2022-01-20 18:46:10 +01:00
attachments := make ( [ ] * api . Attachment , 0 )
2023-04-20 08:39:44 +02:00
if err := comment . LoadAttachments ( ctx ) ; err != nil {
ctx . ServerError ( "LoadAttachments" , err )
return
}
for i := 0 ; i < len ( comment . Attachments ) ; i ++ {
2023-07-10 11:31:19 +02:00
attachments = append ( attachments , convert . ToAttachment ( ctx . Repo . Repository , comment . Attachments [ i ] ) )
2019-10-15 14:19:32 +02:00
}
2021-04-05 17:30:52 +02:00
ctx . JSON ( http . StatusOK , attachments )
2019-10-15 14:19:32 +02:00
}
2023-07-04 20:36:08 +02:00
func updateAttachments ( ctx * context . Context , item any , files [ ] string ) error {
2021-11-19 14:39:57 +01:00
var attachments [ ] * repo_model . Attachment
2019-10-15 14:19:32 +02:00
switch content := item . ( type ) {
2022-06-13 11:37:59 +02:00
case * issues_model . Issue :
2019-10-15 14:19:32 +02:00
attachments = content . Attachments
2022-06-13 11:37:59 +02:00
case * issues_model . Comment :
2019-10-15 14:19:32 +02:00
attachments = content . Attachments
default :
2022-02-26 13:15:32 +01:00
return fmt . Errorf ( "unknown Type: %T" , content )
2019-10-15 14:19:32 +02:00
}
for i := 0 ; i < len ( attachments ) ; i ++ {
Improve utils of slices (#22379)
- Move the file `compare.go` and `slice.go` to `slice.go`.
- Fix `ExistsInSlice`, it's buggy
- It uses `sort.Search`, so it assumes that the input slice is sorted.
- It passes `func(i int) bool { return slice[i] == target })` to
`sort.Search`, that's incorrect, check the doc of `sort.Search`.
- Conbine `IsInt64InSlice(int64, []int64)` and `ExistsInSlice(string,
[]string)` to `SliceContains[T]([]T, T)`.
- Conbine `IsSliceInt64Eq([]int64, []int64)` and `IsEqualSlice([]string,
[]string)` to `SliceSortedEqual[T]([]T, T)`.
- Add `SliceEqual[T]([]T, T)` as a distinction from
`SliceSortedEqual[T]([]T, T)`.
- Redesign `RemoveIDFromList([]int64, int64) ([]int64, bool)` to
`SliceRemoveAll[T]([]T, T) []T`.
- Add `SliceContainsFunc[T]([]T, func(T) bool)` and
`SliceRemoveAllFunc[T]([]T, func(T) bool)` for general use.
- Add comments to explain why not `golang.org/x/exp/slices`.
- Add unit tests.
2023-01-11 06:31:16 +01:00
if util . SliceContainsString ( files , attachments [ i ] . UUID ) {
2019-10-15 14:19:32 +02:00
continue
}
2023-09-15 08:13:19 +02:00
if err := repo_model . DeleteAttachment ( ctx , attachments [ i ] , true ) ; err != nil {
2019-10-15 14:19:32 +02:00
return err
}
}
var err error
if len ( files ) > 0 {
switch content := item . ( type ) {
2022-06-13 11:37:59 +02:00
case * issues_model . Issue :
2023-09-29 14:12:54 +02:00
err = issues_model . UpdateIssueAttachments ( ctx , content . ID , files )
2022-06-13 11:37:59 +02:00
case * issues_model . Comment :
2023-09-29 14:12:54 +02:00
err = content . UpdateAttachments ( ctx , files )
2019-10-15 14:19:32 +02:00
default :
2022-02-26 13:15:32 +01:00
return fmt . Errorf ( "unknown Type: %T" , content )
2019-10-15 14:19:32 +02:00
}
if err != nil {
return err
}
}
switch content := item . ( type ) {
2022-06-13 11:37:59 +02:00
case * issues_model . Issue :
2022-05-20 16:08:52 +02:00
content . Attachments , err = repo_model . GetAttachmentsByIssueID ( ctx , content . ID )
2022-06-13 11:37:59 +02:00
case * issues_model . Comment :
2022-05-20 16:08:52 +02:00
content . Attachments , err = repo_model . GetAttachmentsByCommentID ( ctx , content . ID )
2019-10-15 14:19:32 +02:00
default :
2022-02-26 13:15:32 +01:00
return fmt . Errorf ( "unknown Type: %T" , content )
2019-10-15 14:19:32 +02:00
}
return err
}
2024-03-02 16:05:07 +01:00
func attachmentsHTML ( ctx * context . Context , attachments [ ] * repo_model . Attachment , content string ) template . HTML {
attachHTML , err := ctx . RenderToHTML ( tplAttachment , map [ string ] any {
2023-03-02 18:44:06 +01:00
"ctxData" : ctx . Data ,
2019-10-15 14:19:32 +02:00
"Attachments" : attachments ,
2020-12-13 20:12:27 +01:00
"Content" : content ,
2019-10-15 14:19:32 +02:00
} )
if err != nil {
ctx . ServerError ( "attachmentsHTML.HTMLString" , err )
return ""
}
return attachHTML
}
2020-10-25 22:49:48 +01:00
2021-03-05 16:17:32 +01:00
// combineLabelComments combine the nearby label comments as one.
