Motivation:
HttpObjectDecoder maintains a resetRequested flag which is used to determine if internal state should be reset when a decode occurs. However after a reset is done the resetRequested flag is not set to false. This leads to all data after this point being discarded.
Modifications:
- Set resetRequested to false when a reset is done
Result:
HttpObjectDecoder can still function after a reset.
Motivation:
As discussed in #5738, developers need to concern themselves with setting
connection: keep-alive on the response as well as whether to close a
connection or not after writing a response. This leads to special keep-alive
handling logic in many different places. The purpose of the HttpServerKeepAliveHandler
is to allow developers to add this handler to their pipeline and therefore
free themselves of having to worry about the details of how Keep-Alive works.
Modifications:
Added HttpServerKeepAliveHandler to the io.netty.handler.codec.http package.
Result:
Developers can start using HttpServerKeepAliveHandler in their pipeline instead
of worrying about when to close a connection for keep-alive.
Motivation:
As described in #5734
Before this change, if the server had to do some sort of setup after a
handshake was completed based on handshake's information, the only way
available was to wait (in a separate thread) for the handshaker to be
added as an attribute to the channel. Too much hassle.
Modifications:
Handshake completed event need to be stateful now, so I've added a tiny
class holding just the HTTP upgrade request and the selected subprotocol
which is fired as an event after the handshake has finished.
I've also deprecated the old enum used as stateless event and I left the
code that fires it for backward compatibility. It should be removed in
the next mayor release.
Result:
It should be much simpler now to do initialization stuff based on
subprotocol or request headers on handshake completion. No asynchronous
waiting needed anymore.
Motivation:
The CorsHandler currently closes the channel when it responds to a preflight (OPTIONS)
request or in the event of a short circuit due to failed validation.
Especially in an environment where there's a proxy in front of the service this causes
unnecessary connection churn.
Modifications:
CorsHandler now uses HttpUtil to determine if the connection should be closed
after responding and to set the Connection header on the response.
Result:
Channel will stay open when the CorsHandler responds unless the client specifies otherwise
or the protocol version is HTTP/1.0
Motivation:
Documentation was added in #2401 to aid developers in understanding
how HttpObjectAggregator works and that it needs an encoder before it.
In #2471 it was pointed out that the documentation added can actually
add to the confusion and that it might have a typo.
This is an attempt at clearing up that confusion. Feedback is welcome.
Modifications:
- Adjust class level javadoc for HttpObjectAggregator
* Remove reference to HttpRequestEncoder
* Point out when HttpResponseEncoder is needed
* Point out that either HttpRequestDecoder or HttpResponseDecoder is needed
* Make clear everything must be added before HttpObjectAggregator
* Mention HttpServerCodec
Result:
Avoid confusion about dependencies for HttpObjectAggregator on the pipeline.
Motivation:
The CorsHandler currently closes the channel when it responds to a preflight (OPTIONS)
request or in the event of a short circuit due to failed validation.
Especially in an environment where there's a proxy in front of the service this causes
unnecessary connection churn.
Modifications:
CorsHandler now uses HttpUtil to determine if the connection should be closed
after responding
Result:
Channel will stay open when the CorsHandler responds unless the client specifies otherwise
or the protocol version is HTTP/1.0
Motivation:
RFC 6265 does not state that cookie names must be case insensitive.
Modifications:
Fix io.netty.handler.codec.http.cookie.DefaultCookie#equals() method to
use case sensitive String#equals() and String#compareTo().
Result:
It is possible to parse several cookies with same names but with
different cases.
