Motivation:
Calling a static method is faster then dynamic
Modifications:
Add 'static' keyword for methods where it missed
Result:
A bit faster method calls
Motivation:
We have our own ThreadLocalRandom implementation to support older JDKs . That said we should prefer the JDK provided when running on JDK >= 7
Modification:
Using ThreadLocalRandom implementation of the JDK when possible.
Result:
Make use of JDK implementations when possible.
Motivation:
Make code easier to read without IDE highlighting.
Modification:
Removed unnecessary 'continue' at end of condition, explicit array creation, unboxing.
Result:
Code easier to read.
Motivation:
DefaultCookie currently used an undocumented magic value for undefined
maxAge.
Clients need to be able to identify such value so they can implement a
proper CookieJar.
Ideally, we should add a `Cookie::isMaxAgeDefined` method but I guess
we can’t add a new method without breaking API :(
Modifications:
Add a new constant on `Cookie` interface so clients can use it to
compare with value return by `Cookie.maxAge` and decide if `maxAge` was
actually defined.
Result:
Clients have a better documented way to check if the maxAge attribute
was defined.
Motivation:
We used various mocking frameworks. We should only use one...
Modifications:
Make usage of mocking framework consistent by only using Mockito.
Result:
Less dependencies and more consistent mocking usage.
Motivation:
HttpHeaders.setTransferEncodingChunked could add a second Transfer-Encoding
header if one was already present. While this is technically valid, it
does not appear to be the intent of the method.
Result:
Only one Transfer-Encoding header is present after calling this method.
Motivation:
In Netty, currently, the HttpPostRequestEncoder only supports POST, PUT, PATCH and OPTIONS, while the RFC 7231 allows with a warning that GET, HEAD, DELETE and CONNECT use a body too (but not TRACE where it is explicitely not allowed).
The RFC in chapter 4.3 says:
"A payload within a XXX request message has no defined semantics;
sending a payload body on a XXX request might cause some existing
implementations to reject the request."
where XXX can be replaced by one of GET, HEAD, DELETE or CONNECT.
Current usages, on particular in REST mode, tend to use those extra HttpMethods for such queries.
So this PR proposes to remove the current restrictions, leaving only TRACE as explicitely not supported.
Modification:
In the constructor, where the test is done, replacing all by checking only against TRACE, and adding one test to check that all methods are supported or not.
Result:
Fixes#6138.
Motivation:
cb139043f3 introduced special handling of response to HEAD requests. Due a bug we failed to handle FullHttpResponse correctly.
Modifications:
Correctly handle FullHttpResponse for HEAD requests.
Result:
Works as expected.
Motivation:
We should have a unit test which explicitly tests a HTTP message being split between multiple ByteBuf objects.
Modifications:
- Add a unit test to HttpRequestDecoderTest which splits a request between 2 ByteBuf objects
Result:
More unit test coverage for HttpObjectDecoder.
Motivation:
Enables optional .startsWith() matching of req.uri() with websocketPath.
Modifications:
New checkStartsWith boolean option with default false value added to both WebSocketServerProtocolHandler and WebSocketServerProtocolHandshakeHandler. req.uri() matching is based on this option.
Result:
By default old behavior matching via .equal() is preserved. To use checkStartsWith use constructor shortcut: new WebSocketServerProtocolHandler(websocketPath, true) or fill this flag on full form of constructor among other options.
request with a 'content-encoding: chunked' header
Motivation:
It is valid to send a response to a HEAD request that contains a transfer-encoding: chunked header, but it is not valid to include a body, and there is no way to do this using the netty4 HttpServerCodec.
The root cause is that the netty4 HttpObjectEncoder will transition to the state ST_CONTENT_CHUNK and the only way to transition back to ST_INIT is through the encodeChunkedContent method which will write the terminating length (0\r\n\r\n\r\n), a protocol error when responding to a HEAD request
Modifications:
- Keep track of the method of the request and depending on it handle the response differently when encoding it.
