Motivation:
HttpHeaderDateFormat was replaced with DateFormatter many days ago and now can be easily removed.
Modification:
Remove deprecated class and related test / benchmark
Result:
Less code to maintain
Motivation:
In most cases, HttpMethod instance is built from the factory method and the same instance is taken for known Http Methods. So we can implement fast path for equals().
Modification:
Replace == checks with HttpMethod.equals;
Use this == o within HttpMethod.equals;
Replaced known new HttpMethod with HttpMethod.valueOf;
Result:
Comparisons should be a bit faster in some cases.
Motivation:
We can use lambdas now as we use Java8.
Modification:
use lambda function for all package, #8751 only migrate transport package.
Result:
Code cleanup.
Motivation:
As netty 4.x supported Java 6 we had various if statements to check for java versions < 8. We can remove these now.
Modification:
Remove unnecessary if statements that check for java versions < 8.
Result:
Cleanup code.
Motivation:
We need to update to a new checkstyle plugin to allow the usage of lambdas.
Modifications:
- Update to new plugin version.
- Fix checkstyle problems.
Result:
Be able to use checkstyle plugin which supports new Java syntax.
* Decouble EventLoop details from the IO handling for each transport to allow easy re-use of code and customization
Motiviation:
As today extending EventLoop implementations to add custom logic / metrics / instrumentations is only possible in a very limited way if at all. This is due the fact that most implementations are final or even package-private. That said even if these would be public there are the ability to do something useful with these is very limited as the IO processing and task processing are very tightly coupled. All of the mentioned things are a big pain point in netty 4.x and need improvement.
Modifications:
This changeset decoubled the IO processing logic from the task processing logic for the main transport (NIO, Epoll, KQueue) by introducing the concept of an IoHandler. The IoHandler itself is responsible to wait for IO readiness and process these IO events. The execution of the IoHandler itself is done by the SingleThreadEventLoop as part of its EventLoop processing. This allows to use the same EventLoopGroup (MultiThreadEventLoupGroup) for all the mentioned transports by just specify a different IoHandlerFactory during construction.
Beside this core API change this changeset also allows to easily extend SingleThreadEventExecutor / SingleThreadEventLoop to add custom logic to it which then can be reused by all the transports. The ideas are very similar to what is provided by ScheduledThreadPoolExecutor (that is part of the JDK). This allows for example things like:
* Adding instrumentation / metrics:
* how many Channels are registered on an SingleThreadEventLoop
* how many Channels were handled during the IO processing in an EventLoop run
* how many task were handled during the last EventLoop / EventExecutor run
* how many outstanding tasks we have
...
...
* Implementing custom strategies for choosing the next EventExecutor / EventLoop to use based on these metrics.
* Use different Promise / Future / ScheduledFuture implementations
* decorate Runnable / Callables when submitted to the EventExecutor / EventLoop
As a lot of functionalities are folded into the MultiThreadEventLoopGroup and SingleThreadEventLoopGroup this changeset also removes:
* AbstractEventLoop
* AbstractEventLoopGroup
* EventExecutorChooser
* EventExecutorChooserFactory
* DefaultEventLoopGroup
* DefaultEventExecutor
* DefaultEventExecutorGroup
Result:
Fixes https://github.com/netty/netty/issues/8514 .
Motivation:
Custom Netty ThreadLocalRandom and ThreadLocalRandomProvider classes are no longer needed and can be removed.
Modification:
Remove own ThreadLocalRandom
Result:
Less code to maintain
Motivation:
PlatformDependent.newConcurrentHashMap() is no longer needed so it could be easily removed and new ConcurrentHashMap<>() inlined instead of invoking PlatformDependent.newConcurrentHashMap().
Modification:
Use ConcurrentHashMap provided by the JDK directly.
Result:
Less code to maintain.
Motivation:
No need to initialize charsets from the string. We can take already allocated charset from StandardCharsets class.
Modification:
Replace Charset.forName("US-ASCII") with StandardCharsets.US_ASCII.
Removed Charset[] values() method and internal static variable as it was used only in tests.
Result:
Reuse what the JDK provides
Motivation:
We can use the diamond operator these days.
Modification:
Use diamond operator whenever possible.
Result:
More modern code and less boiler-plate.
Motivation:
Replace "if else" conditions with string switch. It is easier to read the code, for large "if else" constructions switch also could be faster.
Modification:
Replaced "if else" with a string switch.
Result:
Use new language features
Motivation:
Since Java 7 we can automatically close resources in try () construction.
Modification:
Changed all try catches in the code with autoclose try (resource)
Result:
Less boiler-plate
Motivation:
Current implementation extract header value as String. We have an idiomatic way for checking presence of a header value.
Modification:
Use HttpHeaders#contains for checking if if contains Expect: 100-continue.
Result:
Use idiomatic way + simplify boolean logic.
Motivation:
While we are not yet quite sure if we want to require Java11 as minimum we are at least sure we want to use java8 as minimum.
Modifications:
Change minimum version to java8 and update some tests which failed compilation after this change.
Result:
Use Java8 as minimum and be able to use Java8 features.
Motivation:
I want to fix bug in vert.x project (eclipse-vertx/vert.x#2562) caused by ComposedLastHttpContent result being null. I don't know if it is intentional that this last decoded chuck in the issue returns null, but if not - I am providing fix for that.
Modification:
* Added new constructor in ComposedLastHttpContent allowing to pass DecoderResult
* set DecoderResult.SUCCESS for created ComposedLastHttpContent in HttpContentEncoder
* set DecoderResult.SUCCESS for created ComposedLastHttpContent in HttpContentDecoder
Result:
Fixeseclipse-vertx/vert.x#2562
Motivation:
The CorruptedFrameException from the finish() method of the Utf8Validator gets propagated to other handlers while the connection is still open.
Modification:
Override exceptionCaught method of the Utf8FrameValidator and close the connection if it is a CorruptedFrameException.
Result:
The CorruptedFrameException gets propagated to other handlers only after properly closing the connection.
Motivation:
At the moment it’s possible to have a Channel in Netty that is not registered / assigned to an EventLoop until register(...) is called. This is suboptimal as if the Channel is not registered it is also not possible to do anything useful with a ChannelFuture that belongs to the Channel. We should think about if we should have the EventLoop as a constructor argument of a Channel and have the register / deregister method only have the effect of add a Channel to KQueue/Epoll/... It is also currently possible to deregister a Channel from one EventLoop and register it with another EventLoop. This operation defeats the threading model assumptions that are wide spread in Netty, and requires careful user level coordination to pull off without any concurrency issues. It is not a commonly used feature in practice, may be better handled by other means (e.g. client side load balancing), and therefore we propose removing this feature.
Modifications:
- Change all Channel implementations to require an EventLoop for construction ( + an EventLoopGroup for all ServerChannel implementations)
- Remove all register(...) methods from EventLoopGroup
- Add ChannelOutboundInvoker.register(...) which now basically means we want to register on the EventLoop for IO.
- Change ChannelUnsafe.register(...) to not take an EventLoop as parameter (as the EventLoop is supplied on custruction).
- Change ChannelFactory to take an EventLoop to create new Channels and introduce ServerChannelFactory which takes an EventLoop and one EventLoopGroup to create new ServerChannel instances.
- Add ServerChannel.childEventLoopGroup()
- Ensure all operations on the accepted Channel is done in the EventLoop of the Channel in ServerBootstrap
- Change unit tests for new behaviour
Result:
A Channel always has an EventLoop assigned which will never change during its life-time. This ensures we are always be able to call any operation on the Channel once constructed (unit the EventLoop is shutdown). This also simplifies the logic in DefaultChannelPipeline a lot as we can always call handlerAdded / handlerRemoved directly without the need to wait for register() to happen.
Also note that its still possible to deregister a Channel and register it again. It's just not possible anymore to move from one EventLoop to another (which was not really safe anyway).
Fixes https://github.com/netty/netty/issues/8513.
Motivation:
The `maxChunkSize` only serves to split available content into even
smaller chunks which is not all that useful since the data is already
buffered.
Modification:
Remove the parameter.
Result:
Things are simpler.
Fixes#8430.
Motivation:
RFC 6455 doesn't define close status codes 1012, 1013 and 1014.
Yet, since then, IANA has defined them and web browsers support them.
From https://www.iana.org/assignments/websocket/websocket.xhtml:
* 1012: Service Restart
* 1013: Try Again Later
* 1014: The server was acting as a gateway or proxy and received an invalid response from the upstream server. This is similar to 502 HTTP Status Code.
Modification:
Make status codes 1012, 1013 and 1014 legit.
Result:
WebSocket status codes as defined by IANA are supported.
Motivation:
ByteBuf supports “marker indexes”. The intended use case for these is if a speculative operation (e.g. decode) is in process the user can “mark” and interface and refer to it later if the operation isn’t successful (e.g. not enough data). However this is rarely used in practice,
requires extra memory to maintain, and introduces complexity in the state management for derived/pooled buffer initialization, resizing, and other operations which may modify reader/writer indexes.
Modifications:
Remove support for marking and adjust testcases / code.
Result:
Fixes https://github.com/netty/netty/issues/8535.
Motivation:
Most of the maven modules do not explicitly declare their
dependencies and rely on transitivity, which is not always correct.
Modifications:
For all maven modules, add all of their dependencies to pom.xml
Result:
All of the (essentially non-transitive) depepdencies of the modules are explicitly declared in pom.xml
Motivation:
According to the HTTP spec set-cookie headers should not be combined
because they are not using the list syntax.
Modifications:
Do not combine set-cookie headers.
Result:
Set-Cookie headers won't be combined anymore
Motivation:
As mentioned in RFC 7692 :
The "server_no_context_takeover" Extension Parameter should be used on server side for compression and on client side for decompression.