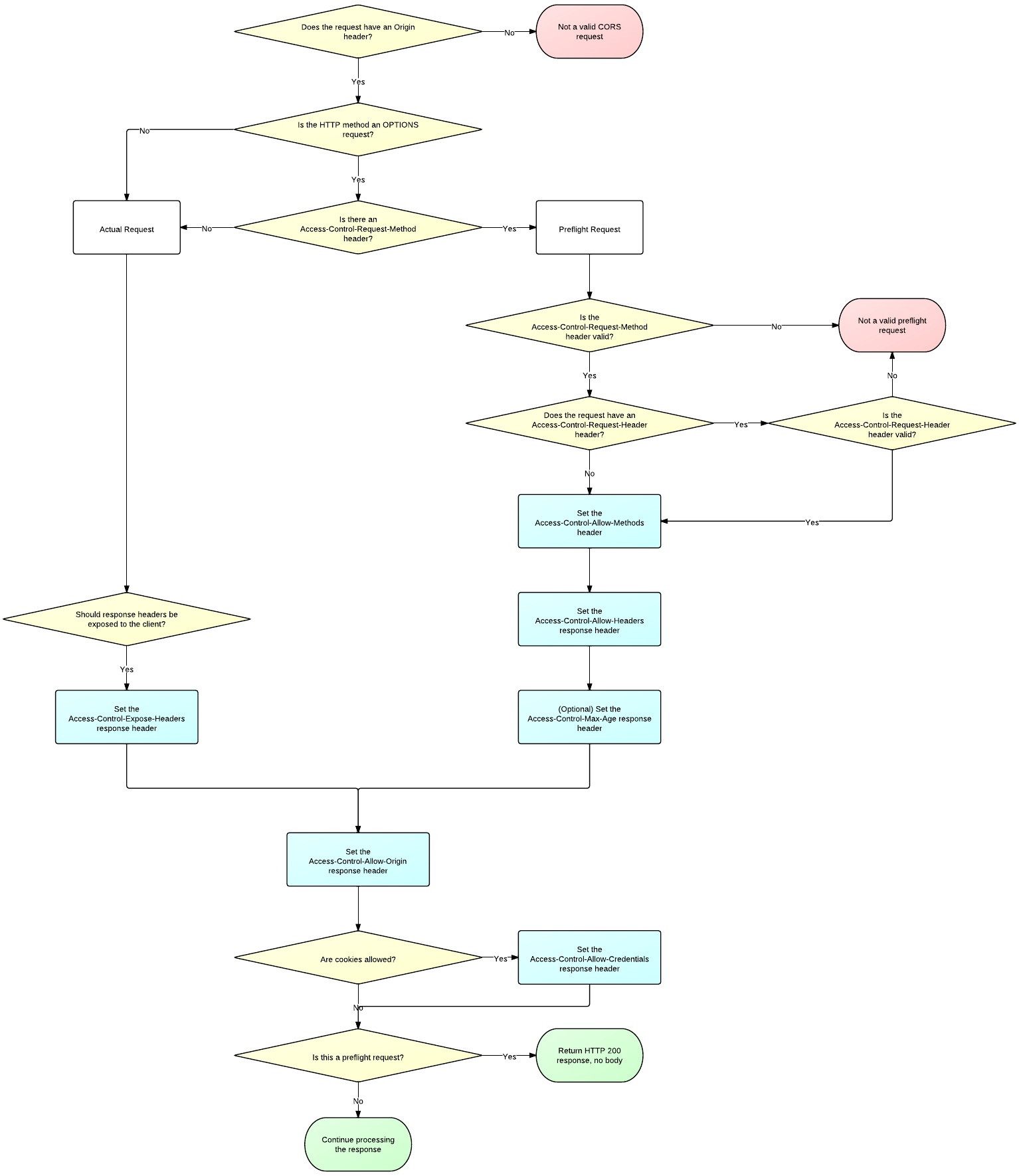
Motivation:
The CorsHandler currently returns the Access-Control-Allow-Headers
header as on a Non-Preflight CORS request (Simple request).
As per the CORS specification the Access-Control-Allow-Headers header
should only be returned on Preflight requests. (not on simple requests).
https://www.w3.org/TR/2014/REC-cors-20140116/#access-control-allow-headers-response-headerhttp://www.html5rocks.com/static/images/cors_server_flowchart.png
Modifications:
Modified CorsHandler.java to not add the Access-Control-Allow-Headers
header when responding to Non-preflight CORS request.