- Added a unit test.
Result:
Correclty handle HEAD responses that are chunked.
Motiviation:
We used ReferenceCountUtil.releaseLater(...) in our tests which simplifies a bit the releasing of ReferenceCounted objects. The problem with this is that while it simplifies stuff it increase memory usage a lot as memory may not be freed up in a timely manner.
Modifications:
- Deprecate releaseLater(...)
- Remove usage of releaseLater(...) in tests.
Result:
Less memory needed to build netty while running the tests.
Motivation:
If the wsURL contains an encoded query, it will be decoded when generating the raw path. For example if the wsURL is http://test.org/path?a=1%3A5, the returned raw path would be /path?a=1:5
Modifications:
Use wsURL.getRawQuery() rather than wsURL.getQuery()
Result:
rawPath will now return /path?a=1%3A5
Motivation:
We need to ensure we not add the Transfer-Encoding header if the HttpMessage is EOF terminated.
Modifications:
Only add the Transfer-Encoding header if an Content-Length header is present.
Result:
Correctly handle HttpMessage that is EOF terminated.
Motivation:
HttpObjectDecoder maintains a resetRequested flag which is used to determine if internal state should be reset when a decode occurs. However after a reset is done the resetRequested flag is not set to false. This leads to all data after this point being discarded.
Modifications:
- Set resetRequested to false when a reset is done
Result:
HttpObjectDecoder can still function after a reset.
Motivation:
As discussed in #5738, developers need to concern themselves with setting
connection: keep-alive on the response as well as whether to close a
connection or not after writing a response. This leads to special keep-alive
handling logic in many different places. The purpose of the HttpServerKeepAliveHandler
is to allow developers to add this handler to their pipeline and therefore
free themselves of having to worry about the details of how Keep-Alive works.
Modifications:
Added HttpServerKeepAliveHandler to the io.netty.handler.codec.http package.
Result:
Developers can start using HttpServerKeepAliveHandler in their pipeline instead
of worrying about when to close a connection for keep-alive.
Motivation:
HttpObjectAggregator has a potential to leak if a new message is received before the existing message has completed, and if a HttpContent is received but maxContentLength has been exceeded, or the content length is too long.
Modifications:
- Make the HttpObjectAggregator more robust to leaks
- Remove the tooLongFrameFound member variable
Result:
More robust HttpObjectAggregator with less chance of leaks
Motivation:
The CorsHandler currently closes the channel when it responds to a preflight (OPTIONS)
request or in the event of a short circuit due to failed validation.
Especially in an environment where there's a proxy in front of the service this causes
unnecessary connection churn.
Modifications:
CorsHandler now uses HttpUtil to determine if the connection should be closed
after responding and to set the Connection header on the response.
Result:
Channel will stay open when the CorsHandler responds unless the client specifies otherwise
or the protocol version is HTTP/1.0
Motivation:
Documentation was added in #2401 to aid developers in understanding
how HttpObjectAggregator works and that it needs an encoder before it.
In #2471 it was pointed out that the documentation added can actually
add to the confusion and that it might have a typo.
This is an attempt at clearing up that confusion. Feedback is welcome.
Modifications:
- Adjust class level javadoc for HttpObjectAggregator
* Remove reference to HttpRequestEncoder
* Point out when HttpResponseEncoder is needed
* Point out that either HttpRequestDecoder or HttpResponseDecoder is needed
* Make clear everything must be added before HttpObjectAggregator
* Mention HttpServerCodec
Result:
Avoid confusion about dependencies for HttpObjectAggregator on the pipeline.
Motivation:
RFC 6265 does not state that cookie names must be case insensitive.
Modifications:
Fix io.netty.handler.codec.http.cookie.DefaultCookie#equals() method to
use case sensitive String#equals() and String#compareTo().
Result:
It is possible to parse several cookies with same names but with
different cases.