The "client_no_context_takeover" Extension Parameter should be used on client side for compression and on server side for decompression.
Right now, in PerMessageDeflateClientExtensionHandshaker, the decoder uses clientNoContext instead of serverNoContext and the encoder uses serverNoContext instead of clientNoContext.
The same inversion is present in PerMessageDeflateServerExtensionHandshaker: the decoder uses
serverNoContext instead of clientNoContext, while the encoder uses serverNoContext instead of clientNoContext. Besides the context inversion, the sliding window sizes seem to be inversed as well.
Modification:
Inverse clientNoContext with serverNoContext and clientWindowSize with serverWindowSize for both the Decoder and Encoder in PerMessageDeflateServerExtensionHandshaker and PerMessageDeflateClientExtensionHandshaker.
Result:
This fixes the decompression fail in the case that one of the contexts is set and the other one is not.
Motivation:
Get charset from Content-Type header even it contains multiple parameters.
Modification:
Extract charset value from the charset parameter if it is not last.
Result:
Fixes#8273
Motivation:
Implementation of WebSocketUtil/randomNumber is incorrect and might violate
the API returning values > maximum specified.
Modifications:
* WebSocketUtil/randomNumber is reimplemented, the idea of the solution described
in the comment in the code
* Implementation of WebSocketUtil/randomBytes changed to nextBytes method
* PlatformDependet.threadLocalRandom is used instead of Math.random to improve efficiency
* Added test cases to check random numbers generator
* To ensure corretness, we now assert that min < max when generating random number
Result:
WebSocketUtil/randomNumber always produces correct result.
Covers https://github.com/netty/netty/issues/8023
Motivation:
If a wrapped cookie value with an invalid charcater is passed to the strict
encoder, an exception is thrown on validation but the error message contains
a character at the wrong position.
Modifications:
Print `unwrappedValue.charAt(pos)` instead of `value.charAt(pos)`.
Result:
The exception indicates the correct invalid character in the unwrapped cookie.
Motivation
The HttpObjectEncoder raises an IllegalStateException due to an illegal state but doesn't mention what the state was. It could be useful for debugging purposes to figure out what happened.
Modifications
Mention the HttpObjectEncoder's state in the message of the IllegalStateException.
Result
An exception with more information what caused it.
Motivation:
Currently, when passing custom headers to a WebSocketClientHandshaker,
if values are added for headers that are reserved for use in the
websocket handshake performed with the server, these custom values can
be used by the server to compute the websocket handshake challenge. If
the server computes the response to the challenge with the custom header
values, rather than the values computed by the client handshaker, the
handshake may fail.
Modifications:
Update the client handshaker implementations to add the custom header
values first, and then set the reserved websocket header values.
Result:
Reserved websocket handshake headers, if present in the custom headers
passed to the client handshaker, will not be propagated to the server.
Instead the client handshaker will propagate the values it generates.
Fixes#7973.
Motivation:
The websockets abstract test suite does not run against the 08
implementation in the 08 version of the test suite.
Modifications:
Update the WebSocketClientHandshaker08Test to instantiate a new
WebSocketClientHandshaker08 rather than an 07 handshaker.
Result:
The WebSocketClientHandshaker08Test now tests the 08 implementation.
Motivation:
Currently, on recipt of a PongWebSocketFrame, the
WebSocketProtocolHandler will drop the frame, rather than passing it
along so it can be referenced by other handlers.
Modifications:
Add boolean field to WebSocketProtocolHandler to indicate whether Pong
frames should be dropped or propagated, defaulting to "true" to preserve
existing functionality.
Add new constructors to the client and server implementations of
WebSocketProtocolHandler that allow for overriding the behavior for the
handling of Pong frames.
Result:
PongWebSocketFrames are passed along the channel, if specified.
Motivation:
DefaultHttpResponse did not respect its status when compute the hashCode and check for equality.
Modifications:
Correctly implement hashCode and equals
Result:
Fixes https://github.com/netty/netty/issues/7964.
Motivation:
HTTP responses with status of 205 should not contain a payload. We should enforce this.
Modifications:
Correctly handle responses with status 205 and payload by set Content-Length: 0 header and stripping out the content.
Result:
Fixes https://github.com/netty/netty/issues/7888
Motivation:
It should be possible to call setContent(Unpooled.EMPTY_BUFFER) multiple times just like its possible to do the same with a non empty buffer.
Modifications:
- Correctly reset underlying storage if called multiple times.
- Add tests
Result:
Fixes https://github.com/netty/netty/issues/6418
Motivation:
NPE in `CorsHandler` if a pre-flight request is done using an Origin header which is not allowed by any `CorsConfig` passed to the handler on creation.
Modifications:
During the pre-flight, check the `CorsConfig` for `null` and handle it correctly by not returning any access-control header
Result:
No more NPE for pre-flight requests with unauthorized origins.
Motivation:
Some `if` statements contains common parts that can be extracted.
Modifications:
Extract common parts from `if` statements.
Result:
Less code and bytecode. The code is simpler and more clear.
Motivation:
Finer granularity when configuring CorsHandler, enabling different policies for different origins.
Modifications:
The CorsHandler has an extra constructor that accepts a List<CorsConfig> that are evaluated sequentially when processing a Cors request
Result:
The changes don't break backwards compatibility. The extra ctor can be used to provide more than one CorsConfig object.
Motivation:
NPE in `ClientCookieDecoder` if cookie starts with comma.
Modifications:
Check `cookieBuilder` for `null` in the return.
Result:
No fails NPE on invalid cookies.
Motivation:
Unnecessary flushes reduce the amount of flush coalescing that can happen at higher levels and thus can increase number of packets (because of TCP_NODELAY) and lower throughput (due to syscalls, TLS frames, etc)
Modifications:
Replace writeAndFlush(...) with write(...)
Result:
Fixes https://github.com/netty/netty/issues/7837.
Motivation:
There may be meaningful 'connection' headers that exist on a request
that is used to attempt a HTTP/1.x upgrade request that will be
clobbered.
Modifications:
HttpClientUpgradeHandler uses the `HttpHeaders.add` instead of
`HttpHeaders.set` when adding the 'upgrade' field.
Result:
Fixes#7823, existing 'connection' headers are preserved.
Motivation:
There is a race between both flushing the upgrade response and receiving
more data before the flush ChannelPromise can fire and reshape the
pipeline. Since We have already committed to an upgrade by writing the
upgrade response, we need to be immediately prepared for handling the
next protocol.
Modifications:
The pipeline reshaping logic in HttpServerUpgradeHandler has been moved
out of the ChannelFutureListener attached to the write of the upgrade
response and happens immediately after the writeAndFlush call, but
before the method returns.
Result:
The pipeline is no longer subject to receiving more data before the
pipeline has been reformed.
Motivation:
HttpProxyHandler uses `NetUtil#toSocketAddressString` to compute
CONNECT url and Host header.
The url is correct when the address is unresolved, as
`NetUtil#toSocketAddressString` will then use
`getHoststring`/`getHostname`. If the address is already resolved, the
url will be based on the IP instead of the hostname.
There’s an additional minor issue with the Host header: default port
443 should be omitted.
Modifications:
* Introduce NetUtil#getHostname
* Introduce HttpUtil#formatHostnameForHttp to format an
InetSocketAddress to
HTTP format
* Change url computation to favor hostname instead of IP
* Introduce HttpProxyHandler ignoreDefaultPortsInConnectHostHeader
parameter to ignore 80 and 443 ports in Host header
Result:
HttpProxyHandler performs properly when connecting to a resolved address
Motivation:
When the response is very small, compression will inflate the response.
Modifications:
Add filed io.netty.handler.codec.http.HttpContentCompressor#compressThreshold that control whether the HTTP response should be compressed.
Result:
Fixes#7660.
Motivation:
A Malformed empty header value (e.g. Content-Type: \r\n) will trigger a String index out of range
while trying to parse the multi-part request, using the HttpPostMultipartRequestDecoder.
Modification:
Ensure that the substring() method is called passing the endValue >= valueStart.
In case of an empty header value, the empty header value associated with the header key will be returned.
Result:
Fixes#7620
Motivation:
Usages of HttpResponseStatus may result in more object allocation then necessary due to not looking for cached objects and the AsciiString parsing method not being used due to CharSequence method being used instead.
Modifications:
- HttpResponseDecoder should attempt to get the HttpResponseStatus from cache instead of allocating a new object
- HttpResponseStatus#parseLine(CharSequence) should check if the type is AsciiString and redirect to the AsciiString parsing method which may not require an additional toString call
- HttpResponseStatus#parseLine(AsciiString) can be optimized and doesn't require and may not require object allocation
Result:
Less allocations when dealing with HttpResponseStatus.
Motivation:
DefaultHttpDataFactory uses HttpRequest as map keys.
Because of the implementation of "hashCode"" and "equals" in DefaultHttpRequest,
if we use normal maps, HttpDatas of different requests may end up in the same map entry,
causing cleanup bug.
Consider this example:
- Suppose that request1 is equal to request2, causing their HttpDatas to be stored in one single map entry.
- request1 is cleaned up first, while request2 is still being decoded.
- Consequently request2's HttpDatas are suddenly gone, causing NPE, or worse loss of data.