Result:
Access-Control-Allow-Headers header will not be returned on a Simple
request (Non-preflight CORS request).
Motivation:
There are few duplicated byte[] CRLF fields in code.
Modifications:
Removed duplicated fields as they could be inherited from parent encoder.
Result:
Less static fields.
Motivation :
Unboxing operations allocate unnecessary objects when it could be avoided.
Modifications:
Replaced Float.valueOf with Number.parseFloat where possible.
Result:
Less unnecessary objects allocations.
Motivation:
retainSlice() currently does not unwrap the ByteBuf when creating the ByteBuf wrapper. This effectivley forms a linked list of ByteBuf when it is only necessary to maintain a reference to the unwrapped ByteBuf.
Modifications:
- retainSlice() and retainDuplicate() variants should only maintain a reference to the unwrapped ByteBuf
- create new unit tests which generally verify the retainSlice() behavior
- Remove unecessary generic arguments from AbstractPooledDerivedByteBuf
- Remove unecessary int length member variable from the unpooled sliced ByteBuf implementation
- Rename the unpooled sliced/derived ByteBuf to include Unpooled in their name to be more consistent with the Pooled variants
Result:
Fixes https://github.com/netty/netty/issues/5582
Motivation:
Currently, QueryStringDecoder#path simply returns the path info as is, without decoding it as the Javadoc states.
Modifications:
* Make QueryStringDecoder#path decode the path info.
* Add tests to QueryStringDecoderTest.
Result:
QueryStringDecoder#path now decodes the path info as expected.
Motivation:
DiskFileUpload and MemoryFileUpload.equals(...) are broken.
Modifications:
Fix implementation and add unit test.
Result:
Equals method are correct now.
Motivation:
We don't have an argument named {@code value} but have {@code set} and
{@code expected} in HttpHeaders and HttpUtil respectively.
Modifications:
I replaced {@code value} to {@code set} and {@code expected} in HttpHeaders
and HttpUtil respectively.
Result:
Now javadoc says;
If {@code set} is {@code true}, the {@code "Expect: 100-continue"} header is
set and all other previous {@code "Expect"} headers are removed. Otherwise,
all {@code "Expect"} headers are removed completely. in HttpHeaders
If {@code expected} is {@code true}, the {@code "Expect: 100-continue"} header
is set and all other previous {@code "Expect"} headers are removed. Otherwise,
all {@code "Expect"} headers are removed completely. in HttpUtil
Motivation:
These methods were recently deprecated. However, they remained in use in several locations in Netty's codebase.
Modifications:
Netty's code will now access the bootstrap config to get the group or child group.
Result:
No impact on functionality.
Motivation:
We use pre-instantiated exceptions in various places for performance reasons. These exceptions don't include a stacktrace which makes it hard to know where the exception was thrown. This is especially true as we use the same exception type (for example ChannelClosedException) in different places. Setting some StackTraceElements will provide more context as to where these exceptions original and make debugging easier.
Modifications:
Set a generated StackTraceElement on these pre-instantiated exceptions which at least contains the origin class and method name. The filename and linenumber are specified as unkown (as stated in the javadocs of StackTraceElement).
Result:
Easier to find the origin of a pre-instantiated exception.
Motivation:
When HTTPS is used we should use https in the sec-websocket-origin / origin header
Modifications:
- Correctly generate the sec-websocket-origin / origin header
- Add unit tests.
Result:
Generate correct header.
`HttpContentDecoder` was removing `Content-Length` header but not adding a `Transfer-Encoding` header which goes against the HTTP spec.
Added `Transfer-Encoding` header with value `chunked` when `Content-Length` is removed.
Modified existing unit test to also check for this condition.
Compliance with HTTP spec.