2022-06-13 11:37:59 +02:00
func combineLabelComments ( issue * issues_model . Issue ) {
var prev , cur * issues_model . Comment
2020-11-20 23:29:09 +01:00
for i := 0 ; i < len ( issue . Comments ) ; i ++ {
2021-03-05 16:17:32 +01:00
cur = issue . Comments [ i ]
2020-11-20 23:29:09 +01:00
if i > 0 {
2020-10-25 22:49:48 +01:00
prev = issue . Comments [ i - 1 ]
}
2022-06-13 11:37:59 +02:00
if i == 0 || cur . Type != issues_model . CommentTypeLabel ||
2020-11-20 23:29:09 +01:00
( prev != nil && prev . PosterID != cur . PosterID ) ||
( prev != nil && cur . CreatedUnix - prev . CreatedUnix >= 60 ) {
2022-06-13 11:37:59 +02:00
if cur . Type == issues_model . CommentTypeLabel && cur . Label != nil {
2020-11-20 23:29:09 +01:00
if cur . Content != "1" {
cur . RemovedLabels = append ( cur . RemovedLabels , cur . Label )
2020-10-25 22:49:48 +01:00
} else {
2020-11-20 23:29:09 +01:00
cur . AddedLabels = append ( cur . AddedLabels , cur . Label )
2020-10-25 22:49:48 +01:00
}
}
2020-11-20 23:29:09 +01:00
continue
2020-10-25 22:49:48 +01:00
}
2020-11-20 23:29:09 +01:00
2021-03-05 16:17:32 +01:00
if cur . Label != nil { // now cur MUST be label comment
2022-06-13 11:37:59 +02:00
if prev . Type == issues_model . CommentTypeLabel { // we can combine them only prev is a label comment
2021-03-05 16:17:32 +01:00
if cur . Content != "1" {
2021-11-04 15:51:30 +01:00
// remove labels from the AddedLabels list if the label that was removed is already
// in this list, and if it's not in this list, add the label to RemovedLabels
addedAndRemoved := false
for i , label := range prev . AddedLabels {
if cur . Label . ID == label . ID {
prev . AddedLabels = append ( prev . AddedLabels [ : i ] , prev . AddedLabels [ i + 1 : ] ... )
addedAndRemoved = true
break
}
}
if ! addedAndRemoved {
prev . RemovedLabels = append ( prev . RemovedLabels , cur . Label )
}
2021-03-05 16:17:32 +01:00
} else {
2021-11-04 15:51:30 +01:00
// remove labels from the RemovedLabels list if the label that was added is already
// in this list, and if it's not in this list, add the label to AddedLabels
removedAndAdded := false
for i , label := range prev . RemovedLabels {
if cur . Label . ID == label . ID {
prev . RemovedLabels = append ( prev . RemovedLabels [ : i ] , prev . RemovedLabels [ i + 1 : ] ... )
removedAndAdded = true
break
}
}
if ! removedAndAdded {
prev . AddedLabels = append ( prev . AddedLabels , cur . Label )
}
2021-03-05 16:17:32 +01:00
}
prev . CreatedUnix = cur . CreatedUnix
// remove the current comment since it has been combined to prev comment
issue . Comments = append ( issue . Comments [ : i ] , issue . Comments [ i + 1 : ] ... )
i --
} else { // if prev is not a label comment, start a new group
if cur . Content != "1" {
cur . RemovedLabels = append ( cur . RemovedLabels , cur . Label )
} else {
cur . AddedLabels = append ( cur . AddedLabels , cur . Label )
}
2021-02-10 03:50:44 +01:00
}
2020-11-20 23:29:09 +01:00
}
2020-10-25 22:49:48 +01:00
}
}
2020-12-21 16:39:28 +01:00
// get all teams that current user can mention
func handleTeamMentions ( ctx * context . Context ) {
2022-03-22 08:03:22 +01:00
if ctx . Doer == nil || ! ctx . Repo . Owner . IsOrganization ( ) {
2020-12-21 16:39:28 +01:00
return
}
2021-11-19 12:41:40 +01:00
var isAdmin bool
2020-12-21 16:39:28 +01:00
var err error
2022-03-29 08:29:02 +02:00
var teams [ ] * organization . Team
org := organization . OrgFromUser ( ctx . Repo . Owner )
2020-12-21 16:39:28 +01:00
// Admin has super access.