This bug can be reproduced by starting the HttpUploadServer example,
then run this command:
ab -T 'application/x-www-form-urlencoded' -n 100 -c 5 -p post.txt http://localhost:8080/form
post.txt file content:
a=1&b=2
There will be errors like this:
java.lang.NullPointerException
at io.netty.handler.codec.http.multipart.MemoryAttribute.getValue(MemoryAttribute.java:64)
at io.netty.handler.codec.http.multipart.MixedAttribute.getValue(MixedAttribute.java:243)
at io.netty.example.http.upload.HttpUploadServerHandler.writeHttpData(HttpUploadServerHandler.java:271)
at io.netty.example.http.upload.HttpUploadServerHandler.readHttpDataChunkByChunk(HttpUploadServerHandler.java:230)
at io.netty.example.http.upload.HttpUploadServerHandler.channelRead0(HttpUploadServerHandler.java:193)
at io.netty.example.http.upload.HttpUploadServerHandler.channelRead0(HttpUploadServerHandler.java:66)
at io.netty.channel.SimpleChannelInboundHandler.channelRead(SimpleChannelInboundHandler.java:105)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:340)
at io.netty.handler.codec.MessageToMessageDecoder.channelRead(MessageToMessageDecoder.java:102)
at io.netty.handler.codec.MessageToMessageCodec.channelRead(MessageToMessageCodec.java:111)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:340)
at io.netty.handler.codec.ByteToMessageDecoder.fireChannelRead(ByteToMessageDecoder.java:310)
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:284)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:340)
at io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1412)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:943)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:141)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:645)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:580)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:497)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:459)
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:886)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.lang.Thread.run(Thread.java:748)
Modifications:
Keep identity of requests by using IdentityHashMap
Result:
DefaultHttpDataFactory is fixed.
The ConcurrentHashMap is replaced with a synchronized map, but I think the performance won't be affected much in real web apps.
Motiviation:
In our replace(...) methods we always used validation for the newly created headers while the original headers may not use validation at all.
Modifications:
- Only use validation if the original headers used validation as well.
- Ensure we create a copy of the headers in replace(...).
Result:
Fixes [#5226]
Automatic-Module-Name entry provides a stable JDK9 module name, when Netty is used in a modular JDK9 applications. More info: http://blog.joda.org/2017/05/java-se-9-jpms-automatic-modules.html
When Netty migrates to JDK9 in the future, the entry can be replaced by actual module-info descriptor.
Modification:
The POM-s are configured to put the correct module names to the manifest.
Result:
Fixes#7218.
Motivation:
HttpObjectDecoder will throw a TooLongFrameException when either the max size for the initial line or the header size was exceeed. We have no tests for this.
Modifications:
Add test cases.
Result:
More tests.
Motivation:
DefaultHttpHeader.names() exposes HTTP header names as a Set<String>. Converting the resulting set to an array using toArray(String[]) throws an exception: java.lang.ArrayStoreException: io.netty.util.AsciiString.
Modifications:
- Remove our custom implementation of toArray(...) (and others) by just extending AbstractCollection.
- Add unit test
Result:
Fixes [#7428].
Motivation:
For debugging/logging purpose, it would be convenient to have
HttpHeaders#toString implemented.
DefaultHeaders does implement toString be the implementation is suboptimal and allocates a Set for the names and Lists for values.
Modification:
* Introduce HeadersUtil#toString that provides a convenient optimized helper to implement toString for various headers implementations
* Have DefaultHeaders#toString and HttpHeaders#toString delegate their toString implementation to HeadersUtil
Result:
Convenient HttpHeaders#toString. Optimized DefaultHeaders#toString.
Motivation:
Its possible that cleanup() will throw if invalid data is passed into the wrapped EmbeddedChannel. We need to ensure we still call channelInactive(...) in this case.
Modifications:
- Correctly forward Exceptions caused by cleanup()
- Ensure all content is released when cleanup() throws
- Add unit tests
Result:
Correctly handle the case when cleanup() throws.
Motivation:
https://github.com/netty/netty/issues/7418 reported an issue with writing a LastHttpContent with trailers set.
Modifications:
Add unit test to ensure this issue is fixed in latest netty release.
Result:
Ensure code is correct.
Motivation:
HttpMethod#valueOf shows up on profiler results in the top set of
results. Since it is a relatively simple operation it can be improved in
isolation.
Modifications:
- Introduce a special case map which assigns each HttpMethod to a unique
index in an array and provides constant time lookup from a hash code
algorithm. When the bucket is matched we can then directly do equality
comparison instead of potentially following a linked structure when
HashMap has hash collisions.
Result:
~10% improvement in benchmark results for HttpMethod#valueOf
Benchmark Mode Cnt Score Error Units
HttpMethodMapBenchmark.newMapKnownMethods thrpt 16 31.831 ± 0.928 ops/us
HttpMethodMapBenchmark.newMapMixMethods thrpt 16 25.568 ± 0.400 ops/us
HttpMethodMapBenchmark.newMapUnknownMethods thrpt 16 51.413 ± 1.824 ops/us
HttpMethodMapBenchmark.oldMapKnownMethods thrpt 16 29.226 ± 0.330 ops/us
HttpMethodMapBenchmark.oldMapMixMethods thrpt 16 21.073 ± 0.247 ops/us
HttpMethodMapBenchmark.oldMapUnknownMethods thrpt 16 49.081 ± 0.577 ops/us
Motivation:
In order to determine if a header contains a value we currently rely
upon getAll(..) and regular expressions. This operation is commonly used
during the encode and decode stage to determine the transfer encoding
(e.g. HttpUtil#isTransferEncodingChunked). This operation requires an
intermediate collection and possibly regular expressions for the
CombinedHttpHeaders use case which can be expensive.
Modifications:
- Add a valuesIterator to HttpHeaders and specializations of this method
for DefaultHttpHeaders, ReadOnlyHttpHeaders, and CombinedHttpHeaders.
Result:
Less intermediate collections and allocation overhead when determining
if HttpHeaders contains a name/value pair.
Motivation:
If the HttpUtil class is initialized before HttpHeaders or
EmptyHttpHeaders, EmptyHttpHeaders.INSTANCE will be null. This
can lead to NPEs in code that relies on this field being
non-null. One example is the
LastHttpContent.EMPTY_LAST_CONTENT.trailingHeaders method.
Modifications:
- Move HttpUtil.EMPTY_HEADERS to a private static final inner class
of EmptyHttpHeaders called InstanceInitializer.
- Add tests, that when run in isolation, validate the fix for the issue.
Result:
Any initialization order of HttpUtil, EmptyHttpHeaders or
HttpHeaders will result in EmptyHttpHeaders.INSTANCE being initialized
correctly.
Motivation:
According to RFC 7231 the server may choose to:
```
indicate a zero-length payload for the response by including a
Transfer-Encoding header field with a value of chunked and a message
body consisting of a single chunk of zero-length
```
https://tools.ietf.org/html/rfc7231#page-53
In such cases the exception below appears during decoding phase:
```
java.lang.IllegalArgumentException: invalid version format: 0
at io.netty.handler.codec.http.HttpVersion.<init>(HttpVersion.java:121)
at io.netty.handler.codec.http.HttpVersion.valueOf(HttpVersion.java:76)
at io.netty.handler.codec.http.HttpResponseDecoder.createMessage(HttpResponseDecoder.java:118)
at io.netty.handler.codec.http.HttpObjectDecoder.decode(HttpObjectDecoder.java:219)
```
Modifications:
HttpObjectDecoder.isContentAlwaysEmpty specifies content NOT empty
when 205 Reset Content response
Result:
There is no `IllegalArgumentException: invalid version format: 0`
when handling 205 Reset Content response with transfer-encoding
Motivation:
93130b172a introduced a regression where we not "converted" an empty HttpContent to ByteBuf and just passed it on in the pipeline. This can lead to the situation that other handlers in the pipeline will see HttpContent instances which is not expected.
Modifications:
- Correctly convert HttpContent to ByteBuf when empty
- Add unit test.
Result:
Handlers in the pipeline will see the expected message type.
Motivation:
For use cases that create headers, but do not need to modify them a read only variant of HttpHeaders would be useful and may be able to provide better iteration performance for encoding.
Modifications:
- Introduce ReadOnlyHttpHeaders that is backed by a flat array
Result:
ReadOnlyHttpHeaders exists for non-modifiable HttpHeaders use cases.
Motivation:
7995afee8f introduced a change that broke special handling of WebSockets 00.
Modifications:
Correctly delegate to super method which has special handling for WebSockets 00.
Result:
Fixes [#7362].
Motivation:
HttpObjectEncoder and MessageAggregator treat buffers that are not readable special. If a buffer is not readable, then an EMPTY_BUFFER is written and the actual buffer is ignored. If the buffer has already been released then this will not be correct as the promise will be completed, but in reality the original content shouldn't have resulted in any write because it was invalid.
Modifications:
- HttpObjectEncoder should retain/write the original buffer instead of using EMPTY_BUFFER
- MessageAggregator should retain/write the original ByteBufHolder instead of using EMPTY_BUFFER
Result:
Invalid write operations which happen to not be readable correctly reflect failed status in the promise, and do not result in any writes to the channel.
This change allows to upgrade a plain HTTP 1.x connection to TLS
according to RFC 2817. Switching the transport layer to TLS should be
possible without removing HttpClientCodec from the pipeline,
because HTTP/1.x layer of the protocol remains untouched by the switch
and the HttpClientCodec state must be retained for proper
handling the remainder of the response message,
per RFC 2817 requirement in point 3.3:
Once the TLS handshake completes successfully, the server MUST
continue with the response to the original request.
After this commit, the upgrade can be established by simply
inserting an SslHandler at the front of the pipeline after receiving
101 SWITCHING PROTOCOLS response, exactly as described in SslHander
documentation.
Modifications:
- Don't set HttpObjectDecoder into UPGRADED state if
101 SWITCHING_PROTOCOLS response contains HTTP/1.0 or HTTP/1.1 in
the protocol stack described by the Upgrade header.
- Skip pairing comparison for 101 SWITCHING_PROTOCOLS, similar
to 100 CONTINUE, since 101 is not the final response to the original
request and the final response is expected after TLS handshake.
Fixes#7293.