Motivation:
When using HttpContentCompressor and the HttpResponse is protocol version 1.0, HttpContentEncoder.encode() should not set the transfer-encoding header to chunked. Chunked transfer-encoding is not valid for HTTP 1.0 - this causes ERR_CONTENT_DECODING_FAILED errors in chrome and similar failures in IE.
Modifications:
Skip HTTP/1.0 messages
Result:
Be able to serve HTTP/1.0 as well when HttpContentEncoder is in the pipeline.
Motivation:
Its completly fine for ChunkedInput.readChunk(...) to return null to indicate there is currently not any data to read. We need to handle this in HttpChunkedInput to not produce a NPE when constructing the HttpContent.
Modifications:
If readChunk(...) return null just return null as well.
Result:
No more NPE.
Motivation:
I cherry-picked 819b26b too soon. There were entries added to a deprecated class which should only go into the non-deprecated version of the class.
Modifications:
- Remove the static final variables that were added as duplicates to the deprecated class
Result:
Deprecated code does not grown in volume without need.
Motivation:
Some commons values are missing from HttpHeader values constants.
Modifications:
- Add constants for "application/json" Content-Type
- Add constants for "gzip,deflate" Content-Encoding
Result:
More HttpHeader values constants available, both in
`HttpHeaders.Values` and `HttpHeaderValues`.
Motivation:
Support fetches data chunk by chunk for use with WebSocket chunked transfers.
Modifications:
Create a WebSocketChunkedInput.java that add to io.netty.handler.codec.http.websocketx package
Result:
The WebSocket transfers/fetches data chunk by chunk.
Motivation:
JCTools supports both non-unsafe, unsafe versions of queues and JDK6 which allows us to shade the library in netty-common allowing it to stay "zero dependency".
Modifications:
- Remove copy paste JCTools code and shade the library (dependencies that are shaded should be removed from the <dependencies> section of the generated POM).
- Remove usage of OneTimeTask and remove it all together.
Result:
Less code to maintain and easier to update JCTools and less GC pressure as the queue implementation nt creates so much garbage
Motivation:
When the channel is closed while we still decode the headers we currently not preserve correct message sequence. In this case we should generate an invalid message with a current cause.
Modifications:
Create an invalid message with a PrematureChannelClosureException as cause when the channel is closed while we decode the headers.
Result:
Correct message sequence preserved and correct DecoderResult if the channel is closed while decode headers.
Motivation:
The user may specify to use a different allocator then the default. In this case we need to ensure it is shared when creating the EmbeddedChannel inside of a ChannelHandler
Modifications:
Use the config of the "original" Channel in the EmbeddedChannel and so share the same allocator etc.
Result:
Same type of buffers are used.
Motivation:
At the moment the user is responsible to increase the writer index of the composite buffer when a new component is added. We should add some methods that handle this for the user as this is the most popular usage of the composite buffer.
Modifications:
Add new methods that autoamtically increase the writerIndex when buffers are added.
Result:
Easier usage of CompositeByteBuf.
Motivation:
The HPACK code currently disallows empty header names. This is not explicitly forbidden by the HPACK RFC https://tools.ietf.org/html/rfc7541. However the HTTP/1.x RFC https://tools.ietf.org/html/rfc7230#section-3.2 and thus HTTP/2 both disallow empty header names, and so this precondition check should be moved from the HPACK code to the protocol level.
HPACK also requires that string literals which are huffman encoded must be treated as an encoding error if the string has more than 7 trailing padding bits https://tools.ietf.org/html/rfc7541#section-5.2, but this is currently not enforced.
Result:
- HPACK to allow empty header names
- HTTP/1.x and HTTP/2 header validation should not allow empty header names
- Enforce max of 7 trailing padding bits
Result:
Code is more compliant with the above mentioned RFCs
Fixes https://github.com/netty/netty/issues/5228
Related: #4333#4421#5128
Motivation:
slice(), duplicate() and readSlice() currently create a non-recyclable
derived buffer instance. Under heavy load, an application that creates a
lot of derived buffers can put the garbage collector under pressure.
