Fix unexpected compaction error for compact files (#8024)
Summary: **Summary:** When doing CompactFiles on the files of multiple levels(num_level > 2) with L0 is included, the compaction would fail like this. 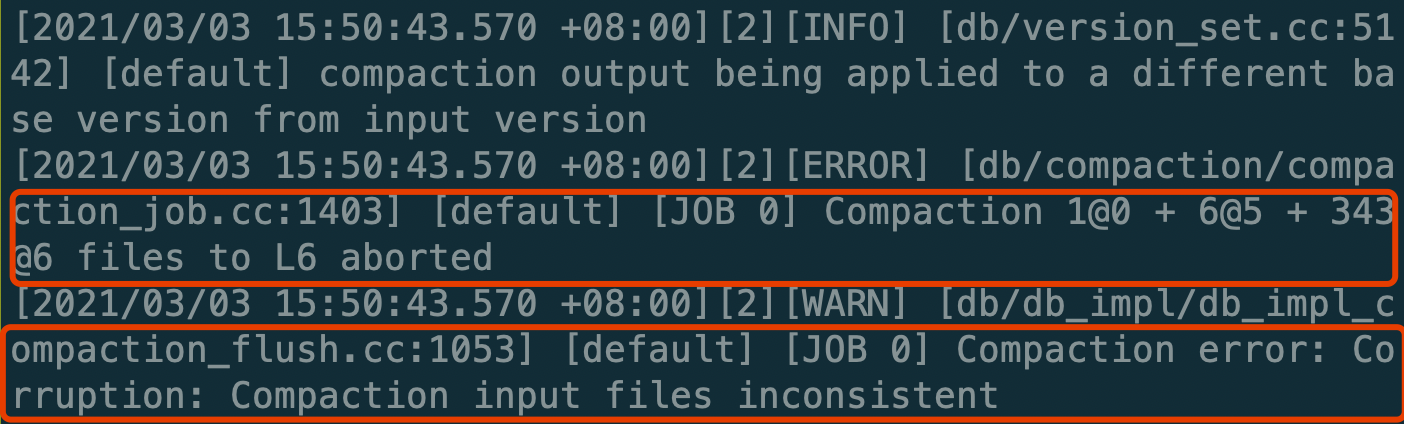 The reason is that in `VerifyCompactionFileConsistency` it checks the levels between the L0 and base level should be empty, but it regards the compaction triggered by `CompactFiles` as an L0 -> base level compaction wrongly. The condition is committed several years ago, whereas it isn't correct anymore. ```c++ if (vstorage->compaction_style_ == kCompactionStyleLevel && c->start_level() == 0 && c->num_input_levels() > 2U) ``` So this PR just deletes the incorrect check. Pull Request resolved: https://github.com/facebook/rocksdb/pull/8024 Test Plan: make check Reviewed By: jay-zhuang Differential Revision: D26907060 Pulled By: ajkr fbshipit-source-id: 538cef32faf464cd422e3f8de236ea3e58880c2b
{kind=link}
This commit is contained in:
parent
469164dc3c
commit
f06b761185
@ -118,6 +118,69 @@ TEST_F(CompactFilesTest, L0ConflictsFiles) {
|
|||||||
delete db;
|
delete db;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
TEST_F(CompactFilesTest, MultipleLevel) {
|
||||||
|
Options options;
|
||||||
|
options.create_if_missing = true;
|
||||||
|
options.level_compaction_dynamic_level_bytes = true;
|
||||||
|
options.num_levels = 6;
|
||||||
|
// Add listener
|
||||||
|
FlushedFileCollector* collector = new FlushedFileCollector();
|
||||||
|
options.listeners.emplace_back(collector);
|
||||||
|
|
||||||
|
DB* db = nullptr;
|
||||||
|
DestroyDB(db_name_, options);
|
||||||
|
Status s = DB::Open(options, db_name_, &db);
|
||||||
|
ASSERT_OK(s);
|
||||||
|
ASSERT_NE(db, nullptr);
|
||||||
|
|
||||||
|
// create couple files in L0, L3, L4 and L5
|
||||||
|
for (int i = 5; i > 2; --i) {
|
||||||
|
collector->ClearFlushedFiles();
|
||||||
|
ASSERT_OK(db->Put(WriteOptions(), ToString(i), ""));
|
||||||
|
ASSERT_OK(db->Flush(FlushOptions()));
|
||||||
|
auto l0_files = collector->GetFlushedFiles();
|
||||||
|
ASSERT_OK(db->CompactFiles(CompactionOptions(), l0_files, i));
|
||||||
|
|
||||||
|
std::string prop;
|
||||||
|
ASSERT_TRUE(
|
||||||
|
db->GetProperty("rocksdb.num-files-at-level" + ToString(i), &prop));
|
||||||
|
ASSERT_EQ("1", prop);
|
||||||
|
}
|
||||||
|
ASSERT_OK(db->Put(WriteOptions(), ToString(0), ""));
|
||||||
|
ASSERT_OK(db->Flush(FlushOptions()));
|
||||||
|
|
||||||
|
ROCKSDB_NAMESPACE::ColumnFamilyMetaData meta;
|
||||||
|
db->GetColumnFamilyMetaData(&meta);
|
||||||
|
// Compact files except the file in L3
|
||||||
|
std::vector<std::string> files;
|
||||||
|
for (int i = 0; i < 6; ++i) {