Motivation:
I am receiving a multipart/form_data upload from a Mailgun webhook. This webhook used to send parts like this:
--74e78d11b0214bdcbc2f86491eeb4902
Content-Disposition: form-data; name="attachment-2"; filename="attached_�айл.txt"
Content-Type: text/plain
Content-Length: 32
This is the content of the file
--74e78d11b0214bdcbc2f86491eeb4902--
but now it posts parts like this:
--74e78d11b0214bdcbc2f86491eeb4902
Content-Disposition: form-data; name="attachment-2"; filename*=utf-8''attached_%D1%84%D0%B0%D0%B9%D0%BB.txt
This is the content of the file
--74e78d11b0214bdcbc2f86491eeb4902--
This new format uses field parameter encoding described in RFC 5987. More about this encoding can be found here.
Netty does not parse this format. The result is the filename is not decoded and the part is not parsed into a FileUpload.
Modification:
Added failing test in HttpPostRequestDecoderTest.java and updated HttpPostMultipartRequestDecoder.java
Refactored to please Netkins
Result:
Fixes:
HttpPostMultipartRequestDecoder identifies the RFC 5987 format and parses it.
Previous functionality is retained.
Motivation:
Before this commit, it is impossible to access the path component of the
URI before it has been decoded. This makes it impossible to distinguish
between the following URIs:
/user/title?key=value
/user%2Ftitle?key=value
The user could already access the raw uri value, but they had to calculate
pathEndIdx themselves, even though it might already be cached inside
QueryStringDecoder.
Result:
The user can easily and efficiently access the undecoded path and query.
Motivation:
An `origin`/`sec-websocket-origin` header value in websocket client is filling incorrect in some cases:
- Hostname is not converting to lower-case as prescribed by RFC 6354 (see [1]).
- Selecting a `http` scheme when source URI has `wss`/`https` scheme and non-standard port.
Modifications:
- Convert uri-host to lower-case.
- Use a `https` scheme if source URI scheme is `wss`/`https`, or if source scheme is null and port == 443.
Result:
Correct filling an `origin` header for WS client.
[1] https://tools.ietf.org/html/rfc6454#section-4
Motivation:
Even if it's a super micro-optimization (most JVM could optimize such
cases in runtime), in theory (and according to some perf tests) it
may help a bit. It also makes a code more clear and allows you to
access such methods in the test scope directly, without instance of
the class.
Modifications:
Add 'static' modifier for all methods, where it possible. Mostly in
test scope.
Result:
Cleaner code with proper 'static' modifiers.
Motivation:
During code read of the Netty codebase I noticed that the Netty
HttpServerUpgradeHandler unconditionally sets a Content-Length: 0
header on 101 Switching Protocols responses. This explicitly
contravenes RFC 7230 Section 3.3.2 (Content-Length), which notes
that:
A server MUST NOT send a Content-Length header field in any
response with a status code of 1xx (Informational) or 204
(No Content).
While it is unlikely that any client will ever be confused by
this behaviour, there is no reason to contravene this part of the
specification.
Modifications:
Removed the line of code setting the header field and changed the
only test that expected it to be there.
Result:
When performing the server portion of HTTP upgrade, the 101
Switching Protocols response will no longer contain a
Content-Length: 0 header field.
Motivation:
#7269 removed an unnecessary instanciation for verifying WebSocket
handshake status code.
But it uses a hardcoded status code value for 101 instead of using the
intended `HttpResponseStatus#SWITCHING_PROTOCOLS` constant.
Modidication:
Compare actual `HttpResponseStatus` against predefined constant. Note
that `HttpResponseStatus#equals` is implemented in respect with the RFC
(only honor code, not text) so it’s intended to be used this way.
Result:
Cleaner code, use intended constant instead of hard coded value.
Motivation:
https://github.com/netty/netty/issues/7253
Modifications:
Adding `Content-Length: 0` to `CorsHandler.forbidden()` and `CorsHandler.handlePreflight()`
Result:
Contexts that are terminated by the CorsHandler will always include a Content-Length header
Motivation:
- In the `HttpResponseStatus#equals` checks only status code. No need to create new instance of `HttpResponseStatus` for comparison with response status.
- The RFC says: `the HTTP version and reason phrase aren't important` [1].
Modifications:
Use comparison by status code without creating new `HttpResponseStatus`.
Result:
Less allocations, more clear code.
[1] https://tools.ietf.org/html/draft-ietf-hybi-thewebsocketprotocol-00
Motivation:
We need to ensure we not write any body when a response with status code of 1xx, 204 or 304 is used as stated in rfc:
https://tools.ietf.org/html/rfc7230#section-3.3.3
Modifications:
- Correctly handle status codes
- Add unit tests
Result:
Correctly handle responses with 1xx, 204, 304 status codes.
Motivation:
HttpObjectEncoder allocates a new buffer when encoding the initial line and headers, and also allocates a buffer when encoding the trailers. The allocation always uses the default size of 256. This may lead to consistent under allocation and require a few resize/copy operations which can cause GC/memory pressure.
Modifications:
- Introduce a weighted average which tracks the historical size of encoded data and uses this as an estimate for future buffer allocations
Result:
Better approximation of buffer sizes.
Motivation:
ServerCookieEncoder’s javadoc contains some invalid copy-pasting from
ClientCookieEncoder.
Modifications:
* As per RFC6265, multiple cookies are sent as separate Set-Cookie
response headers.
* Fix code sample
Result:
Proper javadoc
This reverts commit d63bb4811e as this not covered correctly all cases and so could lead to missing fireChannelReadComplete() calls. We will re-evalute d63bb4811e and resbumit a pr once we are sure all is handled correctly
Motivation:
The `AsciiString#toString` method calculate string value and cache it into field. If an `AsciiString` created from the `String` value, we can avoid rebuilding strings if we cache them immediately when creating `AsciiString`. It would be useful for constants strings, which already stored in the JVMs string table, or in cases where an unavoidable `#toString `method call is assumed.
Modifications:
- Add new static method `AsciiString#cache(String)` which save string value into cache field.
- Apply a "benign" data race in the `#hashCode` and `#toString` methods.
Result:
Less memory usage in some `AsciiString` use cases.
Motivation:
HttpObjectAggregator differs from HttpServerExpectContinueHandler's handling
of expect headers by not stripping the 'expect' header when a response
is generated.
Modifications:
HttpObjectAggregator now removes the 'expect' header in cases where it generates
a response.
Result:
Consistent and correct behavior between HttpObjectAggregator and HttpServerExpectContinueHandler.
Motivation:
Issue #6695 states that there is an issue when writing empty content via HttpResponseEncoder.
Modifications:
Add two test-cases.
Result:
Verified that all works as expected.
Motivation:
Its wasteful and also confusing that channelReadComplete() is called even if there was no message forwarded to the next handler.
Modifications:
- Only call ctx.fireChannelReadComplete() if at least one message was decoded
- Add unit test
Result:
Less confusing behavior. Fixes [#4312].
Motivation:
08748344d8 introduced two new tests which did not take into account that the multipart delimiter can be between 2 and 16 bytes long.
Modifications:
Take the multipart delimiter length into account.
Result:
Fixes [#7001]
Motivation:
codec-http2 currently does not strictly enforce the HTTP/1.x semantics with respect to the number of headers defined in RFC 7540 Section 8.1 [1]. We currently don't validate the number of headers nor do we validate that the trailing headers should indicate EOS.
[1] https://tools.ietf.org/html/rfc7540#section-8.1
Modifications:
- DefaultHttp2ConnectionDecoder should only allow decoding of a single headers and a single trailers
- DefaultHttp2ConnectionEncoder should only allow encoding of a single headers and optionally a single trailers
Result:
Constraints of RFC 7540 restricting the number of headers/trailers is enforced.
Motivation:
HttpPostRequestEncoder maintains an internal buffer that holds the
current encoded data. There are use cases when this internal buffer
becomes null, the next chunk processing implementation should take
this into consideration.
Modifications:
- When preparing the last chunk if currentBuffer is null, mark
isLastChunkSent as true and send LastHttpContent.EMPTY_LAST_CONTENT
- When calculating the remaining size take into consideration that the
currentBuffer might be null
- Tests are based on those provided in the issue by @nebhale and @bfiorini
Result:
Fixes#5478
Motivation:
- A `HttpPostMultipartRequestDecoder` contains two pairs of the same methods: `readFileUploadByteMultipartStandard`+`readFileUploadByteMultipart` and `loadFieldMultipartStandard`+`loadFieldMultipart`.
- These methods use `NotEnoughDataDecoderException` to detecting not last data chunk (exception handling is very expensive).
- These methods can be greatly simplified.
- Methods `loadFieldMultipart` and `loadFieldMultipartStandard` has an unnecessary catching for the `IndexOutOfBoundsException`.
Modifications:
- Remove duplicate methods.
- Replace handling `NotEnoughDataDecoderException` by the return of a boolean result.
- Simplify code.
Result:
The code is cleaner and easier to support. Less exception handling logic.
Motivation:
1. Some encoders used a `ByteBuf#writeBytes` to write short constant byte array (2-3 bytes). This can be replaced with more faster `ByteBuf#writeShort` or `ByteBuf#writeMedium` which do not access the memory.
2. Two chained calls of the `ByteBuf#setByte` with constants can be replaced with one `ByteBuf#setShort` to reduce index checks.
3. The signature of method `HttpHeadersEncoder#encoderHeader` has an unnecessary `throws`.
Modifications:
1. Use `ByteBuf#writeShort` or `ByteBuf#writeMedium` instead of `ByteBuf#writeBytes` for the constants.
2. Use `ByteBuf#setShort` instead of chained call of the `ByteBuf#setByte` with constants.
3. Remove an unnecessary `throws` from `HttpHeadersEncoder#encoderHeader`.
Result:
A bit faster writes constants into buffers.