Motivation:
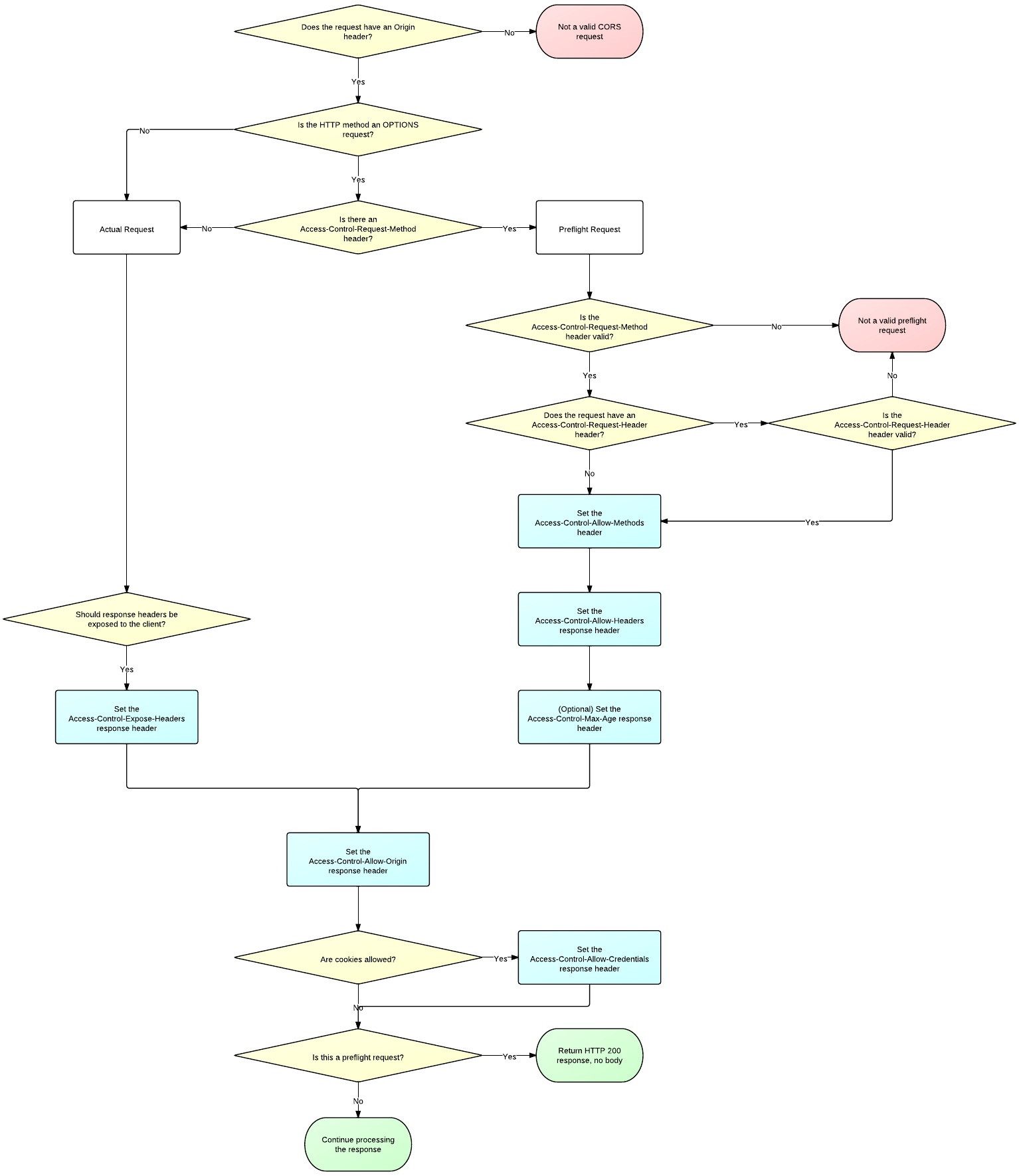
The CorsHandler currently returns the Access-Control-Allow-Headers
header as on a Non-Preflight CORS request (Simple request).