|
||||||
|
if (i == 3) continue;
|
||||||
|
for (auto& file : meta.levels[i].files) {
|
||||||
|
files.push_back(file.db_path + "/" + file.name);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
ROCKSDB_NAMESPACE::SyncPoint::GetInstance()->LoadDependency({
|
||||||
|
{"CompactionJob::Run():Start", "CompactFilesTest.MultipleLevel:0"},
|
||||||
|
{"CompactFilesTest.MultipleLevel:1", "CompactFilesImpl:3"},
|
||||||
|
});
|
||||||
|
ROCKSDB_NAMESPACE::SyncPoint::GetInstance()->EnableProcessing();
|
||||||
|
|
||||||
|
std::thread thread([&] {
|
||||||
|
TEST_SYNC_POINT("CompactFilesTest.MultipleLevel:0");
|
||||||
|
ASSERT_OK(db->Put(WriteOptions(), "bar", "v2"));
|
||||||
|
ASSERT_OK(db->Put(WriteOptions(), "foo", "v2"));
|
||||||
|
ASSERT_OK(db->Flush(FlushOptions()));
|
||||||
|
TEST_SYNC_POINT("CompactFilesTest.MultipleLevel:1");
|
||||||
|
});
|
||||||
|
|
||||||
|
ASSERT_OK(db->CompactFiles(ROCKSDB_NAMESPACE::CompactionOptions(), files, 5));
|
||||||
|
ROCKSDB_NAMESPACE::SyncPoint::GetInstance()->DisableProcessing();
|
||||||
|
thread.join();
|
||||||
|
|
||||||
|
delete db;
|
||||||
|
}
|
||||||
|
|
||||||
TEST_F(CompactFilesTest, ObsoleteFiles) {
|
TEST_F(CompactFilesTest, ObsoleteFiles) {
|
||||||
Options options;
|
Options options;
|
||||||
// to trigger compaction more easily
|
// to trigger compaction more easily
|
||||||
|
|||||||
@ -5499,20 +5499,6 @@ bool VersionSet::VerifyCompactionFileConsistency(Compaction* c) {
|
|||||||
"[%s] compaction output being applied to a different base version from"
|
"[%s] compaction output being applied to a different base version from"
|
||||||
" input version",
|
" input version",
|
||||||
c->column_family_data()->GetName().c_str());
|
c->column_family_data()->GetName().c_str());
|
||||||
|
|
||||||
if (vstorage->compaction_style_ == kCompactionStyleLevel &&
|
|
||||||
c->start_level() == 0 && c->num_input_levels() > 2U) {
|
|
||||||
// We are doing a L0->base_level compaction. The assumption is if
|
|
||||||
// base level is not L1, levels from L1 to base_level - 1 is empty.
|
|
||||||
// This is ensured by having one compaction from L0 going on at the
|
|
||||||
// same time in level-based compaction. So that during the time, no
|
|
||||||
// compaction/flush can put files to those levels.
|
|
||||||
for (int l = c->start_level() + 1; l < c->output_level(); l++) {
|
|
||||||
if (vstorage->NumLevelFiles(l) != 0) {
|
|
||||||
return false;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
|
|
||||||
for (size_t input = 0; input < c->num_input_levels(); ++input) {
|
for (size_t input = 0; input < c->num_input_levels(); ++input) {
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user