Motivation:
Right now HttpRequestEncoder does insertion of slash for url like http://localhost?pararm=1 before the question mark. It is done not effectively.
Modification:
Code:
new StringBuilder(len + 1)
.append(uri, 0, index)
.append(SLASH)
.append(uri, index, len)
.toString();
Replaced with:
new StringBuilder(uri)
.insert(index, SLASH)
.toString();
Result:
Faster HttpRequestEncoder. Additional small test. Attached benchmark in PR.
Benchmark Mode Cnt Score Error Units
HttpRequestEncoderInsertBenchmark.newEncoder thrpt 40 3704843.303 ± 98950.919 ops/s
HttpRequestEncoderInsertBenchmark.oldEncoder thrpt 40 3284236.960 ± 134433.217 ops/s
Motivation:
1. `ByteBuf` contains methods to writing `CharSequence` which optimized for UTF-8 and ASCII encodings. We can also apply optimization for ISO-8859-1.
2. In many places appropriate methods are not used.
Modifications:
1. Apply optimization for ISO-8859-1 encoding in the `ByteBuf#setCharSequence` realizations.
2. Apply appropriate methods for writing `CharSequences` into buffers.
Result:
Reduce overhead from string-to-bytes conversion.
Motivation:
These headers can be used to prevent clickjacking.
Modifications:
Add static fields for content-security-policy and x-frame-options
Result:
Expose general useful names
Motivation:
A life cycle of QueryStringEncoder is simple: create, append params, convert to String. Current realization collect params in the list, and calculate an URI string in `toString` method. We can simplify this: don't store params to the list, and immediately append parameters to the `StringBuilder`.
Modifications:
- Remove list for params and remove a tuple class `Param`.
- Use one common `StringBuilder` and append parameters into it.
- Resolve `TODO` in the `encodeParam` method.
Result:
Less allocations (no `ArrayList`, no `Param` tuples). Second `toString` call is faster.
Motivation:
PR #6811 introduced a public utility methods to decode hex dump and its parts, but they are not visible from netty-common.
Modifications:
1. Move the `decodeHexByte`, `decodeHexDump` and `decodeHexNibble` methods into `StringUtils`.
2. Apply these methods where applicable.
3. Remove similar methods from other locations (e.g. `HpackHex` test class).
Result:
Less code duplication.
Motivation:
If the content-length does not parse as a number, leniency causes this
to instead be parsed as the default value. This leads to bodies being
silently ignored on requests which can be incredibly dangerous. Instead,
if the content-length header is invalid, an exception should be thrown
for upstream handling.
Modifications:
This commit removes the leniency in parsing the content-length header by
allowing a number format exception, if thrown, to escape from the method
rather than falling back to the default value.
Result:
In invalid content-length header will not be silently ignored.
Motivation:
For multi-line headers HttpObjectDecoder uses StringBuilder.append(a).append(b) pattern that could be easily replaced with regular a + b. Also oparations with a and b moved out from concat operation to make it friendly for StringOptimizeConcat optimization and thus - faster.
Modification:
StringBuilder.append(a).append(b) reaplced with a + b. Operations with a and b moved out from concat oparation.
Result:
Code simpler to read and faster.
Motivation:
The class `HttpPostRequestEncoder` has minor issues:
- The `encodeNextChunkMultipart()` method contains two identical blocks of code with a difference only in the cast interfaces: `Attribute` vs `HttpData`. Because the `Attribute` is extended by `HttpData`, the block with the `Attribute` can be safely deleted.
- The `getNewMultipartDelimiter()` method contains a redundant `toLowerCase()`.
- The `addBodyFileUploads()` method throws `NPE` instead of `IllegalArgumentException`.
Modifications:
- Remove duplicated code block from `encodeNextChunkMultipart()`.
- Remove redundant `toLowerCase()` from `getNewMultipartDelimiter()`.
- Replace `NPE` with `IllegalArgumentException` in `addBodyFileUploads()`.
- Use `ObjectUtil#checkNotNull` where possible.
Result:
More correct and clean code.
Motivations:
1. There are duplicated implementations of decoding hex strings. #6797
2. ByteBufUtil.HexUtil.decodeHexDump does not handle substring start
index properly and does not decode hex byte rigorously.
Modifications:
1. Function decodeHexByte is moved from QueryStringDecoder into ByteBufUtil.
2. ByteBufUtil.HexUtil.decodeHexDump is changed to use decodeHexByte.
3. Tests are Updated accordingly.
Result:
Fixed#6797 and made hex decoding functions more robust.
Motivation:
A `SeekAheadNoBackArrayException` used as check for `ByteBuf#hasArray`. The catch of exceptions carries a large overhead on stack trace filling, and this should be avoided.
Modifications:
- Remove the class `SeekAheadNoBackArrayException` and replace its usage with `if` statements.
- Use methods from `ObjectUtils` for better readability.
- Make private methods static where it make sense.
- Remove unused private methods.
Result:
Less of exception handling logic, better performance.
Motivation:
If a full HttpResponse with a Content-Length header is encoded by the HttpContentEncoder subtypes the Content-Length header is removed and the message is set to Transfer-Encoder: chunked. This is an unnecessary loss of information about the message content.
Modifications:
- If a full HttpResponse has a Content-Length header, the header is adjusted after encoding.
Result:
Complete messages continue to have the Content-Length header after encoding.
Motivation:
QueryStringDecoder has several problems:
- doesn't decode correctly path part with `+` (plus) sign in it,
- doesn't cut a `fragment` (after `#`) from query string (see RFC 3986),
- doesn't work correctly with encoding,
- treat `%%` as a percent character escaping (it's don't described in RFC).
Modifications:
- leave `+` chars in a `path` part of uri string,
- ignore `fragment` part (after `#`),
- correctly work with encoding.
- don't treat `%%` as escaping for the `%`.
Result:
Fixed issues from #6745.
Motivation:
Allow subclasses of HttpObjectEncoder other than HttpServerCodec to override the isContentAlwaysEmpty method
Modification:
Change the method visibility from package private to protected
Result:
Fixes#6761
Motivation:
Fix the regression recently introduced that causes already encoded responses to be encoded again as gzip
Modification:
instead of just looking for IDENTITY, anything set for Content-Encoding should be respected and left as-is
added unit tests to capture this use case
Result:
Fixes#6784
Motivation
RFC 1945 (see section 3.1) says that request lines may not have a version in which case the request is assumed to be HTTP/0.9. We don't necessarily want to support that but the existing Exception should indicate the possibility of the request being HTTP/0.9 and give the user a chance to track it down.
Modifications
Indicate in the Exception's message that the request is possibly HTTP/0.9.
Result
Fixes#6739
Motivation:
The status 308 is defined by RFC7538.
This RFC has currently the state Proposed Standard since 2 years, but the status code is already handle by all browsers (Chrome, Firefox, Edge, Safari, …).
To let developer handles easily this status code, it is added into this list.
Modifications:
Added this status code in the list of all status codes and changed the valudOf() method
Result:
Status code 308 included
__Motivation__
`HttpClientCodec` skips HTTP decoding on the connection after a successful HTTP CONNECT response is received.
This behavior follows the spec for a client but pragmatically, if one creates a client to use a proxy transparently, the codec becomes useless after HTTP CONNECT.
Ideally, one should be able to configure whether HTTP CONNECT should result in pass-through or not. This will enable client writers to continue using HTTP decoding even after HTTP CONNECT.
__Modification__
Added overloaded constructors to accept `parseHttpPostConnect`. If this parameter is `true` then the codec continues decoding even after a successful HTTP CONNECT.
Also fixed a bug in the codec that was incrementing request count post HTTP CONNECT but not decrementing it on response. Now, the request count is only incremented if the codec is not `done`.
__Result__
Easier usage by HTTP client writers who wants to connect to a proxy but still decode HTTP for their users for subsequent requests.
Motivation:
Some JUnit assert calls can be replaced by simpler.
Modifications:
Replacement with a more suitable methods.
Result:
More informative JUnit reports.
Motivation:
HttpServerKeepAliveHandler throws unexpected error when I do ctx.writeAndFlush(msg, ctx.voidPromise()); where msg is with header "Connection:close".
Modification:
HttpServerKeepAliveHandler does promise.unvoid() before adding close listener.
Result:
No error for VoidChannelPromise with HttpServerKeepAliveHandler. Fixes [#6698].
Motivation:
It would be more flexible to make getCharset and getMimeType code usable not only for HttpMessage entity but just for any CharSequence. This will improve usability in general purpose code and will help to avoid multiple fetching of ContentType header from a message. It could be done in an external code once and CharSequence method versions could be applied.
Modification:
Expose HttpUtil#getMimeType, HttpUtil#getCharsetAsString, HttpUtil#getCharset versions which works with CharSequence. New methods are reused in the old ones which work with HttpMessage entity.
Result:
More flexible methods set with a good code reusing.
Motivation:
WebSocket decoding throws exceptions on failure that should cause the
pipline to close. These are currently ignored in the
`WebSocketProtocolHandler` and `WebSocketServerProtocolHandler`. In
particular, this means that messages exceding the max message size will
cause the channel to close with no reported failure.
Modifications:
Re-fire the event just before closing the socket to allow it to be
handled appropriately.
Result:
Closes [#3063].
Motivation:
If Content-Encoding: IDENTITY is used we should not try to compress the http message but just let it pass-through.
Modifications:
Remove "!"
Result:
Fixes [#6689]
It is generally useful to have origin http servers respond to
"expect: continue-100" as soon as possible but applications without a
HttpObjectAggregator in their pipelines must use boiler plate to do so.
Modifications:
Introduce the HttpServerExpectContinueHandler handler to make it easier.
Result:
Less boiler plate for http application authors.
Motivation:
DiskFileUpload creates temporary files for storing user uploads containing the user provided file name as part of the temporary file name. While most security problems are prevented by using "new File(userFileName).getName()" a small risk for bugs or security issues remains.