As per the CORS specification the Access-Control-Allow-Headers header
should only be returned on Preflight requests. (not on simple requests).
https://www.w3.org/TR/2014/REC-cors-20140116/#access-control-allow-headers-response-headerhttp://www.html5rocks.com/static/images/cors_server_flowchart.png
Modifications:
Modified CorsHandler.java to not add the Access-Control-Allow-Headers
header when responding to Non-preflight CORS request.
Result:
Access-Control-Allow-Headers header will not be returned on a Simple
request (Non-preflight CORS request).
Motivation:
There are few duplicated byte[] CRLF fields in code.
Modifications:
Removed duplicated fields as they could be inherited from parent encoder.
Result:
Less static fields.
Motivation
Starting from Java 7 method String.split in java is optimized for splitting by single char string. Thus custom StringUtil.split method doesn't have any sense anymore. Even more - it slower than optimized java version.
Modifications:
Replaced all occurrences of StringUtil.split with String.split.
Result:
Less code and faster on jdk7
Motivation :
Unboxing operations allocate unnecessary objects when it could be avoided.
Modifications:
Replaced Float.valueOf with Number.parseFloat where possible.
Result:
Less unnecessary objects allocations.
Motivation:
Currently, QueryStringDecoder#path simply returns the path info as is, without decoding it as the Javadoc states.
Modifications:
* Make QueryStringDecoder#path decode the path info.
* Add tests to QueryStringDecoderTest.
Result:
QueryStringDecoder#path now decodes the path info as expected.
Motivation:
DiskFileUpload and MemoryFileUpload.equals(...) are broken.
Modifications:
Fix implementation and add unit test.
Result:
Equals method are correct now.
Motivation:
We don't have an argument named {@code value} but have {@code set} and
{@code expected} in HttpHeaders and HttpUtil respectively.
Modifications:
I replaced {@code value} to {@code set} and {@code expected} in HttpHeaders
and HttpUtil respectively.
Result:
Now javadoc says;
If {@code set} is {@code true}, the {@code "Expect: 100-continue"} header is
set and all other previous {@code "Expect"} headers are removed. Otherwise,
all {@code "Expect"} headers are removed completely. in HttpHeaders
If {@code expected} is {@code true}, the {@code "Expect: 100-continue"} header
is set and all other previous {@code "Expect"} headers are removed. Otherwise,
all {@code "Expect"} headers are removed completely. in HttpUtil
Motivation:
We use pre-instantiated exceptions in various places for performance reasons. These exceptions don't include a stacktrace which makes it hard to know where the exception was thrown. This is especially true as we use the same exception type (for example ChannelClosedException) in different places. Setting some StackTraceElements will provide more context as to where these exceptions original and make debugging easier.
Modifications:
Set a generated StackTraceElement on these pre-instantiated exceptions which at least contains the origin class and method name. The filename and linenumber are specified as unkown (as stated in the javadocs of StackTraceElement).
Result:
Easier to find the origin of a pre-instantiated exception.
Motivation:
When HTTPS is used we should use https in the sec-websocket-origin / origin header
Modifications:
- Correctly generate the sec-websocket-origin / origin header
- Add unit tests.
Result:
Generate correct header.
`HttpContentDecoder` was removing `Content-Length` header but not adding a `Transfer-Encoding` header which goes against the HTTP spec.
Added `Transfer-Encoding` header with value `chunked` when `Content-Length` is removed.
Modified existing unit test to also check for this condition.
Compliance with HTTP spec.
Motivation:
When using HttpContentCompressor and the HttpResponse is protocol version 1.0, HttpContentEncoder.encode() should not set the transfer-encoding header to chunked. Chunked transfer-encoding is not valid for HTTP 1.0 - this causes ERR_CONTENT_DECODING_FAILED errors in chrome and similar failures in IE.
Modifications:
Skip HTTP/1.0 messages
Result:
Be able to serve HTTP/1.0 as well when HttpContentEncoder is in the pipeline.
{kind=link}