2022-03-22 08:03:22 +01:00
if ctx . Doer . IsAdmin {
2020-12-21 16:39:28 +01:00
isAdmin = true
} else {
2023-10-03 12:30:41 +02:00
isAdmin , err = org . IsOwnedBy ( ctx , ctx . Doer . ID )
2020-12-21 16:39:28 +01:00
if err != nil {
ctx . ServerError ( "IsOwnedBy" , err )
return
}
}
if isAdmin {
2023-10-03 12:30:41 +02:00
teams , err = org . LoadTeams ( ctx )
2021-11-19 12:41:40 +01:00
if err != nil {
2021-08-12 14:43:08 +02:00
ctx . ServerError ( "LoadTeams" , err )
2020-12-21 16:39:28 +01:00
return
}
} else {
2023-10-03 12:30:41 +02:00
teams , err = org . GetUserTeams ( ctx , ctx . Doer . ID )
2020-12-21 16:39:28 +01:00
if err != nil {
ctx . ServerError ( "GetUserTeams" , err )
return
}
}
2021-11-19 12:41:40 +01:00
ctx . Data [ "MentionableTeams" ] = teams
2020-12-21 16:39:28 +01:00
ctx . Data [ "MentionableTeamsOrg" ] = ctx . Repo . Owner . Name
Add context cache as a request level cache (#22294)
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
2023-02-15 14:37:34 +01:00
ctx . Data [ "MentionableTeamsOrgAvatar" ] = ctx . Repo . Owner . AvatarLink ( ctx )
2020-12-21 16:39:28 +01:00
}
2023-04-07 02:11:02 +02:00
type userSearchInfo struct {
UserID int64 ` json:"user_id" `
UserName string ` json:"username" `
AvatarLink string ` json:"avatar_link" `
FullName string ` json:"full_name" `
}
type userSearchResponse struct {
Results [ ] * userSearchInfo ` json:"results" `
}
// IssuePosters get posters for current repo's issues/pull requests
func IssuePosters ( ctx * context . Context ) {
2023-07-20 14:41:28 +02:00
issuePosters ( ctx , false )
}
func PullPosters ( ctx * context . Context ) {
issuePosters ( ctx , true )
}
func issuePosters ( ctx * context . Context , isPullList bool ) {
2023-04-07 02:11:02 +02:00
repo := ctx . Repo . Repository
search := strings . TrimSpace ( ctx . FormString ( "q" ) )
posters , err := repo_model . GetIssuePostersWithSearch ( ctx , repo , isPullList , search , setting . UI . DefaultShowFullName )
if err != nil {
ctx . JSON ( http . StatusInternalServerError , err )
return
}
if search == "" && ctx . Doer != nil {
// the returned posters slice only contains limited number of users,
// to make the current user (doer) can quickly filter their own issues, always add doer to the posters slice
2023-09-07 11:37:47 +02:00
if ! slices . ContainsFunc ( posters , func ( user * user_model . User ) bool { return user . ID == ctx . Doer . ID } ) {
2023-04-07 02:11:02 +02:00
posters = append ( posters , ctx . Doer )
}
}
2024-09-12 05:53:40 +02:00
posters = shared_user . MakeSelfOnTop ( ctx . Doer , posters )
2023-04-07 02:11:02 +02:00
resp := & userSearchResponse { }
resp . Results = make ( [ ] * userSearchInfo , len ( posters ) )
for i , user := range posters {
resp . Results [ i ] = & userSearchInfo { UserID : user . ID , UserName : user . Name , AvatarLink : user . AvatarLink ( ctx ) }
if setting . UI . DefaultShowFullName {
resp . Results [ i ] . FullName = user . FullName
}
}
ctx . JSON ( http . StatusOK , resp )
}