Modifications:
Use a constant string as file name and rely on the callers use of File.createTemp to ensure unique disk file names.
Result:
A slight security improvement at the cost of a little more obfuscated temp file names.
Motivation:
We miss to retain a slice before return it to the user and so an reference count error may accour later on.
Modifications:
Use readRetainedSlice(...) and so ensure we retain the buffer before hand it of to the user.
Result:
Fixes [#6626].
Motivation:
Commit #d675febf07d14d4dff82471829f974369705655a introduced a regression in QueryStringEncoder, resulting in whitespace being converted into a literal `+` sign instead of `%20`.
Modification:
Modify `encodeComponent` to pattern match and replace on the result of the call to `URLEncoder#encode`
Result:
Fixes regression
Motivation:
https://tools.ietf.org/html/rfc7230#section-3.3.2 states that a 204 response MUST NOT include a Content-Length header. If the HTTP version permits keep alive these responses should be treated as keeping the connection alive even if there is no Content-Length header.
Modifications:
- HttpServerKeepAliveHandler#isSelfDefinedMessageLength should account for 204 respones
Result:
Fixes https://github.com/netty/netty/issues/6549.
Motivation:
Currently netty is receiving HTTP request by ByteBuf and store it as "CharSequence" on HttpObjectDecoder. During this operation, all character on ByteBuf is moving to char[] without breaking encoding.
But in process() function, type casting from byte to char does not consider msb (sign-bit). So the value over 127 can be casted wrong value. (ex : 0xec in byte -> 0xffec in char). This is type casting bug.
Modification:
Fix type casting
Result:
Non-latin characters work.
Motivation:
The updated HTTP/1.x RFC allows for header values to be CSV and separated by OWS [1]. CombinedHttpHeaders should remove this OWS on insertion.
[1] https://tools.ietf.org/html/rfc7230#section-7
Modification:
CombinedHttpHeaders doesn't account for the OWS and returns it back to the user as part of the value.
Result:
Fixes#6452
Motivation:
We used some deprecated Mockito methods.
Modifications:
- Replace deprecated method usage
- Some cleanup
Result:
No more usage of deprecated Mockito methods. Fixes [#6482].
Motivation:
Some classes have fields which can be local.
Modifications:
Convert fields to the local variable when possible.
Result:
Clean up. More chances for young generation or scalar replacement.
Motivation:
We only need to add the port to the HOST header value if its not a standard port.
Modifications:
- Only add port if needed.
- Fix parsing of ipv6 address which is enclosed by [].
Result:
Fixes [#6426].
Motivation:
Make code easier to read, make WebSocketServerProtocolHandshakeHandler.getWebSocketLocation method faster.
Modification:
WebSocket path check moved to separate method. Get header operation moved out from concat operation.
Result:
WebSocketServerProtocolHandshakeHandler.getWebSocketLocation is faster as OptimizeStringConcat could be applied. Code easier to read.
Motivation:
QueryStringDecoder and QueryStringEncoder contained some code that could either cleaned-up or optimized.
Modifications:
- Fix typos in exception messages and javadocs
- Precompile Pattern
- Make use of StringUtil.EMPTY_STRING
Result:
Faster and cleaner code.
Motivation:
Calling a static method is faster then dynamic
Modifications:
Add 'static' keyword for methods where it missed
Result:
A bit faster method calls
Motivation:
We have our own ThreadLocalRandom implementation to support older JDKs . That said we should prefer the JDK provided when running on JDK >= 7
Modification:
Using ThreadLocalRandom implementation of the JDK when possible.
Result:
Make use of JDK implementations when possible.
Motivation:
The allowMaskMismatch parameter used throughout websocketx allows frames
with noncompliant masks when set to true, not false.
Modification:
Changed the javadoc comment everywhere it appears.
Result:
Fixes#6387
Motivation:
Today, the HTTP codec in Netty responds to HTTP/1.1 requests containing
an "expect: 100-continue" header and a content-length that exceeds the
max content length for the server with a 417 status (Expectation
Failed). This is a violation of the HTTP specification. The purpose of
this commit is to address this situation by modifying the HTTP codec to
respond in this situation with a 413 status (Request Entity Too
Large). Additionally, the HTTP codec ignores expectations in the expect
header that are currently unsupported. This commit also addresses this
situation by responding with a 417 status.
Handling the expect header is tricky business as the specification (RFC
2616) is more complicated than it needs to be. The specification defines
the legitimate values for this header as "100-continue" and defines the
notion of expectatation extensions. Further, the specification defines a
417 status (Expectation Failed) and this is where implementations go
astray. The intent of the specification was for servers to respond with
417 status when they do not support the expectation in the expect
header.
The key sentence from the specification follows:
The server MUST respond with a 417 (Expectation Failed) status if
any of the expectations cannot be met or, if there are other
problems with the request, some other 4xx status.
That is, a server should respond with a 417 status if and only if there
is an expectation that the server does not support (whether it be
100-continue, or another expectation extension), and should respond with
another 4xx status code if the expectation is supported but there is
something else wrong with the request.
Modifications:
This commit modifies the HTTP codec by changing the handling for the
expect header in the HTTP object aggregator. In particular, the codec
will now respond with 417 status if any expectation other than
100-continue is present in the expect header, the codec will respond
with 413 status if the 100-continue expectation is present in the expect
header and the content-length is larger than the max content length for
the aggregator, and otherwise the codec will respond with 100 status.
Result:
The HTTP codec can now be used to correctly reply to clients that send a
100-continue expectation with a content-length that is too large for the
server with a 413 status, and servers that use the HTTP codec will now
no longer ignore expectations that are not supported (any value other
than 100-continue).
Motivation:
Netty 4.1 introduced AsciiString and defines HttpHeaderNames constants
as such.
It would be convenient to be able to pass them to `exposeHeaders` and
`allowedRequestHeaders` directly without having to call `toString`.
Modifications:
Add `exposeHeaders` and `allowedRequestHeaders` overloads that take a
`CharSequence`.
Result:
More convenient API
Motivation:
DefaultCookie currently used an undocumented magic value for undefined
maxAge.
Clients need to be able to identify such value so they can implement a
proper CookieJar.
Ideally, we should add a `Cookie::isMaxAgeDefined` method but I guess
we can’t add a new method without breaking API :(
Modifications:
Add a new constant on `Cookie` interface so clients can use it to
compare with value return by `Cookie.maxAge` and decide if `maxAge` was
actually defined.
Result:
Clients have a better documented way to check if the maxAge attribute
was defined.
Motivation:
We used various mocking frameworks. We should only use one...
Modifications:
Make usage of mocking framework consistent by only using Mockito.
Result:
Less dependencies and more consistent mocking usage.
Motivation:
HttpObjectAggregator yields full HTTP messgaes (AggregatedFullHttpMessages) that don't respect decoder result when copied/replaced.
Modifications:
Copy the decoding result over to a new instance produced by AggregatedFullHttpRequest.replace or AggregatedFullHttpResponse.replace .
Result:
DecoderResult is now copied over when an original AggregatedFullHttpMessage is being replaced (i.e., AggregatedFullHttpRequest.replace or AggregatedFullHttpResponse.replace is being called).
New unit tests are passing on this branch but are failing on master.
Motivation:
HttpUtil.setTransferEncodingChunked could add a second Transfer-Encoding
header if one was already present. While this is technically valid, it
does not appear to be the intent of the method.
Result:
Only one Transfer-Encoding header is present after calling this method.
Motivation:
In Netty, currently, the HttpPostRequestEncoder only supports POST, PUT, PATCH and OPTIONS, while the RFC 7231 allows with a warning that GET, HEAD, DELETE and CONNECT use a body too (but not TRACE where it is explicitely not allowed).
The RFC in chapter 4.3 says:
"A payload within a XXX request message has no defined semantics;
sending a payload body on a XXX request might cause some existing
implementations to reject the request."
where XXX can be replaced by one of GET, HEAD, DELETE or CONNECT.
Current usages, on particular in REST mode, tend to use those extra HttpMethods for such queries.
So this PR proposes to remove the current restrictions, leaving only TRACE as explicitely not supported.
Modification:
In the constructor, where the test is done, replacing all by checking only against TRACE, and adding one test to check that all methods are supported or not.
Result:
Fixes#6138.
Motivation:
cb139043f3 introduced special handling of response to HEAD requests. Due a bug we failed to handle FullHttpResponse correctly.
Modifications:
Correctly handle FullHttpResponse for HEAD requests.
Result:
Works as expected.
Motivation:
We should have a unit test which explicitly tests a HTTP message being split between multiple ByteBuf objects.
Modifications:
- Add a unit test to HttpRequestDecoderTest which splits a request between 2 ByteBuf objects
Result:
More unit test coverage for HttpObjectDecoder.
Motivation:
Enables optional .startsWith() matching of req.uri() with websocketPath.
Modifications:
New checkStartsWith boolean option with default false value added to both WebSocketServerProtocolHandler and WebSocketServerProtocolHandshakeHandler. req.uri() matching is based on this option.
Result:
By default old behavior matching via .equal() is preserved. To use checkStartsWith use constructor shortcut: new WebSocketServerProtocolHandler(websocketPath, true) or fill this flag on full form of constructor among other options.
request with a 'content-encoding: chunked' header
Motivation:
It is valid to send a response to a HEAD request that contains a transfer-encoding: chunked header, but it is not valid to include a body, and there is no way to do this using the netty4 HttpServerCodec.
The root cause is that the netty4 HttpObjectEncoder will transition to the state ST_CONTENT_CHUNK and the only way to transition back to ST_INIT is through the encodeChunkedContent method which will write the terminating length (0\r\n\r\n\r\n), a protocol error when responding to a HEAD request
Modifications:
- Keep track of the method of the request and depending on it handle the response differently when encoding it.