Modifications:
- Add the following methods which creates a non-recyclable derived buffer
- retainedSlice()
- retainedDuplicate()
- readRetainedSlice()
- Add the new recyclable derived buffer implementations, which has its
own reference count value
- Add ByteBufHolder.retainedDuplicate()
- Add ByteBufHolder.replace(ByteBuf) so that..
- a user can replace the content of the holder in a consistent way
- copy/duplicate/retainedDuplicate() can delegate the holder
construction to replace(ByteBuf)
- Use retainedDuplicate() and retainedSlice() wherever possible
- Miscellaneous:
- Rename DuplicateByteBufTest to DuplicatedByteBufTest (missing 'D')
- Make ReplayingDecoderByteBuf.reject() return an exception instead of
throwing it so that its callers don't need to add dummy return
statement
Result:
Derived buffers are now recycled when created via retainedSlice() and
retainedDuplicate() and derived from a pooled buffer
Motivation:
At the moment we let the IllegalArgumentException escape when parsing form parameters. This is not expected.
Modifications:
Correctly catch IllegalArgumentException and rethrow as ErrorDataDecoderException.
Result:
Throw correct exception.
Motivation:
Currently the way a 'null' origin, a request that most often indicated
that the request is coming from a file on the local file system, is
handled is incorrect. We are currently returning a wildcard origin '*'
but should be returning 'null' for the 'Access-Control-Allow-Origin'
which is valid according to the specification [1].
Modifications:
Updated CorsHandler to add a 'null' origin instead of the '*' origin in
the case the request origin is 'null.
Result:
All test pass and the CORS example as does the cors.html example if you
try to serve it by opening the file directly in a web browser.
[1]
https://www.w3.org/TR/cors/#access-control-allow-origin-response-header
Motivation:
Checking if a key exists on a TreeMap has a Big O of "log 2 N",
doing it twice is not cheap.
Modifications:
Get the key instead which has the same cost and check if it is null.
Result:
Faster code due to one expensive operation removed.
Motivation:
We missed to reset the decoder when asked for it in HttpObjectDecoder and so sometimes could produce more then one LastHttpContent in a sequence during channelInactive.
This did show up as AssertionError:
22:22:35.499 [nioEventLoopGroup-3-1] WARN i.n.channel.DefaultChannelPipeline - An exceptionCaught() event was fired, and it reached at the tail of the pipeline. It usually means the last handler in the pipeline did not handle the exception.
java.lang.AssertionError: null
at io.netty.handler.codec.http.HttpObjectAggregator.decode(HttpObjectAggregator.java:205) ~[classes/:na]
at io.netty.handler.codec.http.HttpObjectAggregator.decode(HttpObjectAggregator.java:57) ~[classes/:na]
at io.netty.handler.codec.MessageToMessageDecoder.channelRead(MessageToMessageDecoder.java:89) ~[classes/:na]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:292) [classes/:na]
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:278) [classes/:na]
at io.netty.channel.CombinedChannelDuplexHandler$DelegatingChannelHandlerContext.fireChannelRead(CombinedChannelDuplexHandler.java:428) [classes/:na]
at io.netty.handler.codec.ByteToMessageDecoder.fireChannelRead(ByteToMessageDecoder.java:277) [classes/:na]
at io.netty.handler.codec.ByteToMessageDecoder.channelInputClosed(ByteToMessageDecoder.java:343) [classes/:na]
at io.netty.handler.codec.ByteToMessageDecoder.channelInactive(ByteToMessageDecoder.java:309) [classes/:na]
at io.netty.handler.codec.http.HttpClientCodec$Decoder.channelInactive(HttpClientCodec.java:228) [classes/:na]
at io.netty.channel.CombinedChannelDuplexHandler.channelInactive(CombinedChannelDuplexHandler.java:213) [classes/:na]
...
Modifications:
Correctly reset decoder.
Result:
Correctly only produce one LastHttpContent per sequence.
{kind=link}