- Added a unit test.
Result:
Correclty handle HEAD responses that are chunked.
Motivation:
According to https://www.ietf.org/rfc/rfc2388.txt 4.4, filename after "content-disposition" is optional and arbitrary (does not need to match a real filename).
Modifications:
This change supports an extra addBodyFileUpload overload to precise the filename (default to File.getName). If empty or null this argument should be ignored during encoding.
Result:
- A backward-compatible addBodyFileUpload(String, File, String, boolean) to use file.getName() as filename.
- A new addBodyFileUpload(String, String, File, String, boolean) overload to precise filename
- Couple of tests for the empty use case
Motivation:
IntelliJ issues several warnings.
Modifications:
* `ClientCookieDecoder` and `ServerCookieDecoder`:
* `nameEnd`, `valueBegin` and `valueEnd` don't need to be initialized
* `keyValLoop` loop doesn't been to be labelled, as it's the most inner one (same thing for labelled breaks)
* Remove `if (i != headerLen)` as condition is always true
* `ClientCookieEncoder` javadoc still mention old logic
* `DefaultCookie`, `ServerCookieEncoder` and `DefaultHttpHeaders` use ternary ops that can be turned into simple boolean ones
* `DefaultHeaders` uses a for(int) loop over an array. It can be turned into a foreach one as javac doesn't allocate an iterator to iterate over arrays
* `DefaultHttp2Headers` and `AbstractByteBuf` `equal` can be turned into a single boolean statement
Result:
Cleaner code
Motivation:
* DefaultHeaders from netty-codec has some duplicated logic for header date parsing
* Several classes keep on using deprecated HttpHeaderDateFormat
Modifications:
* Move HttpHeaderDateFormatter to netty-codec and rename it into HeaderDateFormatter
* Make DefaultHeaders use HeaderDateFormatter
* Replace HttpHeaderDateFormat usage with HeaderDateFormatter
Result:
Faster and more consistent code
Motivation:
code assumes a numeric value of 0 means no digits were read between separators, which fails for timestamps like 00:00:00.
also code accepts invalid timestamps like 0:0:000
Modifications:
explicitly check for number of digits between separators instead of relying on the numeric value.
also add tests.
Result:
timestamps with 00 successfully parse, timestamps with 000 no longer
Signed-off-by: radai-rosenblatt <radai.rosenblatt@gmail.com>
Motivation:
The method HttpUtil.getCharsetAsString(...) is missleading as its return type is CharSequence and not String.
Modifications:
Deprecate HttpUtil.getCharsetAsString(...) and introduce HttpUtil.getCharsetAsSe
quence(...).
Result:
Less confusing method name.
Motivation:
* RFC6265 defines its own parser which is different from RFC1123 (it accepts RFC1123 format but also other ones). Basically, it's very lax on delimiters, ignores day of week and timezone. Currently, ClientCookieDecoder uses HttpHeaderDateFormat underneath, and can't parse valid cookies such as Github ones whose expires attribute looks like "Sun, 27 Nov 2016 19:37:15 -0000"
* ServerSideCookieEncoder currently uses HttpHeaderDateFormat underneath for formatting expires field, and it's slow.
Modifications:
* Introduce HttpHeaderDateFormatter that correctly implement RFC6265
* Use HttpHeaderDateFormatter in ClientCookieDecoder and ServerCookieEncoder
* Deprecate HttpHeaderDateFormat
Result:
* Proper RFC6265 dates support
* Faster ServerCookieEncoder and ClientCookieDecoder
* Faster tool for handling headers such as "Expires" and "Date"
Motiviation:
We used ReferenceCountUtil.releaseLater(...) in our tests which simplifies a bit the releasing of ReferenceCounted objects. The problem with this is that while it simplifies stuff it increase memory usage a lot as memory may not be freed up in a timely manner.
Modifications:
- Deprecate releaseLater(...)
- Remove usage of releaseLater(...) in tests.
Result:
Less memory needed to build netty while running the tests.
Motivation:
If the wsURL contains an encoded query, it will be decoded when generating the raw path. For example if the wsURL is http://test.org/path?a=1%3A5, the returned raw path would be /path?a=1:5
Modifications:
Use wsURL.getRawQuery() rather than wsURL.getQuery()
Result:
rawPath will now return /path?a=1%3A5
Motivation:
Some commons values are missing from HttpHeader values constants.
Modifications:
- Add constants for "application/json" Content-Type
- Add constants for "gzip,deflate" Content-Encoding
Result:
More HttpHeader values constants available, both in
`HttpHeaders.Values` and `HttpHeaderValues`.
Motivation:
The HttpObjectAggregator never appends a 'Connection: close' header to
the response of oversized messages even though in the majority of cases
its going to close the connection.
Modification:
This PR addresses that by ensuring the requisite header is present when
the connection is going to be closed.
Result:
Gracefully signal that we are about to close the connection.
Motivation:
We need to ensure we not add the Transfer-Encoding header if the HttpMessage is EOF terminated.
Modifications:
Only add the Transfer-Encoding header if an Content-Length header is present.
Result:
Correctly handle HttpMessage that is EOF terminated.
Motivation:
We want to reject the upgrade as quickly as possible, so that we can
support streamed responses.
Modifications:
Reject the upgrade as soon as we inspect the headers if they're wrong,
instead of waiting for the entire response body.
Result:
If a remote server doesn't know how to use the http upgrade and tries to
responsd with a streaming response that never ends, the client doesn't
buffer forever, but can instead pass it along. Fixes#5954
Motivation:
the build doesnt seem to enforce this, so they piled up
Modifications:
removed unused import lines
Result:
less unused imports
Signed-off-by: radai-rosenblatt <radai.rosenblatt@gmail.com>
Motivation:
The Javadocs of HttpUtil.getContentLength(HttpMessage, long) and its int overload state that the provided default value is returned if the Content-Length value is not a number. NumberFormatException is thrown instead.
Modifications:
Correctly handle when the value is not a number.
Result:
API works as stated in javadocs.
Motivation:
HttpObjectDecoder maintains a resetRequested flag which is used to determine if internal state should be reset when a decode occurs. However after a reset is done the resetRequested flag is not set to false. This leads to all data after this point being discarded.
Modifications:
- Set resetRequested to false when a reset is done
Result:
HttpObjectDecoder can still function after a reset.
Motivation:
As discussed in #5738, developers need to concern themselves with setting
connection: keep-alive on the response as well as whether to close a
connection or not after writing a response. This leads to special keep-alive
handling logic in many different places. The purpose of the HttpServerKeepAliveHandler
is to allow developers to add this handler to their pipeline and therefore
free themselves of having to worry about the details of how Keep-Alive works.
Modifications:
Added HttpServerKeepAliveHandler to the io.netty.handler.codec.http package.
Result:
Developers can start using HttpServerKeepAliveHandler in their pipeline instead
of worrying about when to close a connection for keep-alive.
Motivation:
As described in #5734
Before this change, if the server had to do some sort of setup after a
handshake was completed based on handshake's information, the only way
available was to wait (in a separate thread) for the handshaker to be
added as an attribute to the channel. Too much hassle.
Modifications:
Handshake completed event need to be stateful now, so I've added a tiny
class holding just the HTTP upgrade request and the selected subprotocol
which is fired as an event after the handshake has finished.
I've also deprecated the old enum used as stateless event and I left the
code that fires it for backward compatibility. It should be removed in
the next mayor release.
Result:
It should be much simpler now to do initialization stuff based on
subprotocol or request headers on handshake completion. No asynchronous
waiting needed anymore.
Motivation:
The CorsHandler currently closes the channel when it responds to a preflight (OPTIONS)
request or in the event of a short circuit due to failed validation.
Especially in an environment where there's a proxy in front of the service this causes
unnecessary connection churn.
Modifications:
CorsHandler now uses HttpUtil to determine if the connection should be closed
after responding and to set the Connection header on the response.
Result:
Channel will stay open when the CorsHandler responds unless the client specifies otherwise
or the protocol version is HTTP/1.0
Motivation:
Documentation was added in #2401 to aid developers in understanding
how HttpObjectAggregator works and that it needs an encoder before it.
In #2471 it was pointed out that the documentation added can actually
add to the confusion and that it might have a typo.
This is an attempt at clearing up that confusion. Feedback is welcome.
Modifications:
- Adjust class level javadoc for HttpObjectAggregator
* Remove reference to HttpRequestEncoder
* Point out when HttpResponseEncoder is needed
* Point out that either HttpRequestDecoder or HttpResponseDecoder is needed
* Make clear everything must be added before HttpObjectAggregator
* Mention HttpServerCodec
Result:
Avoid confusion about dependencies for HttpObjectAggregator on the pipeline.
Motivation:
The CorsHandler currently closes the channel when it responds to a preflight (OPTIONS)
request or in the event of a short circuit due to failed validation.
Especially in an environment where there's a proxy in front of the service this causes
unnecessary connection churn.
Modifications:
CorsHandler now uses HttpUtil to determine if the connection should be closed
after responding
Result:
Channel will stay open when the CorsHandler responds unless the client specifies otherwise
or the protocol version is HTTP/1.0
Motivation:
RFC 6265 does not state that cookie names must be case insensitive.
Modifications:
Fix io.netty.handler.codec.http.cookie.DefaultCookie#equals() method to
use case sensitive String#equals() and String#compareTo().
Result:
It is possible to parse several cookies with same names but with
different cases.
Motivation:
The CorsHandler currently returns the Access-Control-Allow-Headers
header as on a Non-Preflight CORS request (Simple request).
As per the CORS specification the Access-Control-Allow-Headers header
should only be returned on Preflight requests. (not on simple requests).
https://www.w3.org/TR/2014/REC-cors-20140116/#access-control-allow-headers-response-headerhttp://www.html5rocks.com/static/images/cors_server_flowchart.png
Modifications:
Modified CorsHandler.java to not add the Access-Control-Allow-Headers
header when responding to Non-preflight CORS request.
Result:
Access-Control-Allow-Headers header will not be returned on a Simple
request (Non-preflight CORS request).
Motivation:
There are few duplicated byte[] CRLF fields in code.
Modifications:
Removed duplicated fields as they could be inherited from parent encoder.
Result:
Less static fields.
Motivation :
Unboxing operations allocate unnecessary objects when it could be avoided.
Modifications:
Replaced Float.valueOf with Number.parseFloat where possible.
Result:
Less unnecessary objects allocations.
Motivation:
retainSlice() currently does not unwrap the ByteBuf when creating the ByteBuf wrapper. This effectivley forms a linked list of ByteBuf when it is only necessary to maintain a reference to the unwrapped ByteBuf.
Modifications:
- retainSlice() and retainDuplicate() variants should only maintain a reference to the unwrapped ByteBuf
- create new unit tests which generally verify the retainSlice() behavior
- Remove unecessary generic arguments from AbstractPooledDerivedByteBuf
- Remove unecessary int length member variable from the unpooled sliced ByteBuf implementation
- Rename the unpooled sliced/derived ByteBuf to include Unpooled in their name to be more consistent with the Pooled variants
Result:
Fixes https://github.com/netty/netty/issues/5582
Motivation:
Currently, QueryStringDecoder#path simply returns the path info as is, without decoding it as the Javadoc states.
Modifications:
* Make QueryStringDecoder#path decode the path info.
* Add tests to QueryStringDecoderTest.
Result:
QueryStringDecoder#path now decodes the path info as expected.
Motivation:
DiskFileUpload and MemoryFileUpload.equals(...) are broken.
Modifications:
Fix implementation and add unit test.
Result:
Equals method are correct now.
Motivation:
We don't have an argument named {@code value} but have {@code set} and
{@code expected} in HttpHeaders and HttpUtil respectively.
Modifications:
I replaced {@code value} to {@code set} and {@code expected} in HttpHeaders
and HttpUtil respectively.
Result:
Now javadoc says;
If {@code set} is {@code true}, the {@code "Expect: 100-continue"} header is
set and all other previous {@code "Expect"} headers are removed. Otherwise,
all {@code "Expect"} headers are removed completely. in HttpHeaders
If {@code expected} is {@code true}, the {@code "Expect: 100-continue"} header
is set and all other previous {@code "Expect"} headers are removed. Otherwise,
all {@code "Expect"} headers are removed completely. in HttpUtil
Motivation:
These methods were recently deprecated. However, they remained in use in several locations in Netty's codebase.
Modifications:
Netty's code will now access the bootstrap config to get the group or child group.
Result:
No impact on functionality.
Motivation:
We use pre-instantiated exceptions in various places for performance reasons. These exceptions don't include a stacktrace which makes it hard to know where the exception was thrown. This is especially true as we use the same exception type (for example ChannelClosedException) in different places. Setting some StackTraceElements will provide more context as to where these exceptions original and make debugging easier.
Modifications:
Set a generated StackTraceElement on these pre-instantiated exceptions which at least contains the origin class and method name. The filename and linenumber are specified as unkown (as stated in the javadocs of StackTraceElement).
Result:
Easier to find the origin of a pre-instantiated exception.
Motivation:
When HTTPS is used we should use https in the sec-websocket-origin / origin header
Modifications:
- Correctly generate the sec-websocket-origin / origin header
- Add unit tests.
Result:
Generate correct header.
`HttpContentDecoder` was removing `Content-Length` header but not adding a `Transfer-Encoding` header which goes against the HTTP spec.
Added `Transfer-Encoding` header with value `chunked` when `Content-Length` is removed.
Modified existing unit test to also check for this condition.
Compliance with HTTP spec.
Motivation:
When using HttpContentCompressor and the HttpResponse is protocol version 1.0, HttpContentEncoder.encode() should not set the transfer-encoding header to chunked. Chunked transfer-encoding is not valid for HTTP 1.0 - this causes ERR_CONTENT_DECODING_FAILED errors in chrome and similar failures in IE.
Modifications:
Skip HTTP/1.0 messages
Result:
Be able to serve HTTP/1.0 as well when HttpContentEncoder is in the pipeline.
Motivation:
Its completly fine for ChunkedInput.readChunk(...) to return null to indicate there is currently not any data to read. We need to handle this in HttpChunkedInput to not produce a NPE when constructing the HttpContent.
Modifications:
If readChunk(...) return null just return null as well.
Result:
No more NPE.
Motivation:
I cherry-picked 819b26b too soon. There were entries added to a deprecated class which should only go into the non-deprecated version of the class.
Modifications:
- Remove the static final variables that were added as duplicates to the deprecated class
Result:
Deprecated code does not grown in volume without need.
Motivation:
Some commons values are missing from HttpHeader values constants.
Modifications:
- Add constants for "application/json" Content-Type
- Add constants for "gzip,deflate" Content-Encoding
Result:
More HttpHeader values constants available, both in
`HttpHeaders.Values` and `HttpHeaderValues`.
Motivation:
Support fetches data chunk by chunk for use with WebSocket chunked transfers.
Modifications:
Create a WebSocketChunkedInput.java that add to io.netty.handler.codec.http.websocketx package
Result:
The WebSocket transfers/fetches data chunk by chunk.
Motivation:
JCTools supports both non-unsafe, unsafe versions of queues and JDK6 which allows us to shade the library in netty-common allowing it to stay "zero dependency".
Modifications:
- Remove copy paste JCTools code and shade the library (dependencies that are shaded should be removed from the <dependencies> section of the generated POM).
- Remove usage of OneTimeTask and remove it all together.
Result:
Less code to maintain and easier to update JCTools and less GC pressure as the queue implementation nt creates so much garbage
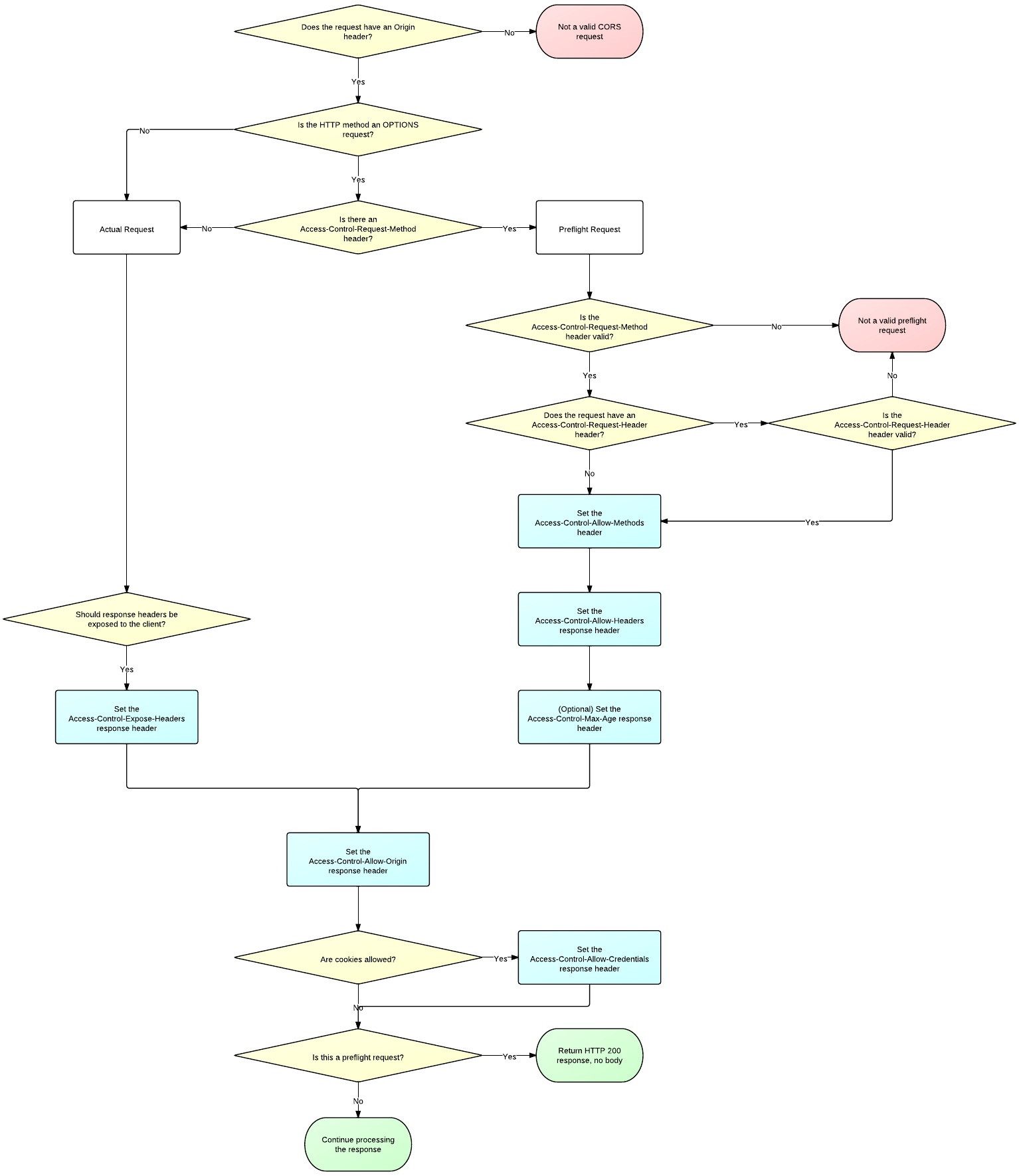{kind=link}